

by Mingliang Liu and Prashant Murthy
Our first post in this blog series covered background about infrastructure provisioning for HBase deployment in public cloud, including mutable vs. immutable deployment, stateful vs. stateless services, and VM- vs. container-based engines. In this second part of the blog series, we will show how we use Terraform, Spinnaker, and Kubernetes to implement that.
Mutable VM-based Infrastructure
To provision mutable VM-based infrastructure, we created a BigData Terraform module. By using extensively a public cloud-specific provider, the Terraform module 1) defines an instance template and regional instance group resources to provision VM instances, 2) defines a list of persistent disks (PD) and object store resources for storage, and 3) configures cloud-init to organize startup-scripts which resolves dependencies and sets up a new VM. After the Terraform module provisions those cloud resources, it will also generate infrastructure information to be consumed by Ambari server, including VM instance names, big data service roles, and zones (for topology awareness).
Figure 1 is a flow chart of this approach. The top of the figure is a deployment pipeline. Terraform and Ambari functionalities are running in two different stages, which internally are shared pipelines managed by another team. The two stages are chained in the same HBase deployment pipeline for easier central management. For both VM- and container-based infrastructure provisioning, the continuous delivery (CD) pipelines are running in Spinnaker platform. The bottom of the figure is all public cloud resources for an HBase cluster. It includes the VM compute instances, persistent disks, and virtual private networks (VPC). Ambari will update those instances by installing BigData binaries, changing configuration files and restarting the service process.

For both VM- and container-based infrastructure, a major deployment task is assigning network attached persistent disks (PD) to HDFS in such a way that: 1) PD and DataNode in a mapping pair are in the same zone, 2) no two DataNodes are assigned with the same PD, and 3) all PDs are assigned evenly across all DataNodes. In our Terraform module, this assignment is deterministic. Once assigned, a VM will always get the same group of PDs to attach during restart or rolling upgrade. For a starter, in Terraform module we provision the VMs and PDs and assign PDs to VMs statically by making PDs have the same name of the VM. In VMs startup scripts, they will wait for assigned PDs to be ready, attach the ready PDs, and mount them to predefined data directories. Alternatively, we tried using Terraform resource defined by a public cloud provider to bind the disks to VM declaratively. We moved from this implementation because when the VM restarts, we would have to run terraform apply again since this Terraform resource is gone. This means we need to trigger a Spinnaker pipeline execution in time just to recreate this logic resource. In contrast, as we decouple the PD assignment and attachment, the Terraform state is more lightweight and execution is faster.
This decision led us to think about a broader question: what changes should trigger terraform apply? In an effort to simplify which cases should be handled by Terraform and which should be handled by other means, we have defined the concepts of “Cluster Specification” and “Internal Specification” to define a cluster infrastructure. In short, “Cluster Specification” is defined as the exposed Terraform variables i.e. the configuration of our cluster (size, machine type, instance number, version etc) whereas “Internal Specification” is defined as changes that occur within a cluster not pertaining to changes in cluster per se config. Following this guideline, VM to disks mapping should be internal. In other words, VMs when restarting should “auto-heal” themselves by automatically attaching assigned disks without further help from Terraform.
After we put this approach into place at scale, we have thought of a few advanced use cases as follows.
- First, auto-restarting via instance group manager seems not to be a problem if the VM will keep its instance name identity. This is to address the problem “what-if a VM dies.” In this case, the instance group will create a new VM with the same OS image and with the same hostname identity. During the startup scripts process, it will find the old disks to attach. After that, the DataNode will report its locations back to NameNode, so no application-level replication will need to happen. However, the big data services binaries and configurations deployed by Ambari will be gone since the new VM will have a clean boot disk where BigData binaries and configurations are stored. The Ambari agent running within this VM will notice this situation, and Ambari server can schedule re-deployment of big data services.
- Second, when the cluster scales out by adding more VMs, we will also need to scale out the network disks accordingly. A couple of options can work here as long as additional Disk↔VM mapping is also deterministic. Overall, if we save this mapping elsewhere, not in Terraform or by static Disk/VM name binding, instance groups could scale-out VMs easily. Meanwhile, Ambari can commission new nodes to an existing cluster with some help of Pub/Sub events to trigger.
- The big data service rolling upgrade, in the context of mutable deployment, is not a concern. On first-party (1P), Ambari can do a good job of upgrading big data services without restarting machines. It deploys new BigData binaries and/or configs to the hosts gradually, restarts all dependent services in order, and monitors the upgrade process to make sure everything eventually comes up.
- One challenge is an operating system (OS) rolling upgrade. The use case usually is releasing a new OS image or changing an instance template (e.g. upgrading an instance machine type to a beefy one). Here we need the cloud platform to support OS rolling upgrades. One reason we chose an instance group to manage our VM instance is the built-in rolling upgrade feature. After a VM is upgraded, its instance name might be different. This means part of the state will be different as we use the instance name as the identity to its state. In short, we need to update the mapping of Disk ↔ VM carefully and dynamically. Some corner cases like race conditions will make a static mapping approach (e.g. optimistically tagging disks with instance name) get more complex. Our search for a better solution was towards using a metadata store to save this mapping.
Immutable Container-based Infrastructure
As we mentioned in part one, after exploring both mutable VM-based and immutable container-based infrastructure, we chose the latter. Figure 2 is the flow chart. For provisioning, the Kubernetes cluster itself and its related resources (e.g. IAM, node pools and VPC) in public cloud, the Terraform module and Spinnaker pipeline will be simpler than in a VM-based infrastructure. Again, we still would like to deploy every big data service separately: they are not just in different Pods and StatefulSets; physically they are on different node pools, i.e. different instance groups and thus different VMs. Big data applications, as mentioned above, will be defined in Kubernetes YAML manifest files generated from Helm templates. Potentially, config may use ConfigMap in order to be dynamically injected.
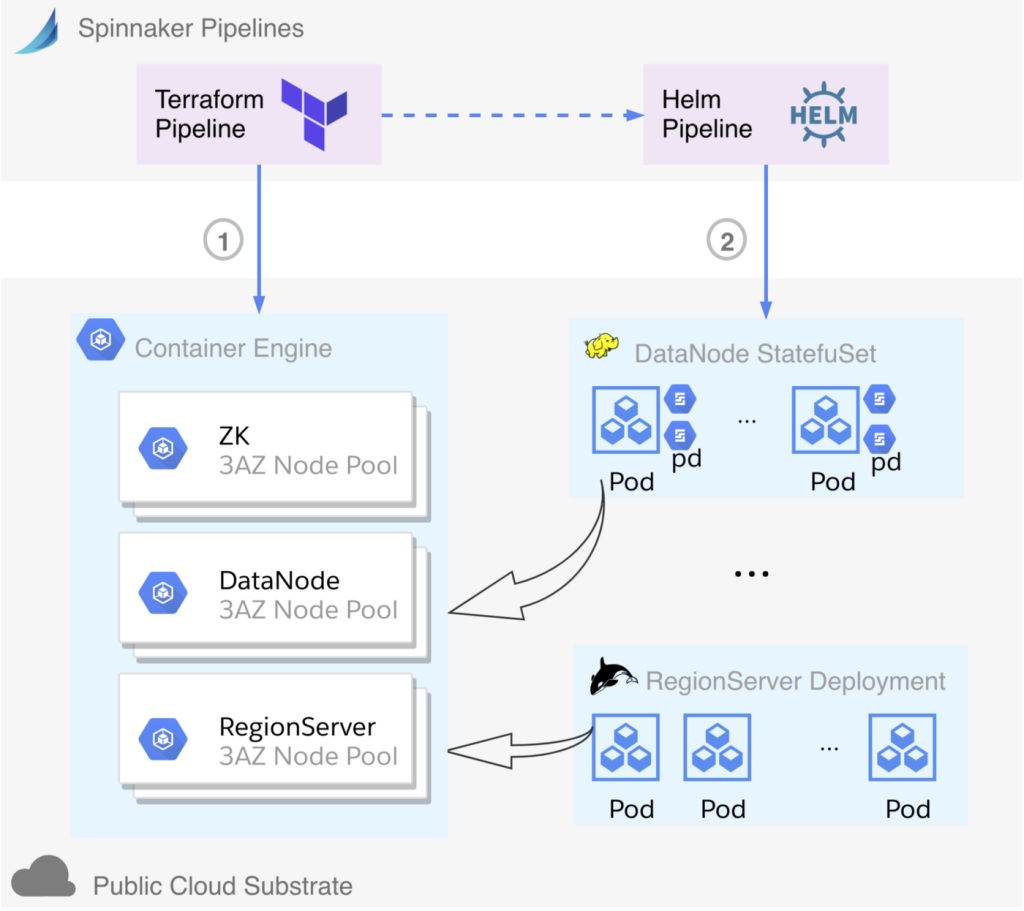
HDFS DataNodes, managed as StatefulSets, are using PDs with Kubernetes primitives like PersistentVolume (PV) and PersistentVolumeClaim (PVC). So restarting a DataNode Pod, rolling upgrading, or scaling out will get the PV in a deterministic approach. Since the PDs are cloud native network-attached disks, managing them in public cloud by Kubernetes is a built-in functionality. Our experience of using a multi-zone Kubernetes cluster with persistent volumes has been improving in public cloud. Kubernetes makes intelligent decisions to provision volumes in an appropriate zone that can schedule HDFS pod, allowing us to easily deploy and scale HDFS stateful service across 3 AZs.
We have the experience of deploying other stateful services like Ceph in 1P Kubernetes where the problem is more challenging as the disks are not network-attached disks, but are local disks of worker nodes. So when you schedule a Pod to use the same local disks, you have to make sure it will go back to the previous physical node. Otherwise, the new Pod loses its “state” and data. For solving that problem, we used something called “local volume provisioner,” which manages the PersistentVolume lifecycle for pre-allocated disks by detecting and creating PVs for each local disk on the host, and cleaning up the disks when released. This is not needed anymore in public cloud where cloud-native dynamic provisioning makes more sense. This is a good example of how immutable deployment for stateful services can be less painful in public cloud environments than in 1P data centers.
In our experience, provisioning infrastructure for stateful services using container-based immutable deployment is better than VM-based mutable deployment. Kubernetes serves as a platform that abstracts substrate-specific infrastructure provisioning away for stateful applications in public cloud. Provisioning Kubernetes itself in a public cloud substrate is relatively less work. Meanwhile, container engines in public cloud-enable faster deployment thanks to their better CD pipeline integration, declarative BigData application deployment, and less operational burden as a managed web service.
Thanks
This blog post is based on a whole team’s work, so we would like to thank all team members of HBase Public Cloud at Salesforce. Special thanks to Dhiraj Hegde, Colin Garcia, Abhishek Goyal and Joe Stump for insightful discussion, thanks to Nikos Sarilakis for review.


