In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Srini Krishnamoorthy, Vice President of Engineering for Data 360. Srini leads the evolution of Zero Copy across Data 360 and Agentforce.
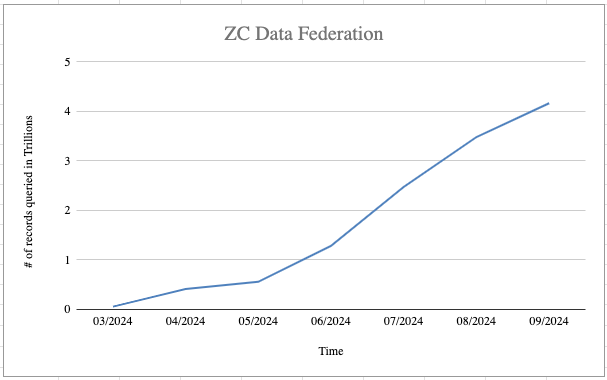
Zero Copy was originally designed to eliminate data movement. Then customers began using it to power AI workloads across increasingly large volumes of distributed enterprise data. What started as a data access problem quickly became a distributed systems problem, forcing the team to rethink the architecture behind Query Federation as adoption accelerated from less than 1 trillion rows per month to approximately 120 trillion rows monthly.
Explore how the team evolved Zero Copy from a Query Federation architecture into a File Federation architecture capable of supporting AI at petabyte scale without requiring customers to centralize their data.
What is your team’s mission as Zero Copy evolves from eliminating data movement to enabling AI at petabyte scale?
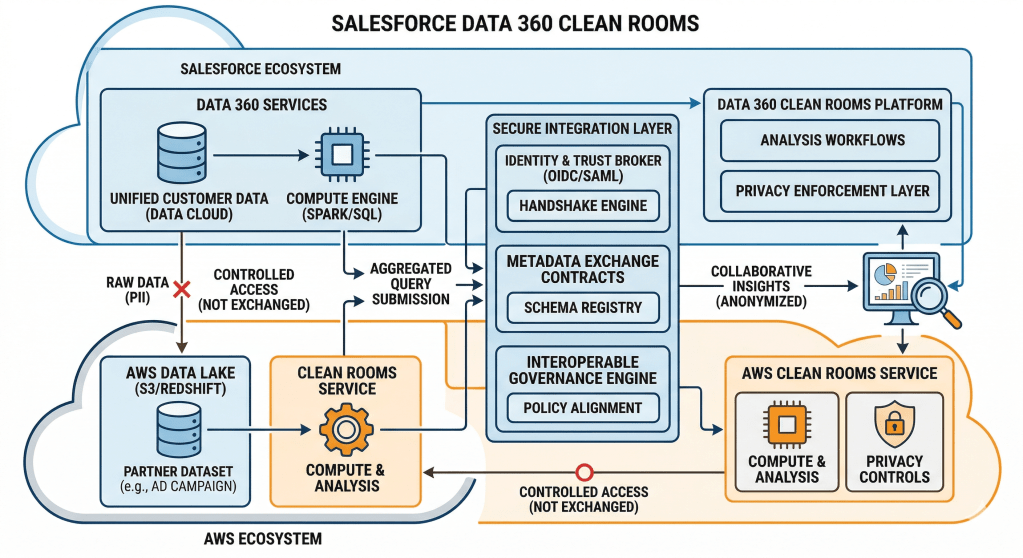
The mission is to help customers generate insights and power AI workloads across enterprise data without forcing them to move that data into a centralized platform. Data 360 needs to work with information that already exists across systems like Snowflake, Databricks, BigQuery, Amazon Redshift, and other enterprise platforms, while allowing customers to maintain full control over where that data lives.
Enterprise data rarely exists in a single place. It spans warehouses, lake houses, operational databases, and business applications, each with its own storage architecture, governance model, and performance characteristics. Yet customers still expect AI systems to reason across all of those datasets as if they existed in one location. Achieving that without introducing excessive latency, governance risk, duplication, or operational complexity is significantly harder than it sounds.
The obvious solution, moving everything into one place, breaks down quickly at petabyte scale. That kind of data movement introduces cost, latency, governance complexity, and operational overhead that simply doesn’t hold up in practice.
Eliminating data movement was the straightforward part. Enabling AI at petabyte scale when the data stays distributed across systems the team doesn’t control is a fundamentally different problem.
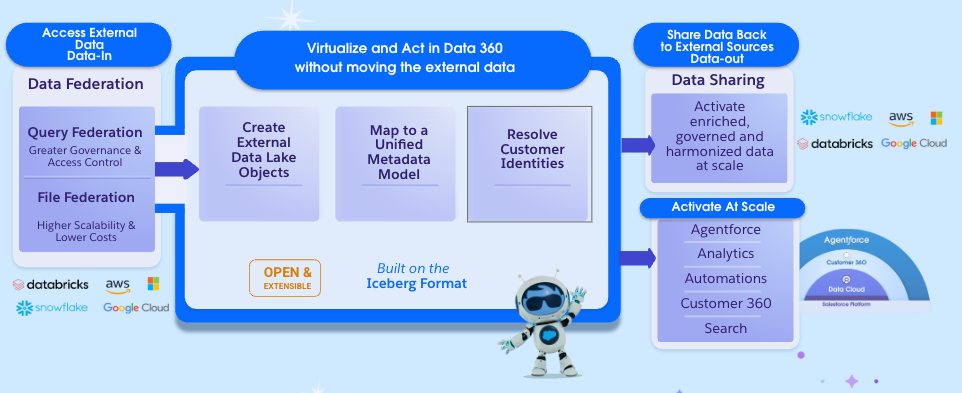
A look at Zero Copy.
How did Query Federation become the bottleneck as Zero Copy scaled?
Query Federation solved the original data movement problem by allowing Data 360 to query remote warehouses without ingesting the underlying data. The challenge emerged when customers began using it for larger analytics and AI workloads.
A useful analogy is two oceans connected by a narrow pipeline. One ocean represents Data 360 and the other represents platforms like Snowflake or Databricks. Query Federation allowed data to flow between those environments, but the architecture was ultimately limited by how much information could move through that connection at any given time.
Every request depended on compute resources running on both sides of the connection. Data 360 generated the query, the remote warehouse executed it, and results traveled back across the network. As workload sizes grew, throughput limitations, latency, and compute costs became increasingly pronounced. Valuable insights also increasingly depended on combining information distributed across multiple systems, and at larger scales the distance between compute and storage became a real architectural constraint.
In many ways, Query Federation became a victim of its own success. The limitation was no longer data access. It was how efficiently distributed systems could exchange data once customers started operating at truly massive scale.
How did File Federation remove the scaling bottlenecks inherent in Query Federation?
The breakthrough came when we stopped optimizing query execution and started optimizing around storage.
The biggest architectural shift was moving from a dual-compute model toward a single-compute model operating directly against shared storage.
Apache Iceberg became the key enabler. By standardizing around a common storage format, we could fundamentally change how Data 360 interacted with external data.
In Query Federation, compute runs in both environments. Data 360 executes part of the workflow while the remote warehouse executes the query. File Federation changes that relationship by allowing Data 360 to operate directly against the external system’s storage exposed through Apache Iceberg.
This removes much of the overhead associated with coordinating multiple compute systems while moving compute closer to the storage layer. Instead of routing execution through another warehouse’s query engine, our compute layer can directly access the underlying storage of that warehouse.
The result is a fundamentally different scaling profile. Customers retain the core Zero Copy benefit of avoiding data movement while gaining access to significantly larger data volumes and enabling AI at petabyte scale. The lesson is that data federation becomes far more scalable when systems align around a common storage abstraction instead of relying exclusively on cross-platform query execution.
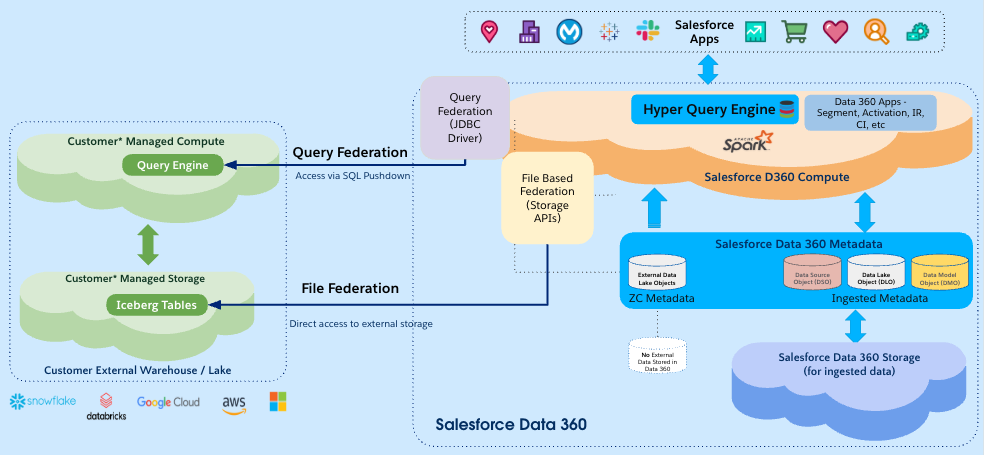
Overview of Zero Copy Data Federation.
What challenges emerged while establishing File Federation as a scalable and trusted architecture across customers and ecosystem partners?
The challenge was not simply building File Federation. The larger challenge was creating alignment across an ecosystem where every platform already had its own storage architecture, roadmap, and operational model.
Apache Iceberg provided the foundation, but interoperability still required significant effort. Because Data 360 was already built on an open and extensible foundation, we had credibility when working with partners such as Databricks and Snowflake to align around a common storage layer. Even then, Iceberg continues evolving, vendors support different versions, and catalog technologies evolve independently.
Establishing customer trust introduced another layer of complexity. Query Federation naturally relies on the remote warehouse’s governance controls because that platform executes the query. File Federation shifts more responsibility toward Data 360 because compute operates closer to storage.
To address raw storage access concern, we designed the architecture so Data 360 never requires permanent access to customer storage locations. Instead, storage access flows through the catalog layer, which provides temporary credentials for specific requests and limited periods of time.
The challenge was not choosing a protocol. The issue was creating a distributed data architecture that could scale across vendors while preserving governance, trust, and customer control.
What operational challenges emerged as Zero Copy scaled from less than 1 trillion rows to approximately 120 trillion rows per month?
Approximately two years ago, Zero Copy workloads processed less than 1 trillion rows per month. Today, Query Federation alone processes roughly 15 trillion rows monthly, while File Federation contributes enough additional volume to push total throughput to approximately 120 trillion rows per month.
At that scale, growth affects every layer of the stack simultaneously. Network infrastructure, proxy services, metadata systems, query engines, orchestration layers, memory consumption, CPU utilization, and storage access patterns all experience increased pressure. Scaling one service is never enough as every service participating in the request and processing path has to scale appropriately.
The challenge becomes even more complex because parts of the architecture exist outside Salesforce’s control. Iceberg implementations evolve. Catalog services evolve. External platforms evolve. The team must continuously validate compatibility while customers keep running production workloads. To stay ahead of that, the team relies on extensive observability, anomaly detection, end-to-end workload analysis, and large-scale performance testing designed to identify bottlenecks before customers ever encounter them. At 120 trillion rows per month, every architectural assumption is eventually tested by operational reality.
As AI workloads become increasingly dependent on distributed enterprise data, what challenges could drive the next evolution of Zero Copy?
The next major challenge is enabling real-time AI across increasingly distributed systems. When Zero Copy began, the primary focus was data access. Today, enterprise AI systems depend on much more than data alone. Agent conversations, memory systems, observability data, execution metrics, and runtime context are all increasingly distributed across multiple platforms and environments.
Customers want those systems to work together instantly. They expect AI experiences to access information from many locations while maintaining responsiveness, reliability, and consistency. That introduces a new set of architectural questions around latency, coordination, distributed state management, and data locality. At the same time, data is being generated, stored, and consumed across more systems than ever before, making data fluidity increasingly critical.
The next evolution of Zero Copy will be defined by how quickly and reliably AI systems can reason across distributed enterprise data in real time.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.
- Refer to this Linkedin article for Zero Copy architectural discussions and implementation best practices.