

Salesforce and its customers demand for storage is growing at a dizzying rate. Keeping ahead of this demand is the responsibility of many of our infrastructure teams. We are embracing the Kubernetes development lifecycle for storage services in our first party data centers and across multiple substrates, and we are leveraging Ceph for block storage in Kubernetes.
Ceph is a large scale distributed storage system which provides efficient and durable storage for block images, among other things. Kubernetes (k8s) has supported Ceph block images as Persistent Volumes (PVs) bound to block devices since 2016. With the use of Ceph images as volumes in k8s, we have been leveraging the RBD (RADOS Block Devices) tool and KRBD (Kernel RBD) module. RADOS refers to Reliable Autonomic Distributed Object Store.
There are two common ways for Ceph clients to access volumes/images — one through the kernel driver (KRBD) and another through a user-space library (librbd). In Kubernetes v1.10 we added support for the latter option — accessing Ceph images using librbd. This capability is achieved by using the RBD-NBD (Network Block Device) tool, its related daemon, and the NBD kernel module.
The upstream Ceph community has been actively introducing new features into librbd, while KRBD has yet to catch up on these features. Supporting librbd opens up access to several new Ceph features in Kubernetes environments (e.g., RBD mirroring) and it enables exciting user-space extensions.
This post talks about using Ceph volumes in k8s — and in particular, the exciting new capabilities unlocked by RBD-NBD.
Ceph RBD Volume map, read/write, unmap Lifecycle
Using a Ceph image as a block device in a Kubernetes pod — as a k8s PV — happens in two steps.
- A Ceph image is mapped to a local device, which is then used as a PV by k8s. Once mapped, pods configured with this PV can perform read and write operations on the volume as if it is a local device.
- Read and write requests from within the pod are converted to appropriate Ceph protocol messages and transmitted to a Ceph cluster.
When a Ceph image is no longer used by the pod, k8s unmaps the Ceph volume.
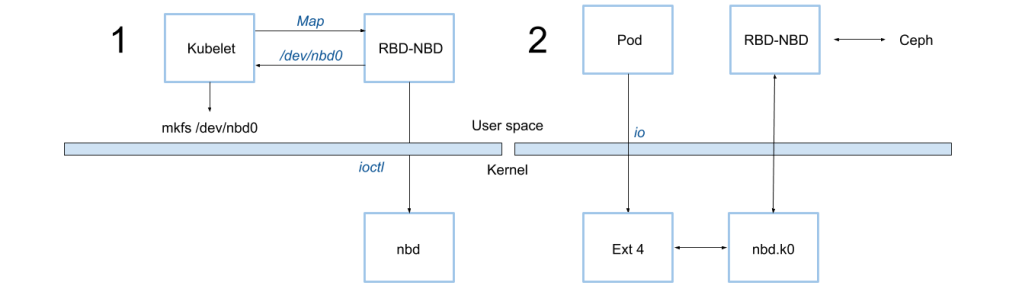
There are two tools that can perform these steps: RBD with the KRBD kernel module and RBD-NBD with the NBD kernel module. Prior to k8s v1.10, the RBD tool and KRBD driver were the only supported system configuration.
Although RBD-NBD is now supported, the default driver remains KRBD to maintain backward compatibility and allow smooth upgrades. So, in k8s 1.10 the kubelet will initially still use the RBD tool to map an image to a KRBD device. If this attempt fails and the RBD-NBD tools and driver are present, then the kubelet will map the Ceph image using RBD-NBD. Once the device is mapped this way, RBD-NBD will serve IO requests on that device.
To set up mapping, RBD-NBD performs a series of ioctls and configures a Unix domain socket for communication with the NBD kernel module. NBD is a generic block driver in the kernel that converts block device read and write requests to commands that are sent through a socket configured by the RBD-NBD tool during mapping. NBD exposes mapped devices as local devices in the form /dev/nbdXX.
Once mapping is complete, RBD-NBD then daemonizes itself and starts listening for read and write requests from the NBD module through the Unix domain socket. It serves these requests by transforming them into appropriate calls into librbd which then performs the actual work of communicating with a Ceph cluster.
Making RBD-NBD the Default for Ceph Volumes on Kubernetes Nodes
For nodes without the RBD tool or KRBD driver present, RBD-NBD will naturally be used by Kubernetes for Ceph volumes. However, for nodes where such tools are present (or must be present) the cluster operator can configure these nodes to leverage RBD-NBD. For example, when leveraging the built-in dynamic provisioner for Ceph volumes, RBD is required to be installed on the master and it is used to dynamically create and destroy Ceph volumes. Similarly, a cluster operator may want the RBD tool to be installed for listing images or for troubleshooting.
While the RBD tool has multiple uses, a configuration leveraging RBD-NBD has no use for the KRBD kernel module. Therefore, the KRBD module can be removed or blacklisted. When the KRBD module is blacklisted, it will not affect the running pods using KRBD. Upon a restart, all further mapping will be performed using RBD-NBD. We recommend this approach.
# To blacklist krbd.
$ sudo sh -c 'echo "install krbd /bin/true" > /etc/modprobe.d/krbd.conf'# To verify that blacklist worked.
$ sudo rmmod krbd
$ sudo modprobe krbd
# Note: modprobe will return success even for blacklisted content
$ sudo lsmod|grep krbd
# Note: on proper blacklist lsmod should return an empty result
Unlocking New Capabilities with RBD-NBD
RBD-NBD allows mapping images created with features unsupported by the existing KRBD kernel module. For example, exclusive-lock, object-map, and fast-diff. Presently Ceph images with these features must be statically provisioned, since the existing rbd-provisioners reject these features during dynamic provisioning. We intend to relax these constraints in the rbd-provisioners, now that RBD-NBD is supported.
RBD-NBD also makes using and experimenting with new Ceph features easier. For example, Ceph uses a protocol called cephx for security. The primary goal of the protocol is to provide message integrity and user authentication, but it is vulnerable to man-in-the-middle type attacks that perform message replay. We are currently working on adding TLS support to the Ceph messaging layer, leveraging librados and openssl. Such work would be extremely difficult in KRBD as commonly used libraries, such as openssl, are not part of the Linux kernel.
Nitty Gritty Details… and Checking that RBD-NBD and RBD Work
Use these resources if you want to get the Ceph software, install it, and make sure that it works. This section is most useful to people who want to take advantage of RBD-NBD in Kubernetes.
Ceph software for each of the various releases can be obtained here. For the purposes of this post we’re going to focus on the Jewel release, on CentOS-7, available here. The RBD tool which is needed by the Kubernetes master for dynamic provisioning is provided by the ceph-common package. The KRBD module is provided as part of the kernel package. RBD-NBD is a separate RPM, and it depends on basic Ceph libraries such as librbd and librados. The latest source code for RBD-NBD can be found here.
After installing RBD on the k8s masters and RBD-NBD on all k8s nodes, you can validate your setup using the following commands:
# Check that master has operational rbd utility.
$ rbd -v
ceph version 10.2.9 (2ee413f77150c0f375ff6f10edd6c8f9c7d060d0)# Check that all schedulable nodes have operational rbd-nbd utility.
$ rbd-nbd -v
$ sudo modprobe nbd
If all these commands respond with success (exit code 0), this is a good indicator that your systems are set up and ready to use RBD-NBD.
# Commands for testing that rbd-nbd has properly mapped a ceph
# image for a scheduled pod.
# For a pool test_pool and image test_img, we can verify if
# rbd-nbd has correctly mapped it by running the following
# command on a host where the pod that needs the volume is scheduled
# and get an output similar to below:
$ mount|grep test_img
/dev/nbd0 on /var/lib/kubelet/plugins/kubernetes.io/rbd/mounts/test_pool-image-test_img type ext4 (rw,relatime,seclabel,data=ordered)
RBD-NBD Marks the Spot
You’ve made it to the end of the post! Now you know about the lifecycle of Ceph RBD volumes in k8s, how to leverage RBD-NBD with k8s v1.10+, and maybe you’ve even made the necessary changes and validated them in your own cluster. Keep an eye out on Medium for the latest from Salesforce Engineering on our work with Kubernetes and Ceph.
This blog post was written by Ian Chakeres and Shyam Antony, two members of the Salesforce working on running scale-out storage technologies on top of Kubernetes. Edited by Peter Heald and James Ward.
Follow us on Twitter: @SalesforceEng
Want to work with us? Let us know!



