

It’s been a few years since Pardot joined the Salesforce family, and we’ve grown by leaps and bounds. Not surprisingly, the internal engineering tools that served us well when we were a startup haven’t always kept up as we’ve scaled. Our code deployment tooling is one example that we spent some time rearchitecting recently.
Pardot engineers deploy code to production multiple times every day, so when it started taking over 30 minutes to get new code out to all of our servers, we knew something had to change. We recently finished overhauling our code deployment pipeline, reducing our deployment times by over 70%.
rsync: Safe but slow
Pardot uses the Apache HTTP server as its web server, so the goal of our deploy pipeline is to ship the latest code to the /var/www/current directory on each of our hundreds of servers.
When we were a startup, we used the widely-used rsync utility to push code out to each servers in serial. It was safe and stable, but it was slow.
Enter pull-based deployment
We call our new deployment mechanism pull-based deployment. Instead of pushing code out via rsync, our servers now pull code from an artifact server in parallel. It’s still safe and stable, but also fast.
Pull-based deployment integrates many of our internal engineering tools. The continuous integration (CI) servers are the first such system. Every time we merge to the master branch of our git repository, our continuous integration servers build a deployable artifact. For our main application, the CI servers run some build scripts that generate a machine-friendly cache of our source files. Afterward, a tarball (.tar.gz) of the resulting source and generated cache is created, which is then uploaded to an artifacts server and tagged with its git revision and build number. That tarball is an immutable artifact of the build, and (if it passes our automated test suite), is what will be deployed.
The artifact is used throughout the rest of the build and deployment process. When the continuous integration servers proceed to run our automated test suites, the first step is to download the artifact. We specifically do not clone the git repository at this stage. Part of the reason is performance — cloning a git repository is surprisingly expensive, and we’d have to regenerate the cache — but, more importantly, the artifact is the thing we are going to eventually deploy to production, and it’s critical that our tests run against exactly that.
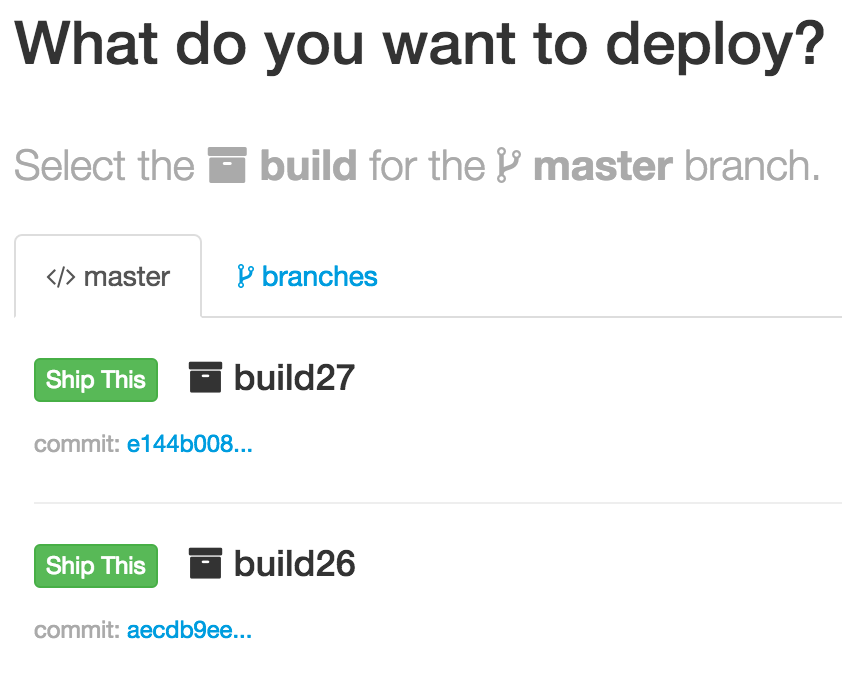
If our automated tests pass, the code is ready for deployment. We’ve built a small Ruby on Rails web application called Canoe to manage the workflow. An engineer logs into Canoe to select the build they want to deploy. The list is generated by querying the artifacts server: each build artifact has associated metadata about the project it is from and the build number.
Initially, nothing happens when we ship a build from the Canoe web interface. Canoe’s job is only to expose via an API what an engineer wants to be deployed. A separate program we call Pull Agent is present on our servers to check in with Canoe every minute and apply the desired changes.
Canoe and Pull Agent communicate over an JSON API, secured with TLS, IP whitelists, and pre-shared secret API keys. Every minute, Pull Agent requests the latest deploy by making a GET request to Canoe’s API. In response, Pull Agent receives a JSON payload that describes what should be deployed:
{
"target: "production",
"repo": "pardot",
"build_number": 27,
"artifact_url": "https://artifact.example/PARDOT-27.tar.gz",
"completed": false
}
If the latest deploy is the same as what’s already deployed to a particular server, Pull Agent immediately exits: it has no work to do this time.
When something does need to be deployed, Pull Agent’s first job is to start downloading the artifact tarball. This is the same tarball we built in the first continuous integration stage.
Our build artifacts can be large
A deploy could cause a thundering herd that would slow our artifact server or our network if all of our servers requested the same tarball at once. To avoid this, all requests to download an artifact are proxied through Squid caching proxies. Even if many hundreds of servers need the same tarball at exactly the same time, Squid only makes one request to the artifact server. The rest of the requests are served from cache.
After the artifact tarball is downloaded to a particular server, it is uncompressed to a temporary location.
Next, Pull Agent copies any files that have changed into one of two release directories. Apache’s document root is configured as /var/www/current which is always a symbolic link to either /var/www/releases/A or /var/www/releases/B. We learned this method from Etsy. The new code is copied to whichever release directory (A or B) is not presently linked from current. To copy the code, Pull Agent uses rsync:
rsync --recursive --checksum --perms --links --delete \
/tmp/build-12958/ \
/var/www/releases/B
But earlier I said rsync was slow! Not in this case: while rsync is typically used to copy files between machines on a network, it can also be used to copy files between two directories on local disk, which is how Pull Agent uses it in pull-based deployment. Pull Agent uses `rsync -checksum` to ensure that only files that have changed since the previous deploy are changed: rsync compares each file’s checksum and copies it only if it has changed. If we copied every file regardless of whether it changed, we would invalidate every file in the Opcache, causing a cache stampede when the new release went live.
Finally, we swap the current symlink to the other release directory. Pull Agent creates a symbolic link in a temporary location, then invokes `mv -T` to move it into place. `mv -T` is an atomic operation provided both files reside on the same filesystem.
ln -s /var/www/releases/B /var/www/releases/current.new
mv -T /var/www/releases/current.new /var/www/releases/current
Combined with mod_realdoc (thanks again, Etsy!), our code deployments are atomic on any particular server. That is, a request will only ever load code from a single build: it will never partially load code from a previous build, and then load the rest of the code from a new build.
Compared to our previous deployment mechanism, pull-based deployment is about 70% faster, bringing typical deploy times down from ~35 minutes to ~10 minutes.
Trust
Nothing is more important to Salesforce than our customers’ trust, and we feel like pull-based deployment plays a role in upholding that trust.
Pardot engineers typically deploy new code to production about 7 times per day, and with the increased speed of pull-based deployment, we expect we’ll deploy code even more frequently in the future. Initially this might seem unsafe: wouldn’t more deploys make the system more unstable? However, we find that when combined with modern software engineering practices such as automated test suites, feature toggles, and other lessons from the continuous delivery movement, we counterintuitively make our system safer by deploying continually: the system evolves in frequent, small, and understandable increments. If a change does cause an issue, it can be rapidly rolled back.
We are also pleased with the security improvements present in the architecture of pull-based deployment. We have been able to eliminate a deploy account on our servers that was previously required for rsync+SSH to push code out. Every deploy is auditable using Canoe’s database, and only engineers who regularly work on the application are authorized to initiate a production deploy.
The Future
Pull-based deployment also sets us up for the future. In the next few months, we’ll be giving some serious thought to containerization. If at some point we want to deploy a container, we can make small adjustments to download layers of images instead of a tarball of code.
Do you deploy code at scale? What tricks have you found to be effective for speed and safety?



