In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Priyanka Saraf, Senior Software Engineer on the Agentforce Foundations team. Priyanka is the engineer behind Bring Your Own Planner (BYOP), a multi-tenant AI agent platform that enables teams to develop, deploy, and scale independent custom reasoning engines on shared infrastructure. The system now supports over 7,000 active agent sessions and 14,000–15,000 daily requests across production environments.
Explore how the team eliminated cross-agent interference caused by a monolithic planner where shared infrastructure and deployment pipelines slowed development across more than 100 engineers — and how the team scaled multi-tenant AI agents on Agentforce while maintaining strict isolation and platform overhead as low as 5 milliseconds per request.
What is your team’s mission in building BYOP as a multi-tenant AI agent platform for custom reasoning engines?
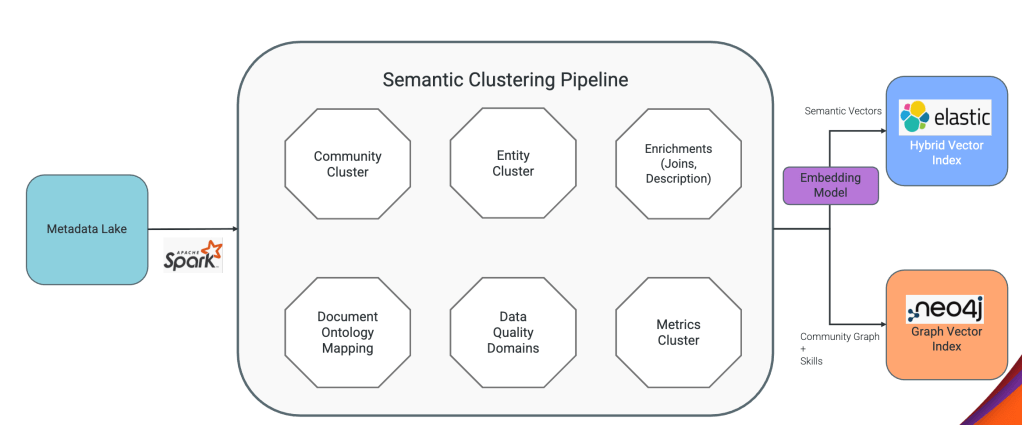
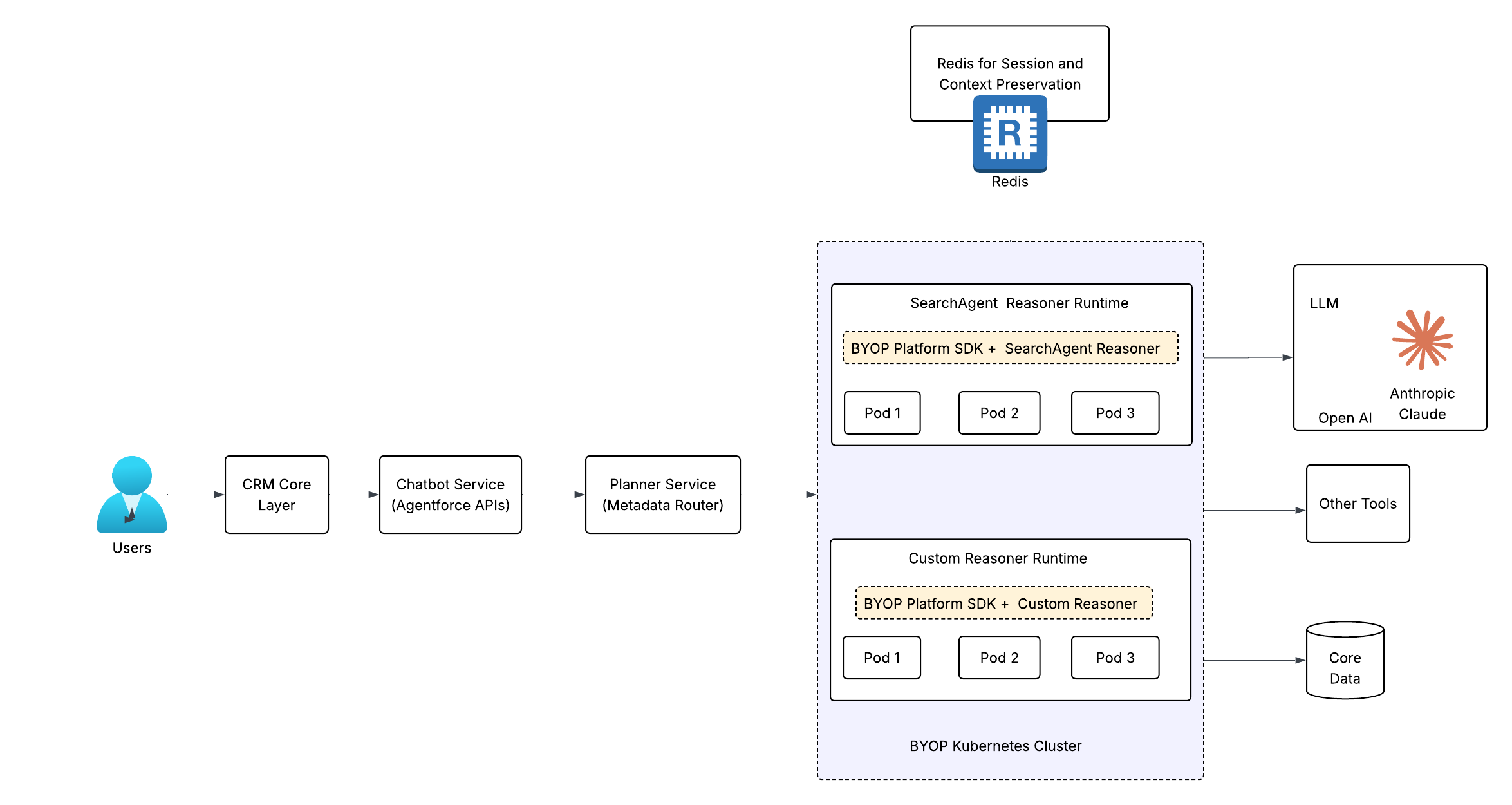
The goal was to build a multi-tenant AI agent platform enabling teams across Salesforce to develop and operate custom reasoning engines without conforming to a centralized planner. In the previous model, agent logic had to fit a shared system — limiting flexibility and slowing innovation across teams building AI-driven workflows.
BYOP was designed to enable team autonomy while eliminating the need to rebuild common infrastructure. The platform provides session management, state persistence, streaming, tool invocation, and integration with LLMs and enterprise data sources — allowing teams to focus exclusively on domain-specific reasoning logic rather than platform concerns.
From the start, the architecture embedded observability, distributed tracing, and horizontal scaling to support independent development and deployment across a shared multi-tenant system — shifting the model from centralized control to decentralized execution.
When all AI agents ran inside a shared monolithic planner, what issues emerged around cross-team interference and agent scalability, and how did BYOP resolve them?
The monolithic planner created tight coupling across code, infrastructure, and deployment workflows. At the code level, a regression in one agent could break others, forcing system-wide validation even for minor changes — at which point the system was no longer scaling, technically or organizationally.
At the infrastructure level, shared compute introduced resource contention. Traffic spikes in one agent caused a noisy neighbor effect, starving others of resources and making scaling unpredictable.
At the process level, centralized CI/CD pipelines became a bottleneck. With more than 100 engineers contributing, every deployment required coordination — slowing development velocity and reducing iteration speed.
BYOP eliminates these failure modes by isolating each reasoning engine. Teams own their code, scale independently based on their workload, and deploy through self-service pipelines — removing cross-team interference entirely and enabling predictable scalability across a multi-tenant AI agent platform.
Isolated Platform SDK with custom reasoning layers: independent scaling, zero cross-team interference.
What were some use-cases that BYOP enabled?
BYOP’s architecture is validated through two production reasoning engines solving opposite problems — Agent-Coworker for read-heavy enterprise search, and WaiiPlanner for write-heavy Data 360 configuration — proving both can coexist on shared infrastructure without interference.
Agent-Coworker synthesizes answers across fragmented enterprise data sources — CRM records, reports, Chatter discussions, knowledge articles, and external sources. When users ask “Show me all high-priority enterprise customer cases from Q4” or “What’s our APAC revenue pipeline?”, the agent interprets intent, orchestrates queries across SOQL, Reports API, Enterprise Search, and Agentforce, and synthesizes results into coherent answers — while maintaining conversational context across follow-ups like “What about their open opportunities?” at scale. BYOP’s pre-built API clients and Redis-backed session management handled infrastructure concerns, letting the team focus exclusively on reasoning logic.
- 4,000+ daily requests at 2.73-second average latency
- 70% of requests involve multi-tool workflows
WaiiPlanner makes Data 360 accessible to non-technical users configuring segments, data transforms, ML models, and data streams — without requiring SQL, schema, or connector knowledge. Unlike Agent-Coworker, it executes write operations requiring explicit confirmation before execution — for example, “Delete transform ‘CustomerAggregation’?” must receive approval before proceeding. The agent implements an 8-state ReAct machine across 7 intent domains, where each state transition persists across user interactions, with async job polling and streamed progress updates during multi-minute operations. BYOP’s session management persists the state machine, action queue, and pending confirmations via SDK — eliminating Redis client implementation, serialization, and TTL management entirely.
- Production-ready in under 4 months
- Orchestrates 24 distinct Data 360 actions across live customer environments
When more than 100 engineers were contributing to a shared AI agent system, what bottlenecks slowed independent development, and how did BYOP restore team autonomy?
As the number of contributing engineers grew, coordination overhead became the primary bottleneck. Teams were forced to align on changes even when working on unrelated functionality — slowing development and introducing friction into the release cycle.
BYOP restores autonomy by strictly separating platform responsibilities from reasoning logic. The platform owns infrastructure, session handling, and tool integration, while individual teams own their custom reasoning engines — enforcing clear ownership boundaries and eliminating unintended coupling.
Self-service CI/CD pipelines allow teams to deploy independently without centralized approval. Because each agent operates in an isolated environment, changes are contained within that agent’s scope — enabling rapid iteration without compromising system stability.
When designing the BYOP platform contract, what tradeoffs made it difficult to balance a simple interface with the needs of diverse AI reasoning engines?
Defining the platform contract was one of the most difficult architectural challenges. The system needed to expose enough metadata and control for complex reasoning engines while remaining simple enough for teams to adopt without friction — overloading the interface would tightly couple teams to platform internals, while oversimplifying it would limit reasoning engines executing complex workflows involving LLM calls, tool orchestration, and multi-step reasoning.
We resolved this by standardizing contracts around the agent lifecycle — how conversations start, how multi-turn interactions are handled, and how sessions terminate. These contracts define the minimum required interface while keeping execution consistent across agents.
A thin SDK reinforces this by exposing platform capabilities such as session persistence, streaming, and tool access — allowing teams to build complex reasoning systems without managing infrastructure or depending on platform internals. This balance between simplicity and capability is what makes BYOP both scalable and usable across diverse AI workloads.
When managing multi-turn conversations in a multi-tenant AI system, what made preserving session context while enforcing strict isolation difficult?
Preserving conversational context while enforcing strict tenant isolation introduced both security and scalability challenges. In a multi-tenant AI system, even a single cross-tenant data leak is unacceptable — making isolation a first-class requirement, not an afterthought.
Isolation is enforced by embedding tenant and session identifiers directly into storage keys, ensuring every read and write operation validates tenant boundaries and eliminating the possibility of cross-tenant access. To manage memory pressure from full conversation history, a 24-hour TTL policy preserves relevant context while automatically evicting stale data.
Thread-safe access patterns prevent race conditions when multiple requests interact with shared storage. Where session storage becomes unavailable, graceful degradation keeps the system operating rather than failing entirely — ensuring session management remains secure, reliable, and scalable under multi-tenant workloads.
As the BYOP AI agent platform scaled in production, what pressures made observability, cost attribution, and performance tuning harder across independently deployed agents?
In production, BYOP handles over 7,000 active sessions and 14,000–15,000 requests per day with platform overhead as low as 5 milliseconds per request. At this scale, observability and cost attribution become significantly more complex — a single request can traverse multiple systems, including platform services, external tools, and LLM integrations.
We addressed this by propagating a consistent session identifier across all services, enabling distributed tracing and full lifecycle visibility. For cost attribution, detailed events tagged with tenant and organization identifiers ensure accurate cost tracking across each agent and workload on shared infrastructure.
Performance tuning is further complicated by variability across agents — some execute simple flows, while others perform multi-step reasoning with multiple LLM calls. Auto-scaling and continuous monitoring dynamically adjust resource allocation to handle this range, keeping BYOP observable, cost-efficient, and performant across diverse AI workloads.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.