In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Soumya KV, Senior Director of Software Engineering at Salesforce, as she leads the team building Data 360 Clean Rooms to enable secure organization collaboration on data-driven insights while maintaining strict privacy, consent, and governance controls over underlying datasets.
Explore how her team built Data 360 Clean Rooms to enable privacy-safe data collaboration under regulatory constraints like GDPR and CCPA, designed a distributed architecture that isolates datasets during analysis, and implemented a zero-copy federation model that executes queries where data resides.
What role does your team play in developing Data 360 Clean Rooms to enable secure data collaboration across organizations?
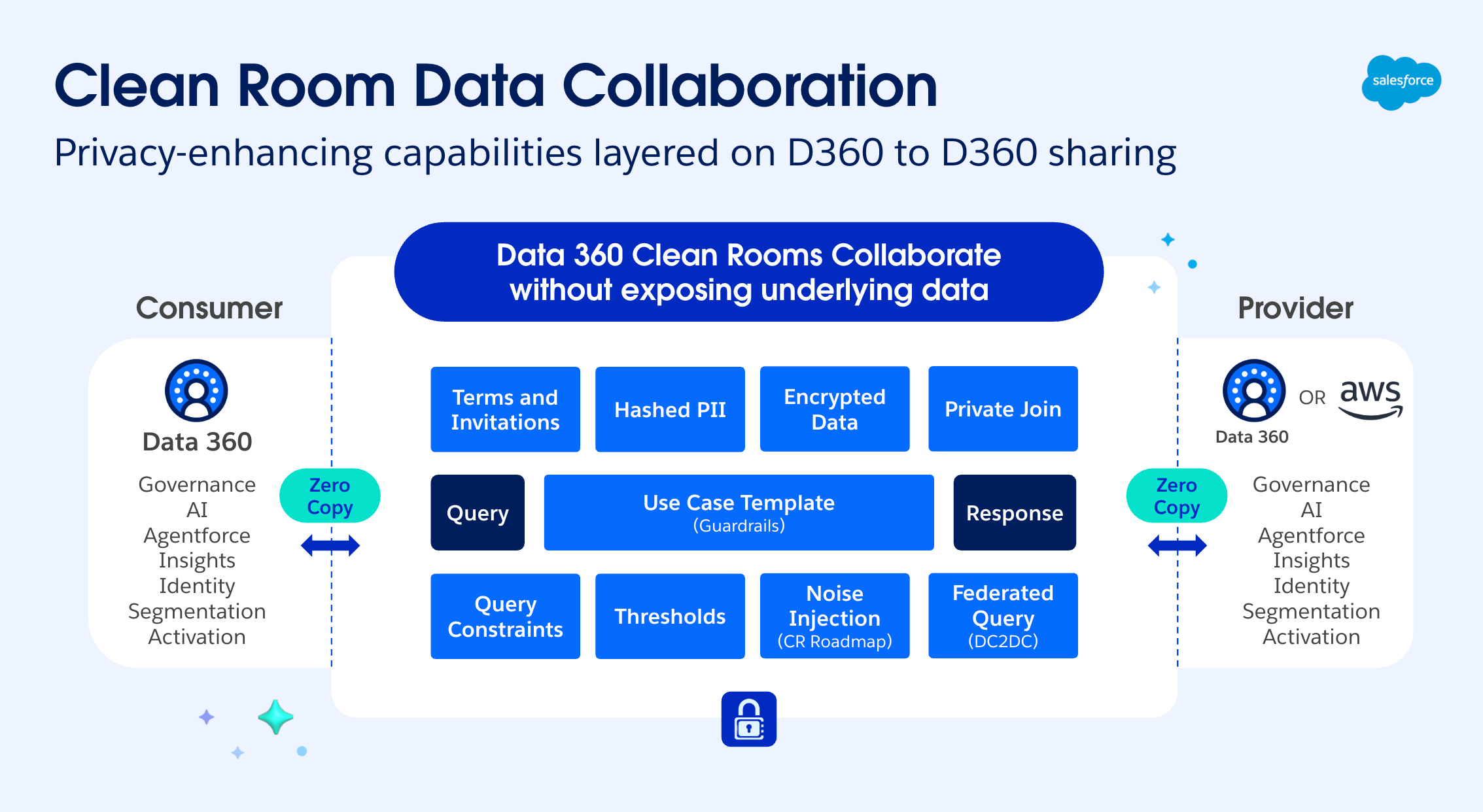
Our team designs and builds the core architecture powering Data 360 Clean Rooms, which serves as a secure collaboration layer for cross-organization data sharing. We focus on developing a privacy-first architecture that enables data isolation and zero-copy federation, ensuring sensitive PII never leaves its source environment. These capabilities allow organizations to generate shared insights without ever exposing raw data.
Moving into the framework itself, we build the governance controls and query execution capabilities that allow providers and consumers to analyze shared audiences. This structure enforces strict privacy and compliance requirements throughout the process. To support this model, the platform includes several key capabilities:
- Use case templates that restrict analysis to approved SQL patterns
- Granular data controls, including the ability to revoke access by exiting a collaboration
- Immutable audit logs accessible to both providers and consumers
These controls ensure that every collaboration remains secure, auditable, and governed. Ultimately, this allows organizations to unlock value from data partnerships without exposing sensitive information.
What privacy and regulatory requirements shaped the architecture of Data 360 Clean Rooms when enabling organizations to collaborate without sharing raw identities?
Privacy and regulatory compliance serve as foundational design constraints for this architecture. Any platform enabling collaboration on customer data operates within strict frameworks like GDPR and CCPA. To meet these requirements, Data 360 Clean Rooms include multiple layers of protection:
- Anonymization and hashing of PII like emails and phone numbers before any query execution
- Aggregation thresholds to ensure results return only for sufficiently large groups
- Query limits and frequency capping to prevent repeated probing of sensitive datasets
- Use case templates that restrict analysis to pre-approved query patterns
These safeguards prevent identity exposure and inference while enabling meaningful analysis across datasets. By enforcing these controls at query time, the system ensures that collaboration remains compliant and maintains trust between participating organizations.
What integration challenges did the team face enabling clean rooms to collaborate with external platforms like AWS Clean Rooms?
Connecting Data 360 Clean Rooms with external platforms like AWS Clean Rooms involves bridging distinct architectural frameworks. While Data 360 utilizes zero-copy federation, AWS Clean Rooms operates through specific components:
- Amazon Athena manages query execution.
- AWS Glue organizes metadata.
These variations create hurdles for metadata alignment and data-sharing processes. Establishing interoperability involves creating uniform contracts for schema mapping and query templates across both systems. To solve this, our team developed a secure integration layer that facilitates collaboration while maintaining privacy standards. This layer includes protocols for sharing metadata and coordinating queries between environments.
The system also uses a controlled retrieval process to move aggregated insights back into Data 360 for reporting and activation. This strategy enables organizations to work across different ecosystems while keeping governance and privacy rules intact.
What architectural challenges did the team face implementing a zero-copy federation model inside clean rooms so queries run where the data resides instead of moving data between systems?
Building a zero-copy federation model involves a complete redesign of query execution across distributed landscapes. In our implementation of Native Salesforce Data 360 Clean Rooms, we engineered a distributed query execution framework.
This ensures that provider-side operations are isolated within the provider’s security context, while consumer-side logic executes strictly within the consumer’s environment, maintaining end-to-end data integrity without physical movement. Every participant handles their segment of the query locally under their own governance rules.
This distributed model keeps raw data at its original source. The process only allows aggregated and anonymized results to move across the collaboration boundary. The system applies privacy controls during the query process to verify that all calculations follow established policies. These safeguards include:
- Validating the structure of every query.
- Applying governance-driven thresholds.
- Restricting access to approved attributes.
This architecture maintains data ownership and removes the risks of data migration. It allows for secure collaboration across separate systems.
What scalability challenges shaped the architecture of clean rooms supporting one provider collaborating with many consumers simultaneously?
The primary challenge was balancing resource efficiency with strict multi-tenant isolation. Supporting one provider across many consumers created a risk of interference and data leakage.
We addressed this by architecting a decoupled control plane where metadata and privacy policies are synchronized globally, while execution is partitioned into unique collaboration contexts. This allowed us to achieve 1:N scalability, reusing the same underlying data assets across multiple partnerships without physical duplication while ensuring that a breach or policy change in one collaboration had zero impact on another. This system enables:
- One-to-many relationships between providers and consumers.
- Concurrent query execution across multiple collaborations.
- Independent governance policies for every collaboration.
- Consistent metadata synchronization across all contexts.
The system also uses mechanisms to push updates for dataset mappings and privacy policies across all active collaborations. By designing specific collaboration contexts and dataset reuse, the system allows providers to scale secure data work across many partners while maintaining privacy.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.