Salesforce uses machine learning to improve every aspect of its product suite. With the help of Salesforce Einstein, companies are improving productivity and accelerating key decision-making.
Data is a critical component of all machine learning applications and Salesforce is no exception. In this post I will share some unique challenges Salesforce has in the realm of data management and how ML Lake addresses these challenges to enable internal teams to build predictive capabilities into all Salesforce products, making every feature in Salesforce smarter and easier to use.
ML Lake enables Salesforce application developers and data scientists to easily build machine learning capabilities on customer and non-customer data. It is a shared service that provides the right data, optimizes the right access patterns, and alleviates the machine learning application developer from having to manage data pipelines, storage, security and compliance.
Multitenancy, Integration, Metadata
Before diving into ML Lake’s internals and architecture, it is important to introduce the functional and non-functional requirements that inspired us to build it. Salesforce is a cloud enterprise company that offers vertical solutions in areas such as Sales, Service and Marketing, as well as general-purpose low-code/no-code platform capabilities. There are thousands of different features of Salesforce that our customers leverage and customize to the needs of their unique business challenges.
Multitenancy has been described as the “keystone of the Salesforce architecture.” Data at Salesforce is owned by our customers and is segregated to ensure that data from one customer does not mix with another. As in most of Salesforce systems, machine learning applications requires granular access controls to ensure tenant-level data isolation. Additionally, Salesforce has grown via both acquisitions and organically, resulting in an architecture comprised on varied stacks and databases.
A key reason for building ML Lake is to make it easy for applications to get the data they need, while centralizing the security controls required for maintaining trust. Teams building applications typically underestimate the level of effort required for ETL and integration. The total cost of copying and storing data includes many hidden costs in the area of compliance, synchronization and security.
Salesforce customers have embraced the extensibility of the platform and have tailored their Salesforce systems to suit their unique business requirements. Every customer’s object model is different, and understanding this uniqueness by machine learning applications is critical for Einstein. In order to leverage this metadata and use it in conjunction with highly structured and customized data to build high-quality ML models tailored to each customer, Salesforce has developed and open-sourced TransmogrifAI, an AutoML library specifically tailored to the needs of the enterprise.
ML Lake must not only scale in total data size, but also in the number and variety of datasets it houses. A common industry practice is to carefully maintain and curate a number of key datasets for ML or analytics use cases. At Salesforce’s scale of data and customization this is impossible. Everything has to be tracked and automated, enabled by maintaining extensive metadata in ML Lake. This metadata is vital for model training and serving, as well as compliance operations.
Architecture
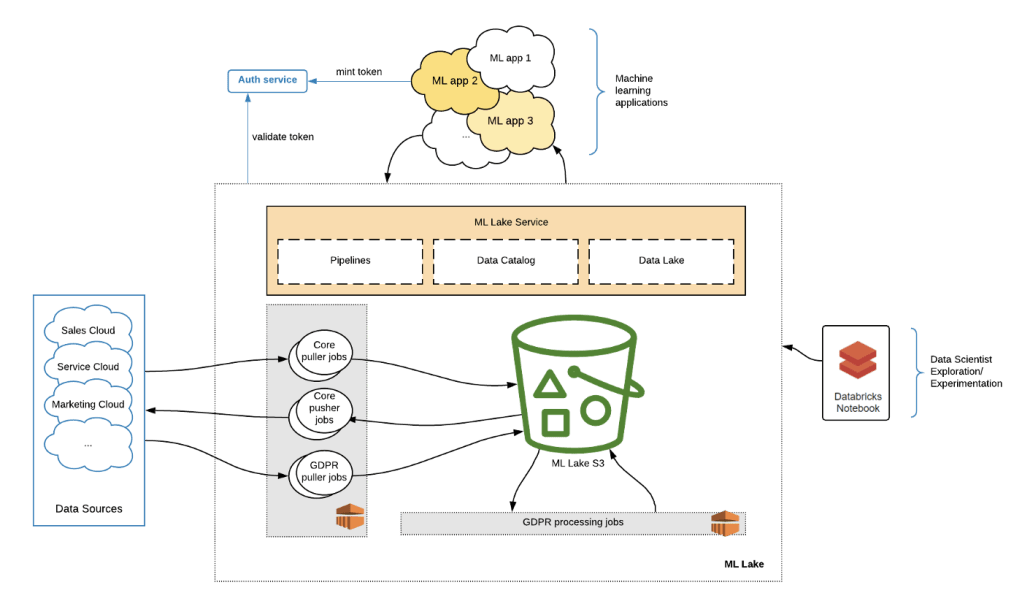
ML Lake is deployed in multiple AWS regions as a shared service for use by internal Salesforce teams and applications running in a variety of stacks in both public cloud providers and Salesforce’s own data centers. It exposes a set of OpenAPI-based interfaces running in a Spring Boot-based Java microservice. It uses Postgres to store application state and metadata. Data for machine learning is stored in S3 in buckets managed and secured by ML Lake.
Data Lake
AWS S3 was chosen as the backing store for ML Lake’s data lake for its resiliency, cost-effectiveness, and ease of integration with data processing engines. It houses datasets containing customer data from different parts of Salesforce, non-customer data, such as public datasets containing word embeddings, as well as data generated and uploaded by internal machine learning applications.
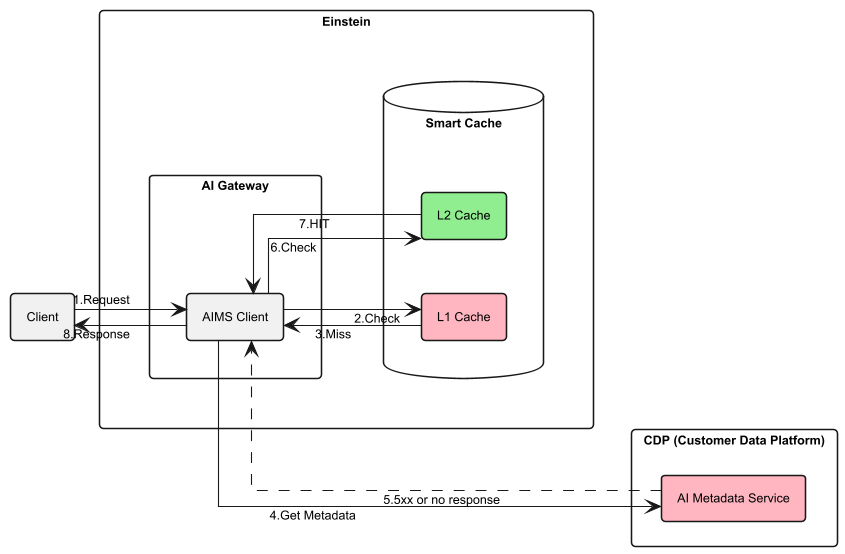
A typical flow for a machine learning application interacting with ML Lake is to request metadata for a particular dataset, which contains a pointer to an S3 path housing the data, request a granularly-scoped data access token, and interact with the actual data using S3 API or S3’s integration into common data tooling like Apache Spark or Pandas.
The majority of Salesforce data is highly structured and with schemas often customized by clients. It is important for ML Lake to support structured datasets well, allow partitioning and filtering of large datasets, and support consistent schema changes and data updates. The current de-facto standard for table formats is the Hive Metastore but it addresses only a subset of ML Lake’s needs. There are a number of exciting open source projects in this space that the ML Lake team has evaluated, eventually choosing Apache Iceberg. Iceberg is the table format for all ML Lake’s structured datasets.
Pipelines
ML Lake uses the term “pipelines” for jobs bringing data in and out of it. The pipeline capabilities provided by ML Lake are controlled via a set of APIs exposed to internal applications. The APIs control bi-directional data movement of raw feature data into ML Lake, as well predictions and related data back to customer-facing systems in Salesforce, while hiding the complexity behind a simple facade.
The pipelines service centralizes the management of data movement jobs and handles common concerns like retries, error handling and reporting. Pipeline jobs are implemented in Scala and Spark running on EMR clusters and utilize custom connectors to various parts of Salesforce, coupled with an intra-Salesforce integration auth mechanism that complies with the strict rules of granular and explicit authorization mandated by the Product Security organization.
ML Lake automatically provides GDPR compliance for data stored inside it. Compliance-related pipeline jobs continuously ingest GDPR signals, such as record deletions and do-not-profile flags, and periodically remove that data from ML Lake. Jobs that ingest these signals, as well as jobs that process data deletions, are also implemented in Scala/Spark.
Data Catalog
Data lake is a common industry approach to storing large volumes of disparate data, and allowing varied types of access to it without over-optimizing for specific access patterns up front.
Read about our engagement activities data lake built with Delta Lake.
While data lakes allow flexibility and freedom, an ungoverned data lake often becomes a “data graveyard.” For ML Lake, it is important to track and catalog the data stored inside for the following reasons:
- Compliance — ML Lake stores sensitive customer data. Each dataset is annotated with information on what customer it belongs to, the date it was ingested, its lineage, specific metadata to capture info for automatic GDPR processing, TTL, and many more attributes that are key to keeping data organized and compliant.
- Model quality and explainability — A flexible metadata model at both the dataset and field level enables datasets to be annotated with lineage information not present in the data or data schema itself. Examples of this metadata include information about which Salesforce object a dataset represents and whether a string field originated as a Text or Email field in that object. Knowing that a field is an email address and not a simple text field carries additional information useful to improving model quality. This information is also used to provide record insights to customers.
ML Lake has built a custom data catalog service to store and surface this granular metadata to both ML applications using ML Lake and to internal pipelines. Catalog capabilities are integrated with both pipelines and data lake operations into a single set of APIs for machine learning applications to leverage.
Next Steps
What are we working on now? We are hardly done on the journey of providing the best-of-breed data platform for machine learning. Here are some highlights of what we are working on now:
- Feature Store — Exciting innovation is happening in the industry in the area of feature stores. Feature stores enable the sharing and discoverability of machine learning features across different applications. Online feature stores are designed to support low-latency access to features for time-sensitive inference operations. While this is an emerging area in the industry, there are already both commercial and open-source offerings at various stages of maturity.
- Transformation Service — The goal of ML Lake is to simplify the data needs of machine learning applications at Salesforce. While for many applications having the full power of a data engine like Spark is required, for others, a more streamlined, declarative approach would suffice. ML Lake is adding declarative transformation capabilities to its suite of APIs to simplify ML applications further, accelerating their time to market.
- Streaming — Leveraging Salesforce’s advancements in asynchronous integration capabilities, ML Lake is using streaming for data movement to and from ML Lake. While lowering latencies was the original driver for this shift, some internal studies have shown that switching to streaming reduces overall compute costs by >70%. ML Lake is working on switching its pipelines to use streaming where possible.
Success Stories
ML Lake has been serving production traffic for over a year. Some applications that rely on ML Lake are highlighted below:
- Einstein Article Recommendations — automatically recommends knowledge articles to customers, saving service agents’ time and increasing customer satisfaction using data from the customer’s past cases.
- Einstein Reply Recommendations — integrates with Salesforce’s chatbot product to automate agent responses streamlining user experience and saving agents’ time.
- Einstein Case Wrap-Up — helps support agents wrap up cases faster with on-demand recommendations that are based on chat data and closed case field values.
- Einstein Prediction Builder — allows admins to build predictive models on their data without having to write a line of code. Predictions can be defined on any Salesforce object.
- And many more!
By leveraging the core tenets of Salesforce architecture of metadata, integration and multitenancy, and combining them with modern data tooling, we have built a data platform to serve the needs of machine learning at Salesforce, while addressing Salesforce’s unique scale and trust concerns. We hope you found the post interesting, and we will be talking more about unique challenges and solutions for machine learning at Salesforce in the future. Stay tuned.