Written by Archana Kumari and Scott Nyberg.
The tsunami of data — set to exceed 180 zettabytes by 2025 — places significant pressure on companies. Simply having access to customer information is not enough — companies must also analyze and refine the data to find actionable pieces that power new business.
As businesses collect these volumes of customer data, they rely on Salesforce Data Cloud — a single source of truth for harmonizing, storing, unifying, and nurturing this information as it dynamically evolves over time. Consequently, businesses understand their customers’ needs better than ever — powering enhanced customer experiences.
Looking under the hood of Data Cloud reveals a couple key layers. The platform’s bottom-most layer, the storage layer, consists of a data lake that ingests petabytes of customer data. Above that lies a compute plane layer, which processes, massages, and interprets the big data — enabling the information to be segmented and activated.
Essentially the engine behind Data Cloud, this tier-zero fabric layer’s journey began with a complex data migration orchestration to Data Cloud’s data lake from Dataroma — Salesforce’s cloud-based marketing intelligence platform — leading to the creation of Data Cloud’s big data processing compute layer team in India.
Executing this task was massive as it involved multiple teams — who managed the migration orchestration effort? Say hello to Data Cloud’s compute layer team. The migration initially challenged them because they had no experience in big data processing. How did they successfully orchestrate the migration in mere months and then immediately launch their tier-zero layer to process petabytes of customer data?

Salesforce Data Cloud’s India-based compute layer team.
Read on to learn how the team overcame the odds…
How did the team migrate terabytes of data from Salesforce Dataroma to Data Cloud’s data lake?
The Data Cloud data lake project kicked off in 2020, when the Data Cloud storage team built Data Cloud’s data lake on top of Apache Iceberg. Shortly thereafter, the 10-person, India-based compute layer team faced its biggest test: Develop a workflow orchestration to migrate existing customers from Datorama to the data lake. However, the compute layer team was new. How new? Its members had just joined Salesforce, had no big data background, and had no time for onboarding. So, shortly after joining Salesforce, engineering management directed the team to solve this problem, which involved 20+ teams altogether — and a steep learning curve.
The compute layer team’s mission proved daunting: Develop the migration orchestration in three months, test it in production, and execute the final migration just three months later.
To migrate the data from Dataroma to the Data Cloud’s data lake, the team used Airflow, an open-source tool for creating, scheduling, and tracking batch-oriented big data processing workflows. However, given this gargantuan migration task, existing Airflow service could not provide a correct SLA, delivered behavioral inconsistencies, and failed to scale.
Diving deeper, Airflow’s “Scheduler” component was used to schedule when tasks were run. However, tasks began to slip as the scheduler tool occasionally experienced delays up to several minutes which, in turn, extended the migration to several hours.
Pondering its dilemma, the team examined two options: They could optimize Airflow, however, its performance number shared by the Airflow community did not reflect the team’s initial observations about the platform. Alternatively, the team could leverage a workflow orchestration from AWS or Azure, however, onboarding a new offering to Salesforce’s Hyperforce — a next-gen infrastructure platform that uses public cloud to rapidly deliver Salesforce software to global customers — might have required months. Ultimately, the migration deadline was firm, which meant the team had no time to explore an alternative migration tool and focused on optimizing Airflow to accomplish their goal.
How did the team perform the optimization? First, they created a panel of sub-teams, tasked with determining performance gaps within Airflow. Second, they tweaked its configuration — effectively solving the scalability and consistency issues while bringing the SLA within acceptable limits.
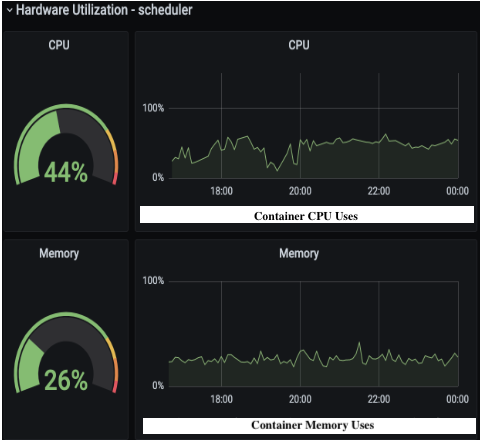
Airflow Scheduler CPU availability and memory utilization after performance tuning.
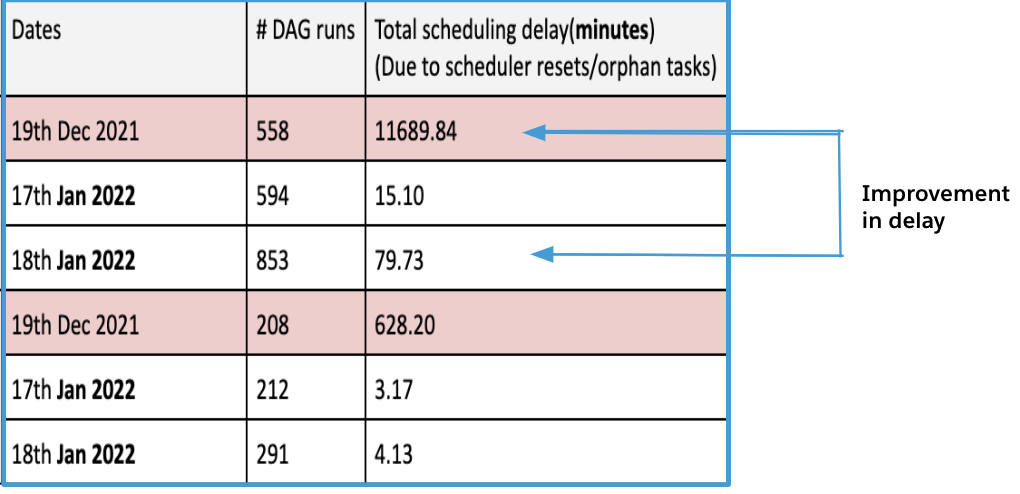
Airflow Scheduler latency improvements before (red) and after (white) performance tuning.
Third, teams began writing directed acyclic graphs (DAGs) in Airflow in parallel. Following an iterative approach enabled them to discover, copy, validate, roll out, and mark the migration status. This led the team to scale their efforts, where they executed 50+ tasks within a single DAG, enabling them to migrate a tenant to Data Cloud’s data lake.
The step-by-step approach for migrating Dataroma tenants to Data Cloud’s data lake.

Finally, 20+ globally-dispersed scrum teams focused on deciphering the data, interpreting the schema, and moving the data from Dataroma to Data Cloud’s data lake. Through this collaboration, the compute layer team ensured an optimized workflow to deliver a smooth and seamless migration.
How does the compute layer team perform big data processing for Data Cloud customers?
By successfully migrating customer data from Dataroma to Data Cloud’s data lake, the compute layer team effectively set the table for launching its tier-zero layer — paving the path to process customer queries.
Where does the processing begin? Data Cloud’s “ingestion layer” continuously collects petabytes of customer data at tremendous speeds and deposits it into Data Cloud’s data lake.
How does this vast amount of data get processed? This is where Spark steps in, a big data processing tool that massages and harmonizes the data to create something meaningful. To achieve this, it removes extraneous characteristics of the data and enriches it — adding more properties as needed.
After the data is unified, customers can run interactive queries, where the compute layer team performs data segmentation with Trino, a big data tool designed to efficiently query volumes of data by leveraging distributed execution. Trino harnesses the power of split logic, which splinters queries into multiple chunks and collates the data — providing results within a fraction of a second.
What does this look like? When a multi-brand company plans to launch a new product, they can define their target market by determining which of their existing customers within a certain age group have purchased items within a similar price range. This is how segmentation comes in play. Customers will submit a query request to Data Cloud. That triggers the compute team to use Trino and provision runtime clusters to ensure scaling, resiliency, availability — leading to lightning-fast data activation and customer results.
Learn more
- Read this blog to learn more about how India’s brilliant big data processing team engineers Data Cloud.
- Check out our Technology and Product teams to learn how you can get involved.
- Stay connected – join our Talent Community!