In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Raveendrnathan Loganathan, Executive Vice President of Software Engineering, who is transforming Data Cloud into the real-time, trusted backbone of Salesforce’s AI-driven applications and experiences.
Explore how Ravi’s team scaled metadata activation to hyperscale, developed real-time systems for agent-first AI experiences like Agentforce, and reimagined ingestion and governance to support distributed, enterprise-grade AI.
What is your team’s mission?
Our team empowers every Salesforce customer to create intelligent, real-time personalized experiences by providing a trusted, harmonized, and unified view of data. The goal is to transform organizations into information-rich powerhouses, turning raw data into insightful and actionable intelligence. This intelligence drives magical customer experiences at every touchpoint, from targeted marketing campaigns to agents resolving issues quickly and contextually, thanks to tools like Agentforce.
In support of that, the team is building Data Cloud, a foundation that unlocks the true potential of information. The focus is on creating a dynamic, decision-ready platform that goes beyond scalable storage and real-time activation. Every data point fuels smarter AI and hyper-personalized journeys, fostering deeper, more meaningful customer relationships. The aim is to enable the next wave of customer engagement, making complex tasks simple and turning the impossible into reality, all to deliver that coveted magical experience for customers and empower teams.

A look at Agentforce.
As Data Cloud scaled toward 100,000 tenants and 100,000 entities per tenant, what were the hardest architectural challenges faced?
The most significant architectural challenge was not the sheer volume of customer data, but the management and activation of metadata. As the customer base and data footprints grew exponentially, so did the volume and interconnected complexity of this essential information, which provides context and meaning to raw data. Initially, the approach involved keeping substantial portions of metadata in memory for performance, but this quickly became unsustainable and cost-prohibitive at scale.
The challenge intensified with the introduction of Data Cloud One, which brings together multiple Salesforce instances within an organization, enabling seamless metadata sharing. The critical issue was the increasing demand for real-time experiences, which required this vast web of metadata to be activated on-demand, within milliseconds, for everything from snappy user experiences to consistent background workloads.
Why did scaling metadata become the critical bottleneck for Data Cloud — and what architectural shifts were required to solve it?
Metadata is central to every Data Cloud operation. Immediate and accurate access to metadata is crucial for ingesting new data, executing queries, powering real-time segmentation, and informing intelligent agent actions. With 100,000 tenants and 100,000 entities per tenant, the volume of interconnected metadata objects grew exponentially, making the in-memory approach inadequate. This pre-loaded model struggled to meet the dynamic activation patterns needed for real-time user experiences and background processes.
To address this, the team shifted to treating metadata as a first-class, dynamic entity. This led to an on-demand activation model, where metadata is materialized only when and where needed across the Salesforce stack. Key changes included:
- Optimized Activation Pathways: New algorithms in Attribute Library Management efficiently retrieve and activate specific metadata on demand.
- Decoupling Control and Execution: The control plane of metadata at design time in Salesforce Core was separated from runtime data processing in Data Cloud, enhancing scalability and resilience.
- Domain-Centric Organization: Metadata was organized into logical, domain-specific collections to reduce activation scope and enhance isolation via Data Spaces.
This transition, guided by the principle of “Treat Meta as Data,” was crucial for unlocking the scalability and performance needed to support Data Cloud’s growth and real-time user expectations.
When real-time AI and agent-first experiences like Agentforce became the new standard, what technical gaps did Data Cloud have to close to meet enterprise expectations?
The advent of real-time AI and agent-first experiences, like Agentforce, challenged the conventional approach of treating structured and unstructured data separately. Intelligent agents and AI workflows require a unified, low-latency view of all relevant information, regardless of format or location, whether in Data Cloud or accessed via zero-copy partners. The traditional separation between structured queries and unstructured data retrieval created significant friction and latency, hindering real-time intelligence.
To address this, Data Cloud SQL was integrated as a state-of-the-art unified query layer. This layer orchestrates and optimizes queries that combine the precision of structured SQL with the semantic understanding of vector embeddings and the recall of keyword searches. This capability extends beyond Data Cloud, allowing efficient querying across data managed by zero-copy partners.
With Data Cloud SQL, an agent-facing application can execute a single query to retrieve a customer’s CRM record (structured data in Data Cloud), recent order history from Snowflake (accessed via zero copy), and relevant passages from a support document (unstructured data in Data Cloud, accessed via vector search) with millisecond-level latency. This seamless blending of different query types across disparate data sources provides unprecedented context and speed for intelligent applications, making it a key differentiator for modern enterprise AI and agent-first strategies.

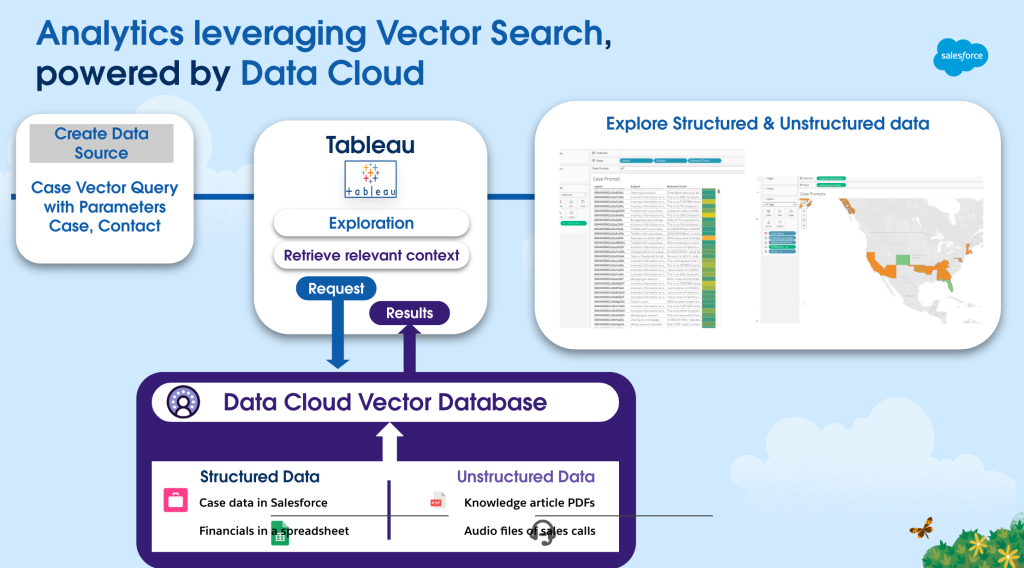
Examining Data Cloud’s reference architecture.
Grounding generative AI in enterprise truth is notoriously difficult at scale. What made it so challenging inside Data Cloud?
The challenge of grounding generative AI in diverse enterprise data at scale is common. This data spans structured records, unstructured documents, and various formats, often residing in disparate systems. To leverage generative AI for accurate and contextually relevant responses, a unified approach to indexing and reasoning over this data is needed, while maintaining security and governance.
Data Cloud addresses this with a comprehensive architecture. A semantic retrieval layer bridges structured and unstructured data with robust access controls. Data ingestion and indexing processes capture both content and semantic meaning.
To retrieve relevant information, Data Cloud uses a hybrid retrieval framework, combining semantic similarity search with keyword-based matching. Dynamic Data Graphs are a key part of the grounding strategy, creating a comprehensive Customer 360 Profile. This profile consolidates core customer data, insights, past engagements, and predictive scores, and is updated in real time.
The Customer 360 Profile can be accessed with millisecond latency and delivered in an LLM-friendly JSON format. This ensures that Large Language Models have structured, easily digestible information to ground responses effectively. This dynamic knowledge graph enables generative AI to provide more accurate, personalized, and insightful interactions.
As Data Cloud integrates with more systems and external storage ecosystems, what were the toughest ingestion and harmonization challenges to solve?
The integration of Data Cloud with an expanding ecosystem marks a significant shift in data management. The main challenge is balancing seamless data fluidity with robust control. Traditionally, data platforms required ingesting copies into a centralized repository, leading to complex ETL processes.

The Zero Copy framework enables near real-time data and metadata synchronization, making changes in Salesforce available in partner data warehouses like Snowflake in about 60 seconds, without costly duplication. Data Federation provides seamless, on-demand access to data in platforms like Redshift or BigQuery directly within Salesforce. File Federation offers high-throughput, full-fidelity access to data in lakehouses like Databricks or a customer’s own S3.
The true value lies in harmonizing data. Data Cloud’s harmonization capabilities unify disparate data, such as real-time web orders with delayed in-store purchase data from Snowflake. Over 1,000 domain-specific, out-of-the-box models empower business users to drive sophisticated workloads like AI-driven segmentation, hyper-personalization, and cross-channel activation, all with a user-friendly experience.
Our strategic vision is to empower customers to activate data with speed and agility, regardless of its location, without complex migrations or architectural compromises. We are ushering in an era of true data fluidity, allowing organizations to leverage their existing technology investments while unlocking the full potential of their data within the Salesforce ecosystem.

Data governance at hyperscale is non-negotiable—but difficult to enforce in real-time AI architectures. How did Data Cloud rethink governance?
Data security, privacy, and governance are paramount for every customer. To manage the ever-expanding scale of new structured tables and unstructured content across the enterprise, the team developed a revolutionary, scalable, elastic, and simple attribute-based access control system. Data Cloud uses LLMs to intelligently curate tags on every entity, column, row, or piece of content from across the enterprise. This robust foundation, grounded in organizational taxonomy, supports the implementation of security and privacy policies. The policy framework seamlessly integrates with traditional Role-Based Access Control systems, reflecting the existing organizational structure. The result is a robust and easy-to-administer solution for managing data access at scale.
Real-time, scalable governance is essential not only for protecting sensitive data but also for maintaining the long-term trustworthiness of enterprise AI systems.

Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.