In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Andrew Patti, Senior Manager of Software Engineering for Salesforce Personalization. Andrew and his team developed the first Data Cloud-native ML recommendations system.
Discover how they engineered this flexible schema, adopted a unique multi-cluster architecture, and implemented automated normalized discounted cumulative gain (NDCG) evaluation pipelines within CI/CD to ensure continuous ML model performance.
What is your team’s mission building Data Cloud-native ML recommendation systems for Salesforce Personalization?
The team’s mission centers on building out extensive personalization capabilities on the unified Data Cloud platform, and a by-product of this will be feature parity with the in-market systems. To elaborate further, we manage three separate recommendation systems — Commerce Cloud, Marketing Cloud Personalization, and the new Data Cloud-native platform. Last holiday, our in market products managed the impressive feat of processing 40 billion personalization events at 99.999% availability during the Black Friday holiday period. A significant number of those went through the recommendations systems that we help maintain.
Our goal is to ensure that customers transitioning from existing personalization systems have seamless migration paths, where all functionality works exactly as before. Salesforce Personalization, our new product built on Data Cloud, is designed to replace Marketing Cloud Personalization. Unlike legacy systems constrained by predefined schemas, this Data Cloud-first approach enables customers to act upon Data Cloud data through our recommendation engine, a capability that was previously unattainable.
Our architecture prioritizes scalability, ease of development, customer usability, and future-facing capabilities. We are committed to maintaining the ethical use of ML and the trust of our customers, ensuring that our recommendation systems not only meet current demands but are also poised to evolve and grow.
Andrew shares why engineers should join Salesforce.
What’s the biggest technical challenge your team recently faced and overcame?
The most significant engineering challenge we faced stemmed from Data Cloud’s unprecedented flexibility: customers can define any data model object structure, rather than being constrained to predefined schemas. We have a responsibility to be able to recommend that item, regardless of shape. Legacy systems had certain built-in guardrails. We could declare a class in our back-end and know generally how large those objects are going to be since we pre-defined many of the fields. For the new service we’re building, our team works with abstract schemas, allowing customers to recommend a wide range of item types, from restaurants and articles to any arbitrary item type with custom attributes.
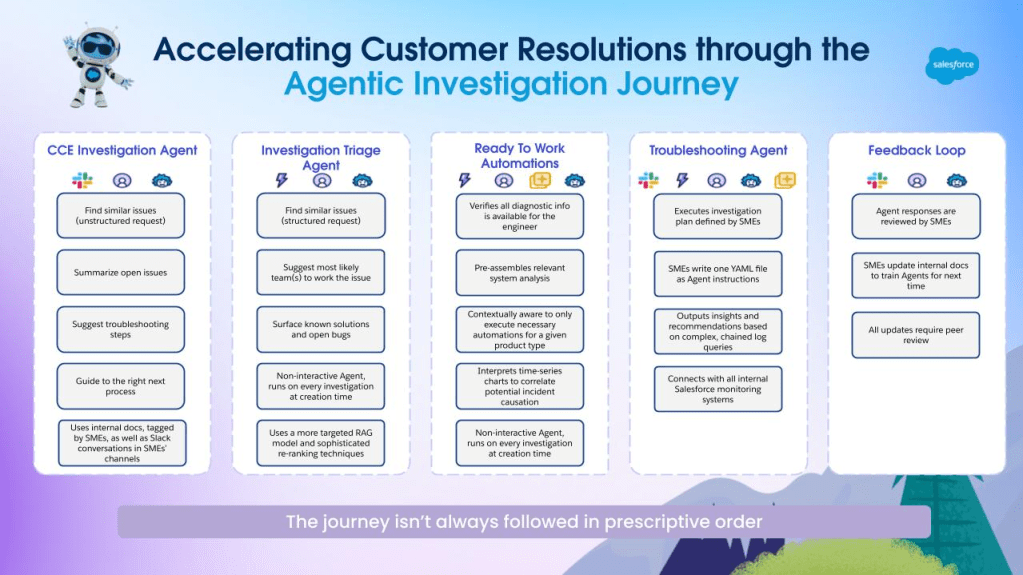
To address these challenges, we built comprehensive rule and filter capabilities with intelligent resource isolation. In legacy systems, features like “don’t show out-of-stock items” were automatic because every product had stock attributes. However, with abstract schemas, customers must configure these business rules manually. This requires extensive documentation, coherent interfaces, and robust guidance systems to ensure smooth setup and operation. Additionally, our team is starting to pioneer agentic UI approaches, where customers can interact with AI agents for setup assistance. These AI agents help navigate the flexibility-complexity tradeoff inherent in abstract schema architecture, ensuring that customers can fully leverage the power of Data Cloud while maintaining usability.
What was the biggest quality assurance challenges your team faced?
The biggest challenges centered on measuring recommendation relevancy without comprehensive evaluation frameworks for our ML models. Traditional model training produces results, but validating quality across diverse customer use cases was problematic without a way to measure relevance. The team needed automated quality detection capabilities to prevent model degradation from reaching production environments.
The breakthrough came with the implementation of offline evaluation frameworks using the NDCG metric to measure recommendation relevancy. This approach allows us to assess recommendation quality for specific end users across different datasets, enabling consistent quality comparisons over time for trained models in lower environments. Using NDCG is standard practice for ML Science teams to measure model quality.
Most importantly, the team integrated offline NDCG evaluation into our CI/CD pipelines as automated build gates. When engineers merge code that affects model performance, the evaluation framework detects any quality degradation and fails if recommendations fall below established thresholds. This prevents ML model quality regressions from reaching production and provides constant reminders during development. It represents a fundamental shift from reactive quality management to proactive quality enforcement within our standard development workflows.
Essentially, the system runs automated tests on model results, measuring recommendation quality for sample users against established baselines. Engineers and ML scientists are notified of a broken test when performance degrades, ensuring that high-quality recommendations are consistently delivered to our customers.
Andrew discusses an emerging technology that his team is researching now.
How does your multi-cluster recommendations database architecture handle 40+ billion recommendation events during Black Friday?
The team manages three separate recommendation systems that serve e-commerce customers who rely on them for significant revenue during holiday periods. Many customers generate a significant amount of their annual revenue during November and December, placing a critical responsibility on the team to ensure enterprise-grade reliability and performance, especially during Black Friday weekend.
During the holiday week in 2024, which spans from Thanksgiving through the following week, the team processed 40 billion events with 99.999% availability. They served 29.5 billion product recommendations, marking a 62% year-over-year increase, 32 billion ML predictions, and 15 billion total personalization requests, a 36% increase from previous years. On Black Friday alone, a single in-market product handled over 500 million recommendation requests and 2 billion requests throughout the weekend, all while maintaining controlled costs and low latency.
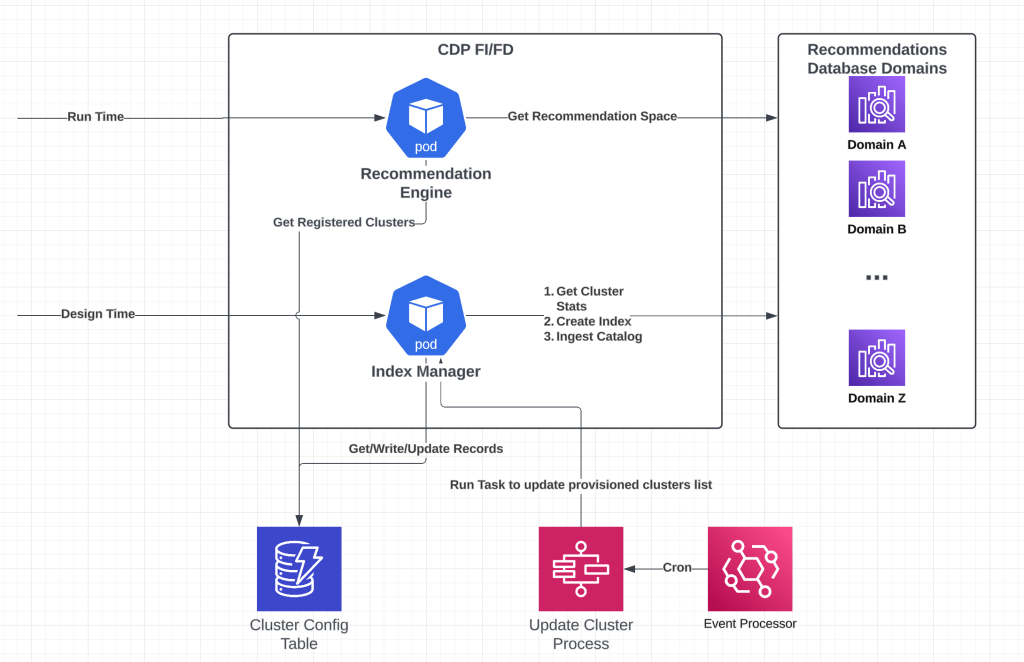
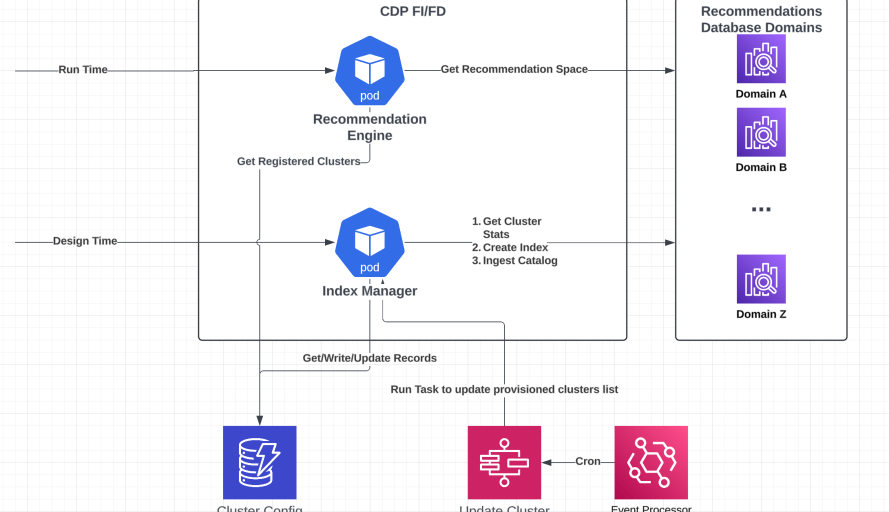
Recommendations system multi-cluster architecture diagram.
The technical solution for one of our in-market products revolves around a multi-cluster recommendations database architecture that prevents noisy neighbor problems through intelligent resource isolation. When one customer’s index becomes saturated, the team isolates them to dedicated recommendations database clusters which can be scaled up both vertically and horizontally, ensuring that their performance issues do not affect other customers.
Each September and October, the team implements sophisticated preparation procedures, scaling systems 3-5 times in anticipation of holiday traffic. In 2024, These procedures included per cluster semaphores, upscaling node types, architecture overhauls, and query schema upgrades optimized for peak performance. Our success with the in-market products have informed our architecture decisions on the newer recommendations system based on Data Cloud.
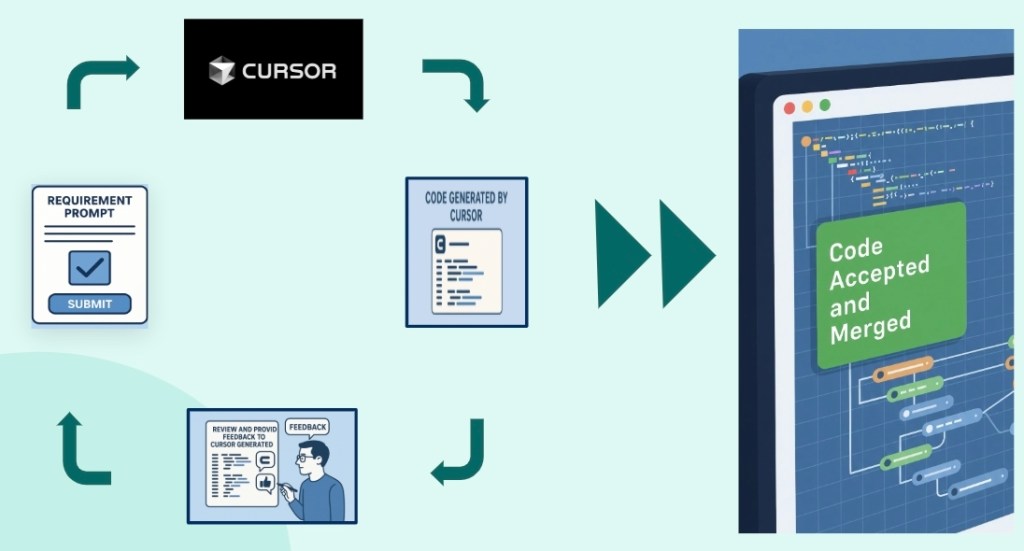
Andrew shares a story about Cursor, an AI tool that improves his productivity.
What AI-powered development workflow optimizations eliminated code review bottlenecks for your ML engineering team?
The engineering team faced development workflow bottlenecks, especially when building complex ML recommendation systems. Traditional methods led to varied coding styles, such as different indentation patterns, exception handling techniques, and coding standards, which made code reviews time-consuming and prone to errors in their Java-based systems.
To tackle these issues, the team adopted AI-powered development tools, integrating Cursor or IntelliJ with Claude, in response to Salesforce’s directive for 100% AI productivity tool adoption across all engineering teams. They established four key principles for AI-assisted development:
- Explicitly verify AI-generated code.
- Clearly define requirements without letting AI alter fundamental standards.
- Regularly refresh the context to avoid confusion.
- Thoroughly plan before coding, with clear goal tracking.
These principles were systematically integrated into the team’s workflow. Custom personas were developed with specific rules for Java serialization, exception handling, and annotations, and these configurations were stored in repositories for company-wide use. This approach standardized AI-assisted development across teams while accommodating the unique coding needs of the ML systems.
The results were transformative. AI tools eliminated many style-related issues in code reviews, ensuring uniform and consistent code across the three recommendation systems. Although developers remain responsible for all generated code, the AI tools are highly effective at writing simple unit tests and significantly boost productivity. Instead of requiring deep expertise in specific domains, the tools allow developers to use generalist skills to review and validate AI-generated work.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.