In our Engineering Energizers Q&A series, we explore the paths of engineering leaders who have attained significant accomplishments in their respective fields. Today, we spotlight Dima Statz, Director of Software Engineering at Salesforce, who leads the development of Salesforce’s new Speech-to-Text (STT) service. STT leverages advanced speech recognition technology to provide real-time, accurate transcriptions of spoken language, thereby aiding businesses in better understanding customer interactions and enhancing their communication strategies.
Explore how Dima’s team addresses technical challenges, such as developing real-time transcription services that balance low latency with high accuracy, ensuring new features do not compromise existing functionalities, and much more.
What is your team’s mission?
Our mission is to develop text-to-speech and speech-to-text capabilities for the Salesforce AI Platform, empowering developers with out-of-the-box speech AI services for efficient and rapid conversational AI application development.
Our team improves the accuracy and functionality of STT, ensuring it can seamlessly convert spoken language into text. This precision is crucial for analyzing customer interactions and optimizing communication processes. Through our efforts, we strive to help businesses enhance their service delivery and gain deeper insights into their customer engagements, ultimately driving better business outcomes.
What was your team’s most significant technical challenge?
Recently, our team faced a significant technical challenge: developing a real-time transcription service that combines low latency with high accuracy. Real-time transcription demands quick processing — delays over 1-second render captions ineffective — yet accuracy cannot be compromised even when delivering results within 500 milliseconds.
To tackle this, we adapted OpenAI Whisper models, an open-source solution engine originally designed for batch processing. Whisper, known for its 95% accuracy rate with the LibriSpeech ASR Corpus, typically handles full audio or video files. Our goal was to enable it for real-time applications.
How does STT handle audio to maintain both speed and accuracy?
We engineered a streaming solution using the WebSockets protocol, allowing audio to be processed in ‘chunks’ as it arrives. This setup maintains sub-second latency while enhancing accuracy through a method called the tumbling window technique. This approach processes audio in temporal windows, segmenting based on cues like speaker changes or pauses. It provides immediate, partial results and more accurate final results once enough context is gathered or a significant audio cue is detected.
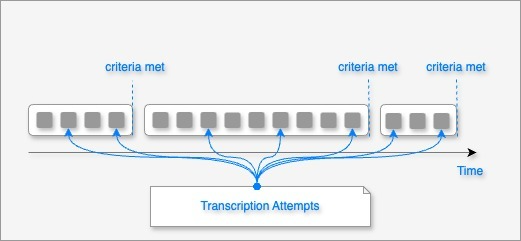
Temporal windows of audio chunks.
The process involves:
- Chunk Arrival: Audio chunks enter a processing window upon arrival.
- Window Processing: Chunks are transcribed to yield a partial result.
- Continuous Processing: As new chunks arrive, the window expands, allowing the transcription engine to refine results using additional context.
- Pause or Speaker Change Detection: Detection of pauses or changes triggers the marking of a partial result as final.
- Finalization: The window closes, and the final transcription is sent to the client.
This cycle ensures that our real-time transcription service is both swift and precise, meeting the needs of dynamic audio or video communications.

Partial result flow.
How does STT ensure that new features do not affect existing functionalities?
We prioritize maintaining system stability while implementing new features through rigorous testing protocols. Our approach includes unit testing, where we enforce a minimum of 95% code coverage. This is complemented by a gated check-in mechanism that tests the source code before it merges from the feature branch into the main branch, ensuring the main branch remains stable and “healthy.”
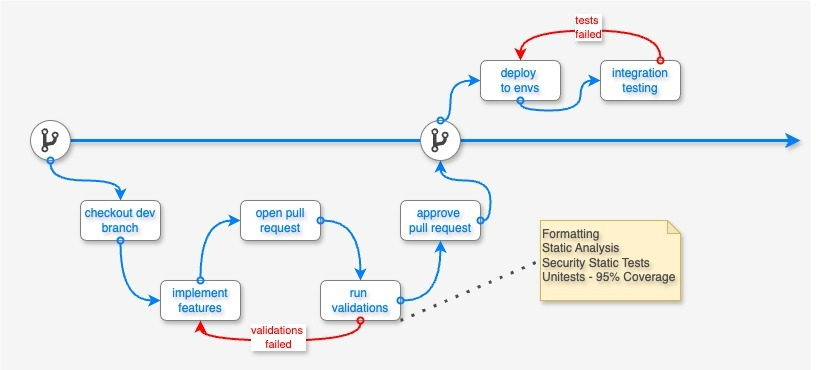
Development flow.
What measures does STT take to maintain high code quality and security?
To maintain high code quality, we employ static analysis and automatic code formatting. Static analysis helps in the early detection of bugs, significantly reducing debugging time and enhancing the reliability of our software. Automatic code formatting ensures consistent coding standards across the team, facilitating easier code reviews and collaboration. For security, we conduct static security analysis to identify and address potential security risks, code problems, and compliance issues early in the development process.
How does STT handle integration testing and performance benchmarking?
Integration testing is integral to our CI/CD process, utilizing the Salesforce Falcon Integration Tests (FIT) framework to ensure seamless interaction between components and reliable end-to-end functionality. Performance and accuracy are benchmarked using metrics like Word Error Rate (WER) and latency, with daily benchmarks run in higher environments using datasets like LibriSpeech ASR Corpus. These benchmarks validate that new versions meet our stringent performance and accuracy standards before release, ensuring the high quality of STT.
What ongoing research and development efforts are aimed at improving STT’s capabilities?
STT is advancing its capabilities to include AI-driven analytics beyond traditional transcription services. It currently transcribes audio and video calls to aid in performance analysis and provide insights during sales calls. The service is evolving to extract data for advanced analytics in Data Cloud environments, enhancing AI system feeding.
The demand for high-quality, extensive data has grown with AI evolution, focusing traditionally on structured and semi-structured data. However, the unstructured data from conversations, like those in video and audio formats, presents a significant opportunity despite being challenging to analyze.
Efforts are underway to integrate this unstructured data from platforms such as Zoom, Google Meet, and MS Teams into analytics platforms seamlessly. The goal is to develop capabilities for data analytics platforms like Apache Spark to process audio and video data as efficiently as structured data. This development aims to enhance understanding, improve processes, and automate business operations through advanced AI applications.
How do you gather STT feedback from users and how does it influence future development?
STT collects user feedback through three main channels to inform its development and improve customer satisfaction:
- Public Slack Channel: This platform is used to announce new features and engage with users for testing and feedback. Direct communication captures user preferences and initial reactions to new features’ usability.
- Behavioral Data Analysis: User behavior within STT is analyzed to understand how the platform is used. This analysis highlights usage trends, feature adoption rates, and areas of difficulty. Insights from this data guide enhancements that directly address user needs.
- Salesforce Grand Unified System: Used for collaborative problem-solving, this system gathers feedback through support tickets and team discussions, providing insights into user challenges and areas for improvement. This feedback is crucial in shaping the development roadmap to exceed customer expectations.
Learn More
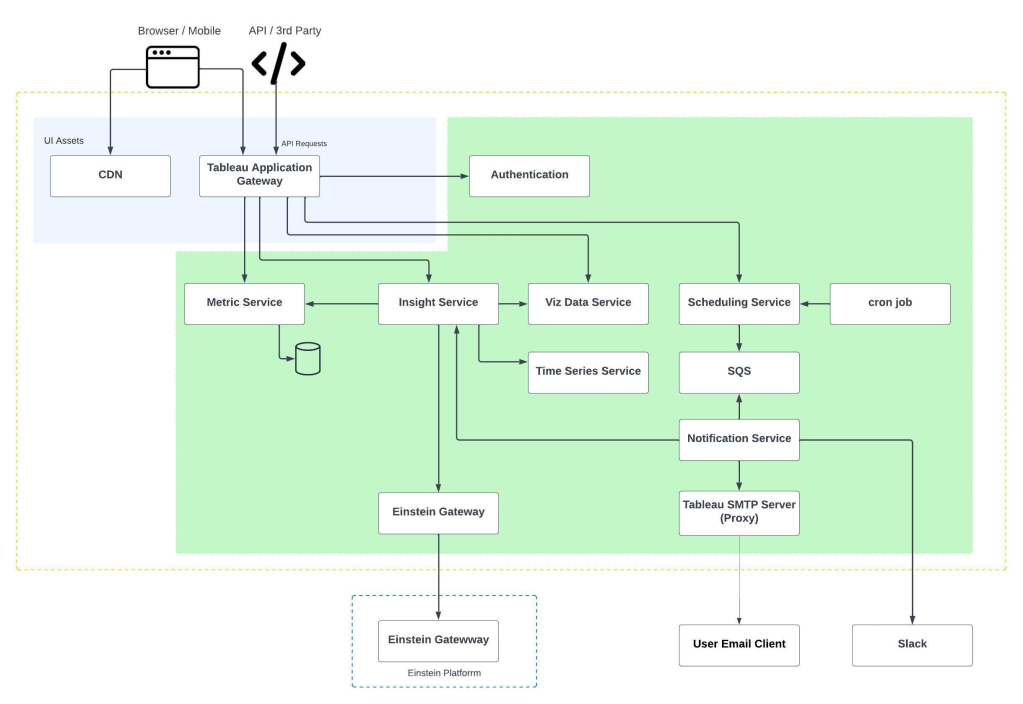
- Hungry for more AI stories? Learn how the new Einstein Copilot for Tableau is building the future of AI-driven analytics in this blog.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.