In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Neha Awasthi, Senior Manager of Software Engineering at Informatica and the engineering leader behind CLAIRE, a multi-agent AI system embedded across the Intelligent Data Management Cloud (IDMC) that executes enterprise data workflows at a 90% task success rate.
Explore how Neha’s team transformed enterprise data workflows once requiring up to three months of manual effort spanning discovery, governance, data quality, and pipeline orchestration within IDMC — and how they moved beyond the constraints of single-agent AI systems to coordinate multi-agent execution across workflows involving 50–60 model calls per request.
What is your team’s mission in building CLAIRE as a multi-agent AI system for enterprise data management?
Our mission is to build a multi-agent AI system that transforms enterprise data management across the IDMC — making complex workflows intuitive and automated for users beyond technical specialists. Historically, workflows spanning cataloging, governance, data quality, integration, and master data remained fragmented, forcing teams to navigate multiple tools and apply deep expertise just to complete a single use case.
We addressed this by building CLAIRE as a multi-agent AI layer embedded directly across IDMC rather than as a standalone system. It orchestrates capabilities across discovery, classification, data quality, and pipeline execution through a unified interface — requiring agents designed to interpret user intent, operate across heterogeneous systems, and execute workflows that span multiple domains.
To meet users where they work, we introduced two interaction models: CLAIRE GPT as a generalist interface for cross-domain requests, and specialized copilots embedded within individual products. Users can explore workflows conversationally or execute tasks in context, ensuring AI assistance is available regardless of where they start.
The CLAIRE multi-agent architecture predates “agents” as an industry term — driven by the fundamental complexity of enterprise data workflows that demanded autonomous, coordinated execution rather than simple copilot-style assistance.
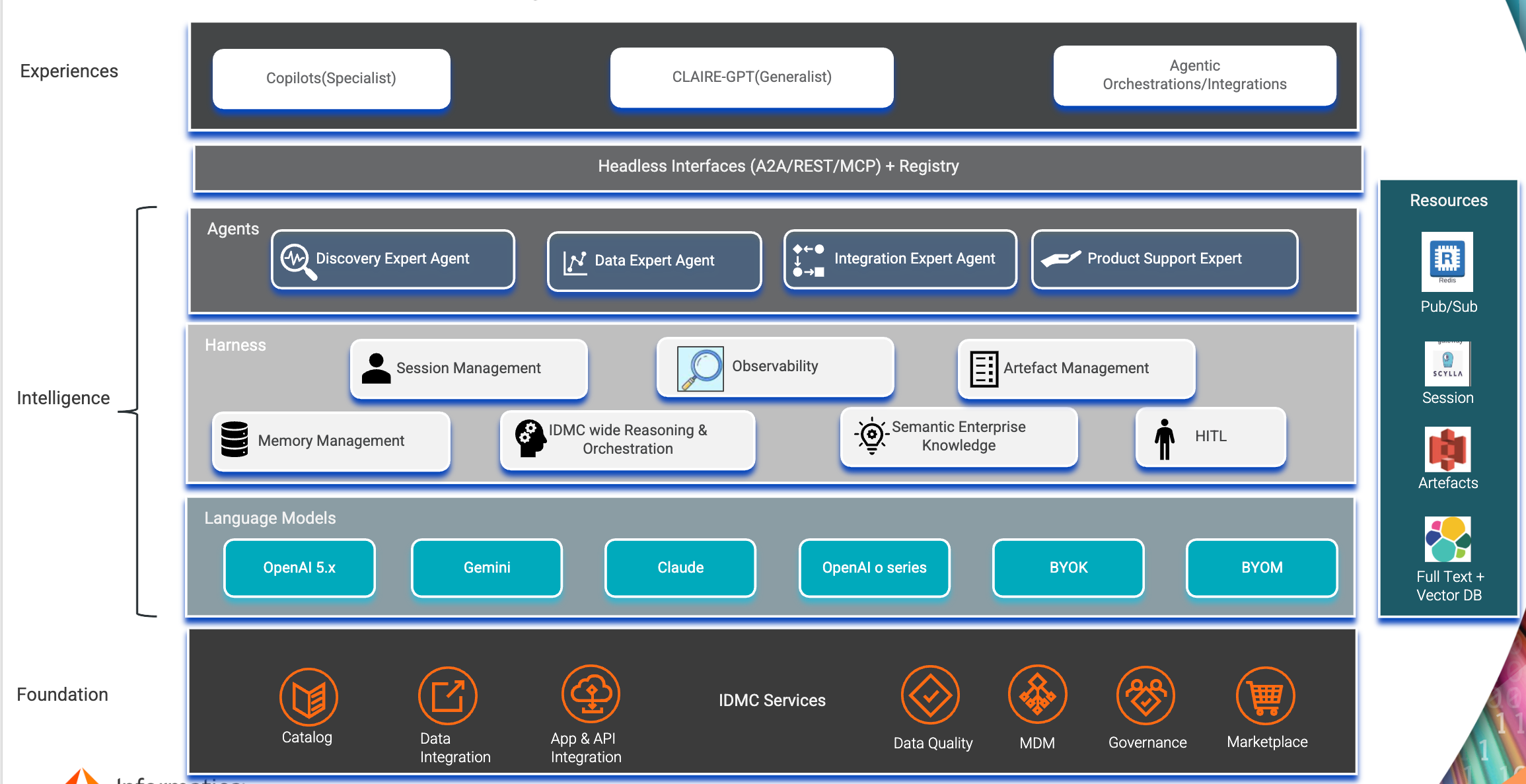
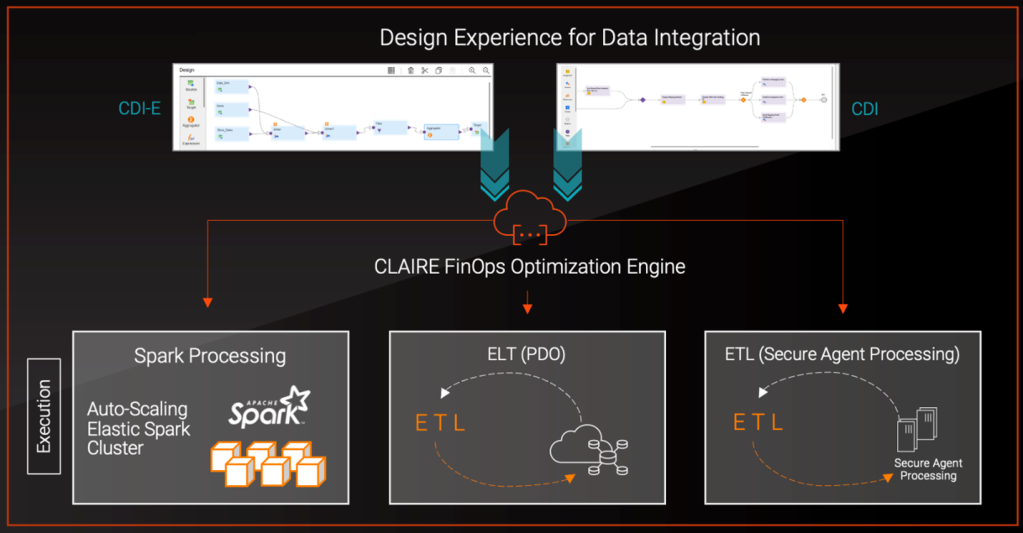
Stack View: Agentic foundation, intelligence and experiences.
When enterprise data workflows spanned discovery, governance, data quality, and pipeline orchestration, what made a unified system approach unworkable at scale?
Enterprise data workflows break down at scale because discovery, governance, data quality, and pipeline orchestration operate across disconnected systems with no unified execution layer. Each stage depends on different tools, interfaces, and expertise — creating a fragile chain across teams with no single point of coordination.
A unified system proved difficult to build because workflows are interdependent but distributed. A business user identifying an issue could not act on it directly. That insight had to move through translation, rule creation, validation, and pipeline integration across multiple systems — each handoff introducing latency and context loss, slowing execution and compounding error risk.
We addressed this with a multi-agent system that collapses these stages into a continuous workflow. Users initiate requests in natural language, and the system orchestrates discovery, profiling, rule generation, and execution end to end — eliminating manual handoffs and reducing workflows that previously took up to three months down to days.
When attempting to execute enterprise data workflows with a single AI agent, what limitations in context, tooling, and reasoning caused system breakdowns?
Single-agent AI systems fail in enterprise workflows because they cannot simultaneously handle context-heavy reasoning, diverse toolchains, and multi-step execution. Each step — search, profiling, statistical analysis, rule generation, and code execution — demands different inputs, tools, and reasoning patterns that a single agent cannot reliably manage in one pass.
In early iterations, we exposed multiple tools within a single agent. These designs broke down quickly: the agent selected incorrect tools, exceeded context limits, and produced inconsistent outputs across steps. Latency compounded as the agent attempted to reason across too many operations simultaneously.
These failures made specialization the necessary path forward. By decomposing the system into multiple agents with focused responsibilities, we reduced context load, improved tool selection accuracy, and stabilized execution across multi-step workflows.
When designing a multi-agent AI architecture for enterprise data workflows, what challenges shaped orchestration, planning, and agent specialization?
Designing the multi-agent system required solving orchestration, planning, and agent specialization as core architectural challenges. We introduced an orchestration agent as the control plane, responsible for intent detection, plan generation, and routing execution across specialized agents.
Each specialized agent operates within a constrained context and optimized toolset. The data quality agent, for example, encompasses distinct skills — profiling, rule recommendation, rule generation, and cleansing — each with dedicated tools and model configurations tuned for accuracy and efficiency.
Balancing flexibility with control was a central challenge. Because enterprise workflows vary widely, we introduced a planning layer in which the orchestration agent generates a high-level plan that users can review and modify before execution begins. This separation allows the system to adapt to diverse requests while maintaining predictable, auditable behavior.
We also implemented deterministic tool routing logic to ensure agents invoke the correct tools based on intent and context — without it, outputs became inconsistent. Together, orchestration, planning, and specialization form the foundation that enables reliable execution at scale.
When coordinating multiple AI agents across chained data workflows, what challenges emerged in execution reliability, dependency management, and failure propagation?
Coordinating multiple agents introduces distributed system challenges across execution reliability, dependency management, and failure propagation. With workflows involving 50–60 model calls — where outputs from one step feed directly into the next — the system is highly sensitive to errors at any intermediate stage.
Failure propagation became a critical issue early on. A single incorrect output, such as malformed metadata or an invalid rule, cascaded across agents and caused full workflow failure. These failures compounded the problem by surfacing several steps later, making them difficult to trace back to their origin.
We addressed this by introducing validation checkpoints and strict data contracts between agents. Each step validates inputs and outputs before passing them forward, preventing invalid states from propagating downstream. Guardrails detect anomalies early in execution, containing failures before they can spread.
Dynamic user modifications introduced additional complexity. Because users can adjust execution plans in real time, the system must recompute dependencies on the fly without disrupting the workflow in progress. Adaptive planners handle these changes while preserving execution integrity.
While the conversational interface represents the most visible interaction model, the architecture also supports background and headless agent execution. Agents can operate autonomously on scheduled or event-driven triggers — running data quality assessments, executing rule validation, or monitoring pipeline health without requiring a user to be actively present in the conversation. This ensures the system delivers value not only through interactive workflows but also through continuous, autonomous data quality operations at scale.
When a multi-agent system had to interpret open-ended enterprise data requests, what made context modeling and semantic understanding difficult to implement correctly?
Context modeling becomes critical when a multi-agent system must interpret open-ended enterprise data requests across heterogeneous datasets. Because users express intent in business language rather than system instructions, that intent must be translated into executable workflows before any agent can act on it.
The challenge is both dynamic and constrained. The system must identify the relevant context for each step without exceeding model limits — too much context degrades performance, while too little produces incorrect results.
We addressed this by building a semantic layer that performs entity resolution, intent decomposition, and metadata enrichment before execution begins. This ensures each agent receives precisely the context it needs — no more, no less.
Without this layer, the system would fall back on pattern matching and produce generic or incorrect results. With it, the system delivers accurate, context-aware execution across enterprise data environments.
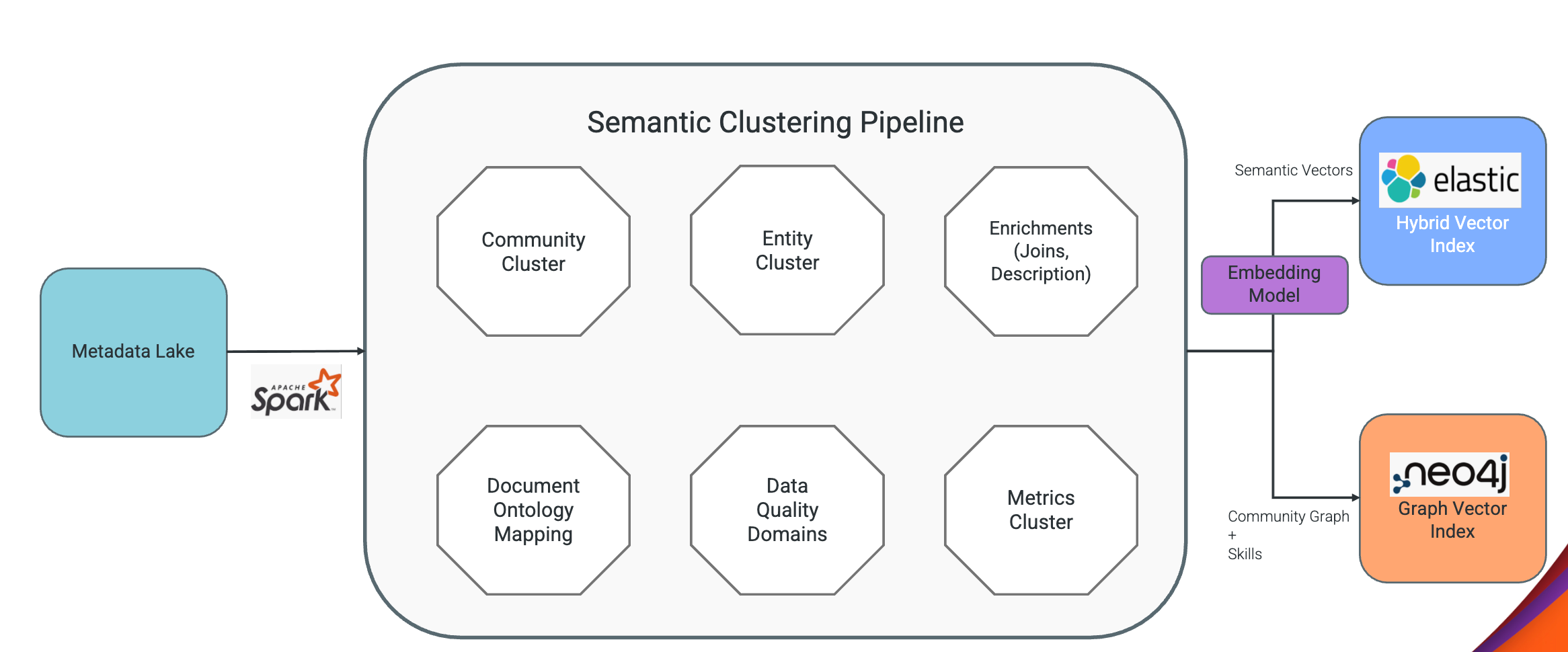
Semantic knowledge preparation.
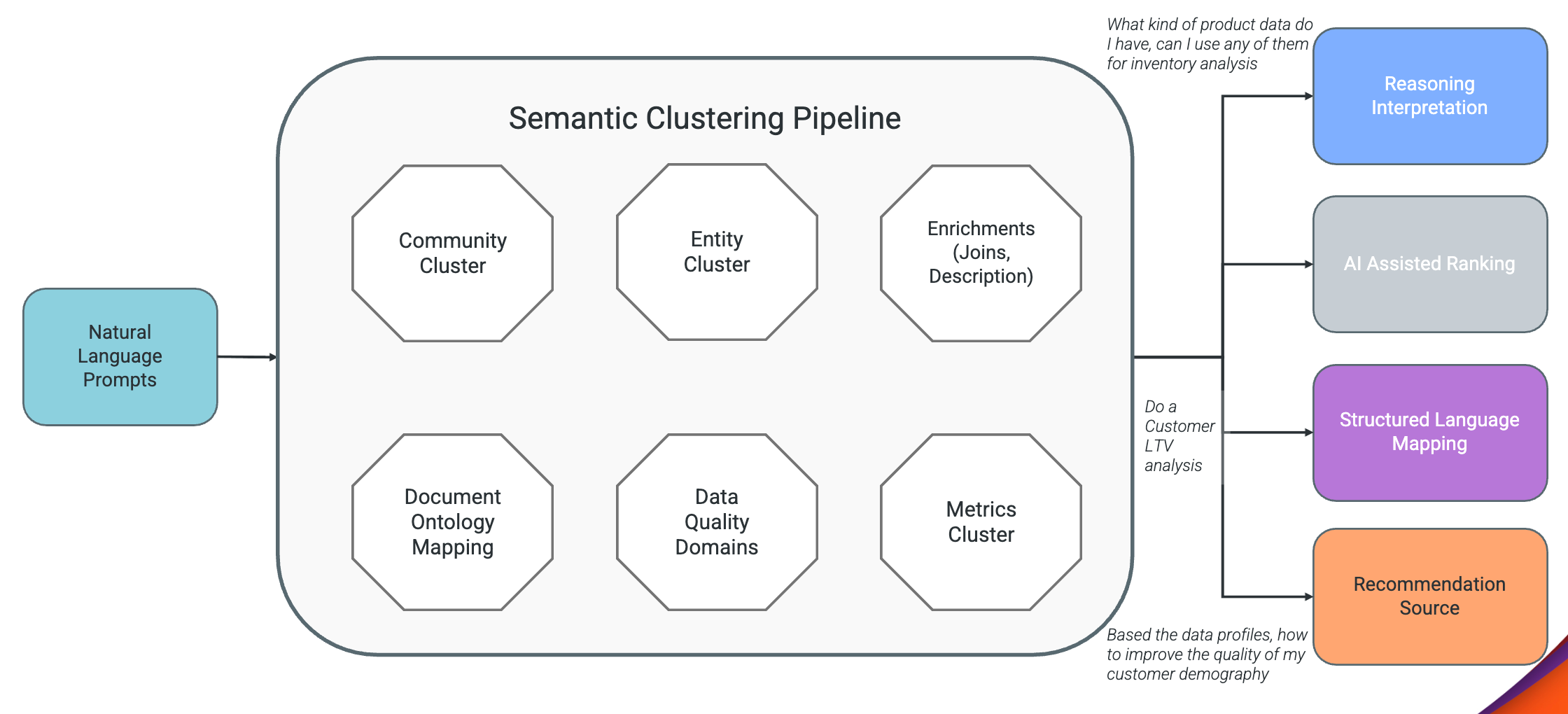
Inference time consumption.
When preparing a multi-agent AI system for production, what accuracy, grounding, and reliability challenges had to be solved before GA?
Preparing the system for production required validating accuracy, grounding, and reliability across the full execution pipeline — and we recognized early that every agent deserves its own specialized validation framework, not a one-size-fits-all approach.
Unlike traditional AI evaluation built on precision, recall, and F1 scores, we introduced agent-specific metrics tailored to what each agent actually does. For the cleansing agent, we validate code execution correctness, fix completeness, and before/after data integrity. For rule generation, we measure deduplication accuracy, rule logic validity, and test data coverage. For recommendation, we evaluate contextual relevance, grounding against actual catalog metadata, and acceptance rate.
This shift from generic model metrics to agent-specific outcome metrics represents a fundamental change in how enterprise AI systems should be evaluated — measuring not just whether the model produced a correct token, but whether the agent completed the right action end to end. The data quality agent achieved a 90% task success rate, 98% grounding accuracy, and a 1% hallucination rate, establishing a measurable foundation for outputs that are both complete and trustworthy.
We implemented a multi-layered evaluation framework encompassing LLM-as-a-judge scoring and reflection-based validation for generated code. Code is reviewed for correctness prior to execution, preventing failures from propagating downstream before they can be caught.
Reliability demanded consistency across every stage — intent detection, planning, execution, and summarization. We introduced validation layers, guardrails, and horizontally scalable infrastructure to sustain performance under production load.
Together, these improvements ensure the system operates reliably at enterprise scale and delivers consistent results in real-world environments.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.