Salesforce Einstein operates many machine learning applications that cater to a variety of use cases inside Salesforce — vision and language, but also classic machine learning (ML) approaches using tabular data to classify customer cases, score leads, and more. We also offer many of these ML solutions and applications to our customers. Each one of our ML applications needs to work reliably for potentially any of our business customers, so we’re faced with the challenging problem of scaling to tens or in some cases hundreds of thousands of independent machine learning model lifecycles, with at least one model per customer. Furthermore, we have strong isolation requirements for our customer’s data, meaning the lifecycle of both the data and the models depending on that data, needs to be independent to meet compliance and legal requirements. We call this problem the multi-tenancy scaling problem. It defines the fundamental scale challenge we face across our stack, first and foremost in our ML operations and infrastructure, for both offline and online environments and services, but also in the lower level model architecture design and choice of machine learning approaches.
Multi-tenancy and EFlow
The multi-tenancy problem and the need for independent models, at least one per customer, translates operationally directly to managing hundreds of thousands of ML flows reliably with minimal disruption and overhead. Over several years we managed, operated and evaluated several obvious options and tools prevalent in workflow management, including Airflow, Argo, and Azkaban. While operating on them, we realized the hard way, that these historically popular solutions, while very rich in terms of ecosystem/integrations, and easy to adopt also have critical gaps in reliability, high availability, and scale, along with core implicit assumptions which made them non ideal for us, given our multi-tenancy problem and scale numbers. In addition, we have a philosophy of operating a central managed service for all ML flows of all our applications, large or small, rather than having ML application teams provision and maintain self-serve clusters for ML flow management. As a result, we built and have been operating EFlow, our internal flow management system, for several years. In this post, we will share some of its fundamental principles that lend it the scaling properties required for supporting our numbers.
EFlow Core Principles and Primitives
Our system enables composing and executing complex workflows/DAGs with several types of steps. One common type of step allows invoking remote large scale computation systems for generation of datasets, models, or evaluations. Another typical step type performs registration of computation results in dedicated result storage metadata systems (i.e. Model Store for models, Data Lake metadata for datasets and so on), and another common step type enables human-driven processes of approvals or evaluations, be that from application teams or from end business customers. In general, our flows represent the lifecycle of key ML entities (i.e. lifecycle of models or datasets, associated with an application/use case), and the underlying assumption is that these lifecycle stages can take a long time. EFlow is designed not to consume resources during or in between these lifecycle stages. The two core principles underpinning EFlow are:
- Separation of Flow State vs Compute — Steps in our flows don’t perform computation — they always invoke/delegate to remote computation systems (Spark, K8 Tensorflow clusters, etc.) and listen to events from those systems for results (such as computation completed/failed). Those events contain references of computation results.
- Steps handle metadata, not data — they always work with metadata/references of inputs or results, typically representing Datasets, Transformations, Evaluations, or MetricSets. In essence, they always handle pointers to large datasets/models, etc.
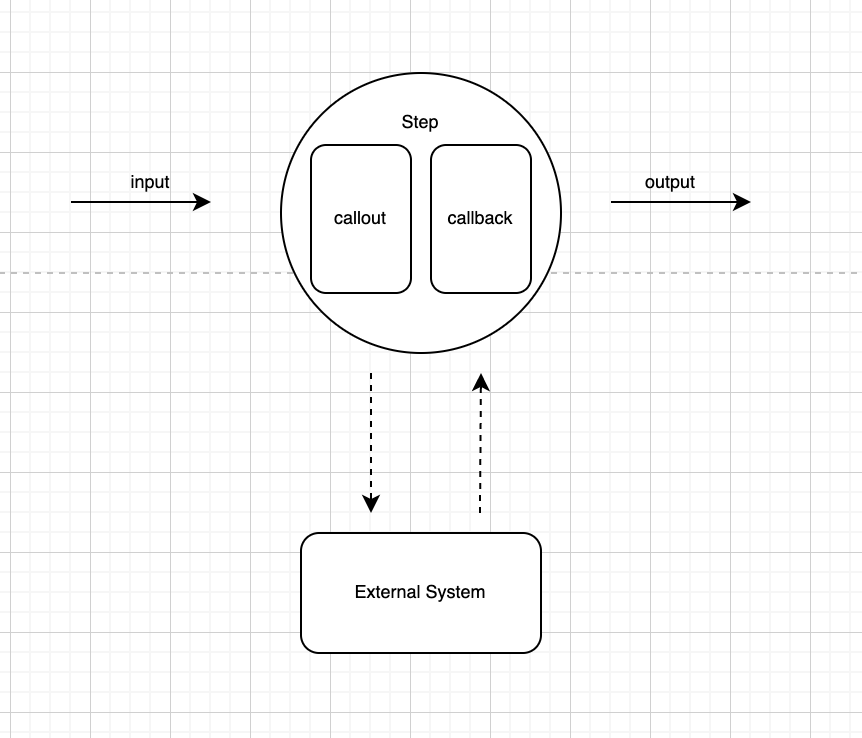
The two fundamental principles above ensure horizontal scalability where:
- very large numbers of concurrent flow executions (in the hundreds of thousands) can be handled very well by our system, a core requirement for our unique multi-tenant use cases at Salesforce.
- flow executions with very long durations can also be handled without issues (they can be active for months or, if necessary, for years). Technically, we don’t have any underlying limitation on execution duration. Our flows lend themselves to be used for very long ML lifecycle transitions (things like complex live experiment progressions can take months).
While our system is comparable in functionality with other popular solutions (Airflow, Argo, Azkaban, etc.) we differ greatly in scaling philosophy, availability, and implementation.
Steps: What vs. How
Steps represent our standard units of work for flows. They involve invoking external systems for either immediate or asynchronous processes. Yet, in the ML lifecycle, we only perform a few well-defined types of operations regardless of underlying implementation or which exact external systems (e.g. computation engine) are being used. For example, for transforming and outputting datasets, we have to feed source data(sets), and a transformation definition, with the result/output representing the transformed datasets. Similarly, for generating models, we input source datasets and a transformation definition, with model(s) as output; for evaluations we would have the same, but with model or data evaluation results as the output, and so on. The input/output types represent the what, the functional contract of the step. In our step design, we differentiate between this contract, representing what the step is doing vs the actual implementation, representing how the step is doing it. One benefit of designing steps this way is to abstract, for example, the concrete computation engine (Spark, vs Tensorflow clusters, vs. …) and even whether computation is being performed on a batch system vs a (near-)realtime system. This allows, among other things, for highly configurable flows (they are defined as JSON) leveraging few well defined steps with clear semantics allowing for strongly typed validation. Splitting the what from the how, along with a consistent separation between compute and flow state, also opens up having flows that represent ML lifecycles that span the offline/online divide and allows tracking models that may be changed/enriched by very fast online learning/processing.
EFlow Architecture
EFlow follows an API-first philosophy very consistently. All our functionality, from authoring flows to instantiating, managing, and tracking flow executions, is surfaced via APIs that have guarantees around backward compatibility and are associated with strong SLAs. We have three major components, each composed of multiple internal microservices. Each single component is setup with high availability and resiliency in mind:
- EFlow Engine: manages flow state/lifecycle; what is the flow state at any point in time and transitions from one state to the next?
- EFlow Scheduler: manages distributed scheduling/cron capabilities, essentially determining what flow execution should start next; a fancy distributed cron job.
- EFlow History: tracks executions for surfacing to end users and enables observability with a UI
EFlow Engine
EFlow Engine is responsible for managing flow state transitions. It is composed at a high level of an API layer, a worker layer, a database, and an event bus. The flow engine is an event driven system; there is no part of the system that is waiting idle and blocking resources while, for example, computation is happening. The workers are the components performing step executions, which in our case are only lightweight calls to external services. They also advance flow state via the events. The full flow state is kept in a database record. On each event, the associated flow state is retrieved by the worker and initialized, and, once the event is applied, the state of the flow is advanced and stored back. We scale by increasing the number of shards in the event bus and the associated workers processing events from the bus. The event processing for flow transitions ensures that the only real limitation for our system is the flow state size, which primarily affects the speed of event processing.
Flow state size is almost entirely dependent on the number of steps in a flow and the size of step inputs and output objects. We have various ways to cope with this limitation. On one hand, we enforce that input and output objects represent metadata, not data, as described in the core principles above. In addition, when there is a need for a flow to have a large number of branches- in the hundreds, or a few thousands-with each branch being similar to a flow of its own (e.g. segmentation or large hyper-parameter tuning flows), we express these branches as subflows independent from the parent flow. Their state is stored in separate records and their processing is independent, hence ensuring the overall size of the parent flow is still very manageable.
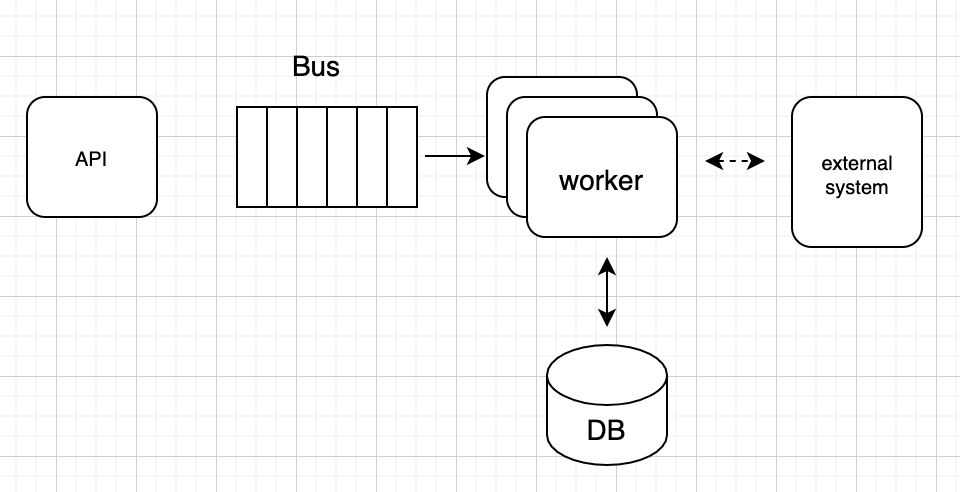
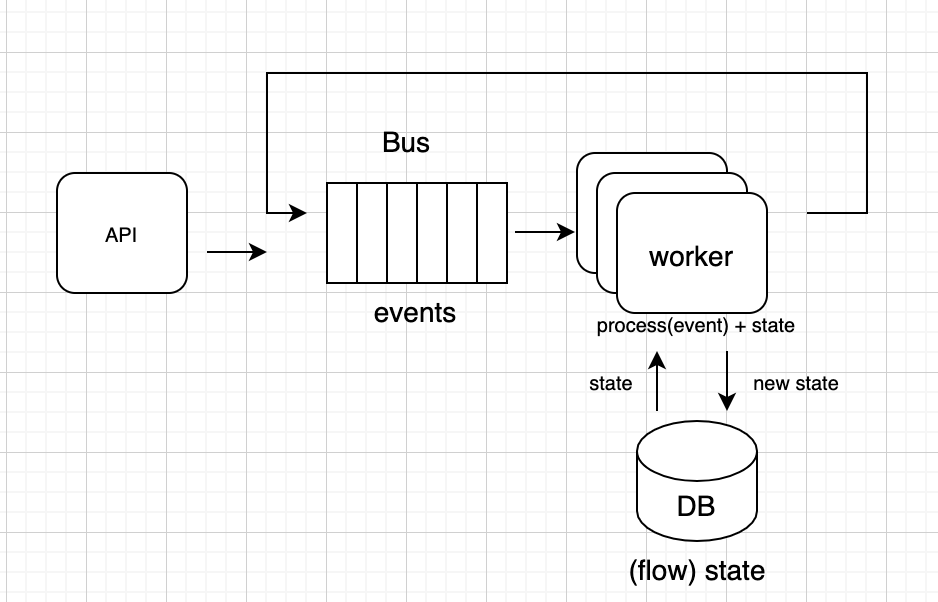
Eflow engine conceptual view (left), event processing lifecycle (right)
EFlow Scheduler
Our second major component is the scheduler. It is the component that provides the heartbeat of the entire ML platform. Its primary role is to manage flow executions running at a particular cadence, essentially determining when a flow execution should be triggered, as well as to handle step level retries, backoffs, and timeouts. We think of our scheduler as a simple yet highly scalable and distributed cron. The key approach enabling the scalability properties that we require to support our numbers is partitioning the database tables that manage our schedules, with each partition being processed independently by what we call loaders. For each scheduling record, we store when it should run next (next execution time), as well as its partition name. Each independent loader continuously processes the associated partition with records filtered and sorted by nextExecutionTime. The partitioning strategy allows us to scale to very large number of schedules simply via adding partitions and loaders.

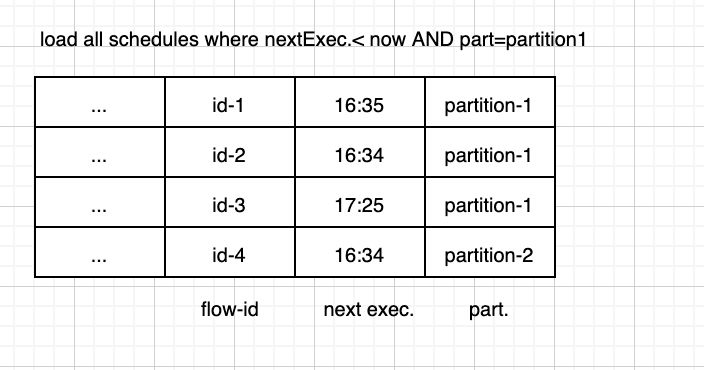
EFlow scheduler architecture (left), next execution time and partitioning (right)
EFlow History
The last piece of the puzzle is our flow history component, which tracks historic execution and flow events and enables a UI to visualize and query state for end users. We follow a consistent separation of our history component from the flow engine, since the history component is used by our users and enables ad-hoc querying for potentially exhaustive searches for months’ worth of data. It is connected via a bus to receive events from the flow engine, and it consumes the bus events to reflect and track all executions. End users see our history component when they interact with our UI.
Towards hundreds of millions
After a few years operating EFlow, we believe that separating lifecycle from computation, in addition to separating the what vs the how (function vs implementation), are critical patterns that can enable scaling and managing millions or hundreds of millions of models. That is because flows are represented simply as database records and bus events; hence, there is no limit to scaling concurrently running flows, especially if those flows represent models that are enriched by cheap and fast moving user-specific online or edge computation processes. We believe managing this extreme number of flows, each representing data/model lifecycles, similar to what we have to handle at Salesforce, is going to become an increasingly common pattern including at large consumer companies and not just an outlier mostly encountered in the enterprise space. The drive towards larger numbers of models is becoming more apparent as intelligent solutions need to be more personalized and provide an almost exact mirror of the users they are serving.
From Models to Agents
A larger number of personalized models has induced us to think of ML solutions in terms of agents, agent lifecycle, and agent populations, and less in terms of low level models. This shift in abstraction from models to agents is required also as holistic intelligent solutions are composed very often from more than just one model, each with a different lifecycle, that work together to achieve certain behavioral patterns. Managing and following agents from their creation to their post-deployment stages is beneficial, especially as we are going towards a future where users are represented by dedicated and isolated/independent intelligent learning processes happening online or at the edge. For example, in modern model architectures, we commonly find patterns where many models/agents have a common trunk trained on large scale global data representing some general model/understanding about the larger world or environment (i.e the general english language in NLP models), and a user-specific head trained on user-specific data representing task/user specific understanding and derived representations (common trunk and user-specific higher layers or heads are typical in transfer learning regimes and deep learning architectures). Another pattern is for an agent’s models to always be trained from scratch with just a single user’s data. Yet, in both of these cases we still end up with a need to manage an agent or model per user, meaning potentially millions of models for some domains.
Our architecture lends itself very well to handle this shift in philosophy and to be able to scale to millions or hundreds of millions of independent agent lifecycles, defining and tracking not just how they are created/trained, but also guiding their entire life progression until retirement. That means spanning the divide of the offline/online environments and allowing for extremely personalized model lifecycles. In addition, thinking about intelligent solutions in terms of agent and agent populations enables us to provide a cross-generational view of lifecycles, enabling multi-generation optimization of entire agent/model populations. This multi-generational view caters in principle to evolutionary or bayesian optimization processes that are very useful for large-scale autoML to span to very long time ranges — on the order of weeks, months, or even years for populations of millions of models. Ultimately, key to this shift towards more personalization of models is the ability for ML platforms to handle independent model and agent lifecycles at massive scale, something that lies at the foundations behind the EFlow structure.
Acknowledgments
Special thanks for their contributions and leadership over the years for shaping and influencing this unique ML component: Radhika Pasari, Hormoz Taravern, Sonika Arora, Chandrashekhar Vijayarenu, Swaminathan Sundaramurthy, Rama Raman, Paul Kassianik, Alexander Nikitin.