In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Deepak Pushpakar, Software Engineering Architect for Segmentation and Activation within Data 360. His team processes a quadrillion records per month on customer data sets spread across disparate storage systems. The complexity is significant: thousands of tables, thousands of relationships, highly variable data quality, completely custom data models, and data volumes that range from thousands to hundreds of billions of records per job.
Explore how his team maintained reliable audience segmentation despite arbitrary customer schemas and relationship graphs across Data 360, and how his team overcame the metadata scalability constraints that threatened query planning, workload execution, and platform usability at extreme scale.
What is your team’s mission within Data 360, and how is segmentation critical to Data 360 ?
Segmentation is the holy grail of audience analytics and any kind of action, and thus the first and essential step for any action our customers want to take for their user base. It powers analytics across segment populations and enables marketing campaigns, advertising campaigns, customer journey orchestrations, reverse ETL workflows and personalization workflows. This means it is a very time sensitive and business critical component, and must be engineered accordingly.
Our mission is to make the segmentation process reliable in an environment where the team controls almost none of the variables that typically make distributed systems predictable. While most large-scale customer data platforms simplify engineering through standardized schemas, predefined relationships, and controlled workload patterns, Data 360 deliberately allows customers to do the opposite.
Customers can bring virtually any data model, relationship graph, data quality profile, and storage architecture. Some environments contain just a handful of objects, while others contain thousands of tables and relationships spanning multiple systems. The team processes a quadrillion records per month across these highly variable environments, all while remaining fully accountable for reliability, performance, and SLA commitments.
The real challenge isn’t the scale itself. Rather, every customer creates a completely different version of the scaling problem, and the platform has to make all of them work reliably.
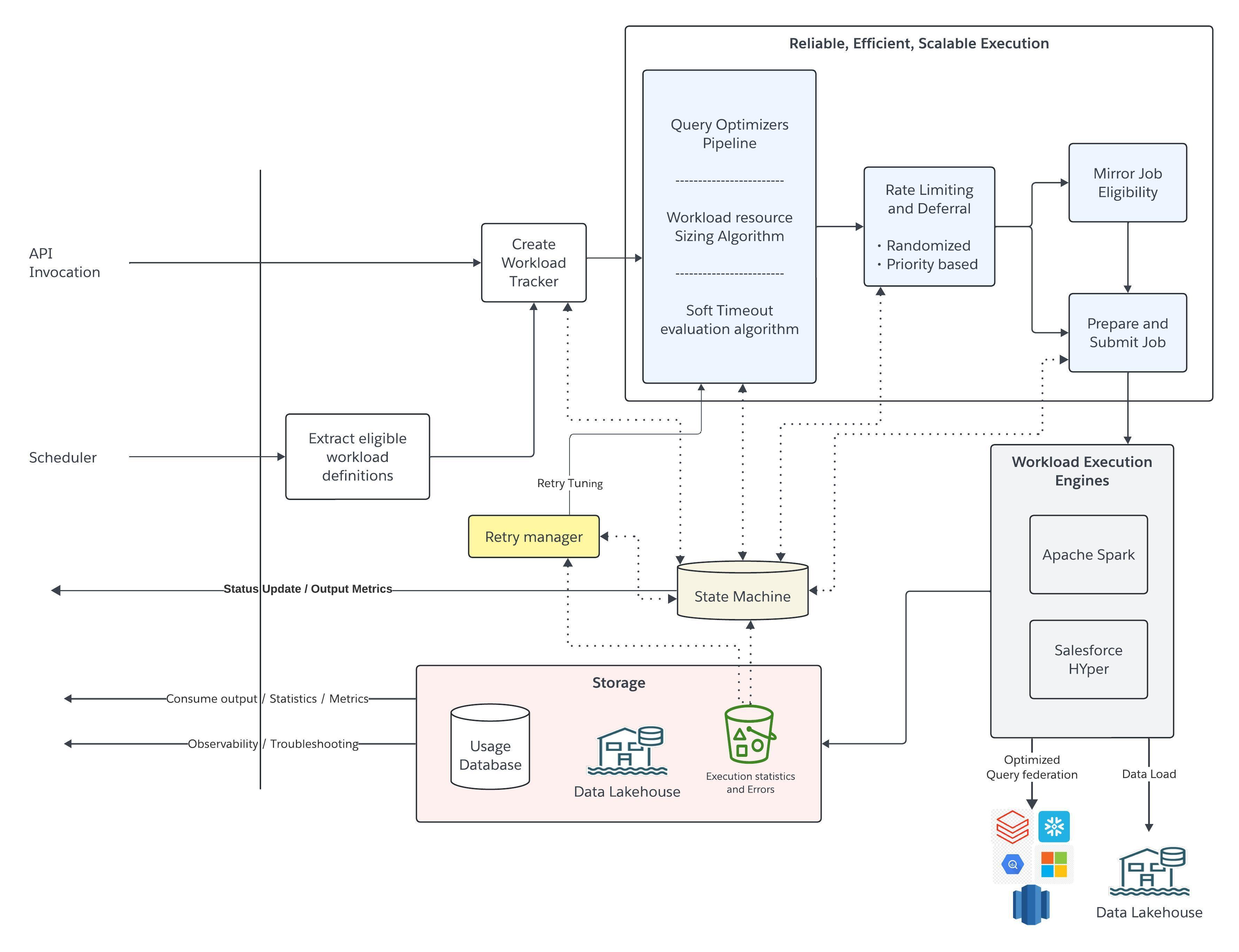
A look at the components which ensure resilience for Data 360 segmentation engine workloads.
What makes audience segmentation difficult when every customer brings a different data model into Data 360?
Most large-scale data platforms rely on predefined assumptions about how data should be structured. Data 360 removes many of those assumptions, allowing customers to define their own schemas, relationships, hierarchies, and modeling patterns.
While one customer might operate with a relatively simple model, another can introduce thousands of objects, deeply connected relationship graphs, and highly customized schemas. Even within a single organization, multiple data spaces can contain entirely different data models that must be supported by the same execution engine.
Because segmentation sits directly on the activation path, all marketing, advertisement, customer journey orchestrations, and personalization workflows depend on the segmentation platform’s ability to produce reliable results, regardless of how customers choose to model or store their data. The team addresses this through a segmentation engine that dynamically interprets customer-defined relationships, hierarchies, and object structures at runtime rather than forcing customers into predefined schemas. This allows the platform to support highly customized environments while maintaining a consistent execution model across Data 360.
What engineering constraints emerge when processing a quadrillion records per month across millions of Spark workloads?
Processing a quadrillion records per month means supporting an enormous spectrum of workload sizes. Every month, the platform executes roughly three million Spark jobs, ranging from just 10,000 records to more than 100 billion records in a single run. On the other hand, most customers bring datasets which are highly normalized, making analytics workloads like segmentation more complex for large data sizes. The real trick is allocating the right resources to each workload based on data volume and job complexity without overprovisioning infrastructure or introducing reliability risks.
Customers can also choose to keep their data inside Salesforce or execute portions of their workloads across external systems like Snowflake, Databricks, Google BigQuery, and Microsoft Fabric using the Data 360 Zero Copy Framework. Even when portions of the execution path depend on systems the team doesn’t control, the team remains fully accountable for reliability and SLA commitments.
To operate reliably at this scale, the team has built:
- Intelligent workload size estimation to right-size jobs before they run
- SLA-aware retry mechanisms to maintain reliability under failure conditions
- Rate limiting to protect downstream systems
- Adaptive compute resource allocation that optimizes infrastructure usage dynamically
- Production telemetry and monitoring/alerting for real-time operational visibility
- Extensive production mirroring to validate changes safely before full deployment
Because customer environments vary too dramatically for lower environments to accurately mimic production behavior, major features, performance optimizations, and infrastructure changes are always validated against real production workloads before rollout.
What architectural decisions enabled the platform to maintain high reliability while balancing infrastructure cost at extreme scale?
Reliability and cost naturally pull in opposite directions. While allocating more resources improves reliability, it quickly becomes inefficient when workloads vary so dramatically across different customers.
The team addresses this through job-size estimation, intelligent resource allocation, rate limiting, and retry mechanisms. These tools help maintain approximately 99.95% reliability without excessive compute resource consumption.
Observability is equally important. Continuous monitoring of workload execution patterns and operational signals allows the team to identify emerging issues before they ever impact customers. Ultimately, maintaining reliability at scale requires workload intelligence and orchestration rather than simply adding more hardware.
Alerting is another critical piece of how we operate. Our systems monitor success rates and end-to-end runtimes at the customer, regional, and global level. Alerts fire when we hit at least 5 failures within a 10-minute window, which means we catch problems fast, whether they’re caused by external factors, infrastructure issues, or regressions. And before anything reaches production, every deployment payload goes through extensive performance test suites and rollback validation, so gaps and bugs don’t make it through.
What failure modes emerged as customer data quality, skew, and workload variability increased?
Many of the most difficult operational problems actually originate from customer data rather than platform infrastructure. Issues like poor data quality, duplicated records, skewed distributions, and modeling inconsistencies often remain hidden at smaller scales, but they quickly turn into significant execution challenges as workload volume grows. Common performance issues include:
- Dataset skewness: Complex jobs quickly outgrow Apache Spark’s built-in skew handling, requiring more advanced mitigation strategies
- Cartesian explosion: Data duplication and suboptimal join keys cause uncontrolled row multiplication, degrading job performance
- Suboptimal partitioning: Poorly defined partition specs lead to uneven workload distribution and inefficient resource utilization
In early iterations, workload estimation models could occasionally misjudge execution requirements, leading to memory pressure, inefficient resource utilization, execution failures on one side, and higher compute costs / resource contention on the other extreme. Without careful management of execution patterns, customers could inadvertently impact workloads of other customers, and even jobs belonging to the same customer would often compete for resources.
To address these challenges, the team invested heavily in optimizing the execution strategies, observability, operational controls, and feedback mechanisms that identify problematic patterns before they ever become large-scale runtime failures. The team also improved retry strategies, resource management, and customer guidance around modeling decisions so issues can be detected and corrected much earlier in the lifecycle. Ultimately, the goal isn’t to eliminate variability entirely, but to ensure that variability never becomes a reliability problem.
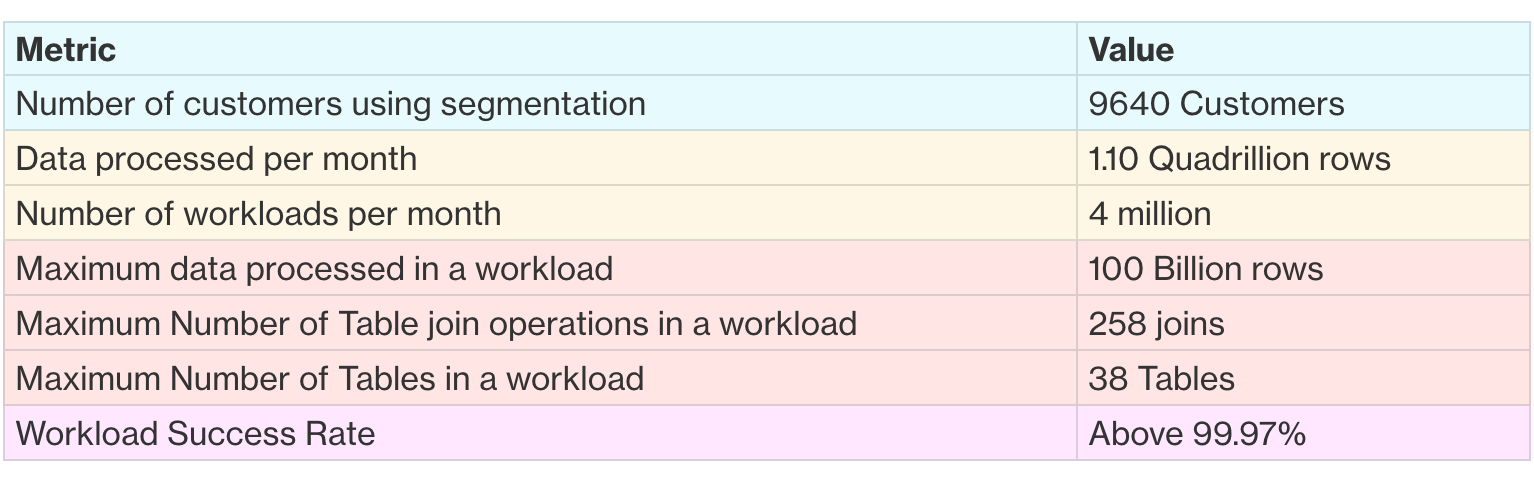
The numbers that define Data 360 segmentation’s scale and complexity.
What challenges did thousands of tables and relationships create for metadata scalability, query planning, and workload execution?
Metadata scalability became one of the most technically challenging problems the team faced, with complexity surfacing simultaneously across the experience, query-planning, and execution layers. This was especially true for customers who introduced environments containing 3,000 to 6,000 tablesand thousands of relationships.
These massive relationship graphs generated metadata payloads exceeding 500 MB, making it incredibly difficult for users to load and navigate segmentation interfaces, where they interact with the entire data model to build segmentation logic. To solve this, the team introduced relationship guardrails and optimized metadata serialization and loading, which dramatically reduced payload sizes and improved overall usability.
Query planning became an even larger hurdle. As relationship complexity grew, the number of potential execution paths exploded. In some cases, query planners had to evaluate millions or even billions of possible plans just to determine the optimal execution strategy, making the planning phase itself the primary bottleneck.
The team addressed this by introducing phased query planning. Instead of trying to optimize an entire workload all at once, the system breaks planning down into smaller stages that can be optimized independently. While this significantly reduces planning complexity, it does introduce an important tradeoff: optimizing individual phases might not always produce the globally optimal plan. Because of this, phased planning is applied selectively, only when complexity thresholds indicate that traditional planning approaches are likely to fail.
The team continues to refine query generation and execution strategies, ensuring workloads remain highly performant even as metadata, relationship complexity, and object counts continue to grow.
As Data 360 continues to scale, what remains hardest about maintaining reliability, observability, and workload orchestration?
As customer adoption, workload diversity, and platform scale continue to grow, the hardest challenges naturally evolve. Today, the platform supports approximately 100,000 Spark jobs per day. At that kind of scale, even a tiny failure rate can generate more operational signals than humans can realistically investigate, making traditional manual analysis increasingly difficult to sustain.
To stay ahead of this complexity, the team is investing in observability, proactive analytics, and automated troubleshooting systems that can identify issues before customers ever experience them. The long-term goal is to reduce the manual investigation required to run the platform, allowing engineers to focus on novel problems rather than repeatedly diagnosing known failure patterns.
Ultimately, the real challenge isn’t just processing a quadrillion records per month. The challenge is continuing to do so reliably as customer environments grow more complex and every customer creates a different version of the scaling problem. Meeting that challenge will require increasingly intelligent automation across planning, execution, and operations.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.