We humans are always looking for something, aren’t we? Happiness. Information. Optimization. Car keys.
Over the millennia, people have searched in all kinds of ways. Seekers have tried everything– spiritual pilgrimages, meditation, walking on hot coals … even yogalates. Thankfully, in the modern world, we don’t have many occasions to walk on hot-coals (though, I think we could probably use a bit more yogalates). The advent of universal web search (e.g. Google and … uh, Google) has trained us all to expect easy answers to hard questions, in the blink of an eye.
I don’t know about you, but search is my first instinct when I’m doing any kind of computering. For example, I have no idea what “folder” most of my apps are stored in; when I want them, I hit a keyboard shortcut to bring up a quick search, and type the first couple letters. Similarly, I don’t even have to memorize or bookmark the URL for my yogalates studio; I just type “yogalates austin” into a web search and it’s in the first few results. I don’t even have my wife’s first name memorized! (Kidding … I’m pretty sure it … starts with a J.)
If you know anything about Salesforce, you probably think of it as CRM (Customer Relationship Management) software–something that business people use to connect with their customers, via activities like tracking sales calls and running reports. This is indeed true, but believe it or not, the most used single feature in Salesforce is actually … search! With more daily active users than any other feature, and several hundred terabytes of indexed data, it’s actually totally central to how the whole system is used.
How is search different from other data storage and retrieval? Let’s see!

Why is search different from other data access?
There are SO MANY ways to store and move data–files, databases, document stores, caches, message queues, etc. These are all great for their own purposes, and we’ve covered several of them in previous episodes of the Architecture Files (like this one, and this one).
Search isn’t really a different pool of data, but rather a different way of organizing and accessing data. For a quick illustration, imagine a banana stand that stores all kinds of important information — the items on the menu, individual food orders, stock counts, amount of cash lining the walls, etc. Say you wanted to find any records, in any of those entities, that contained the term “banana”. A traditional SQL database query might look like this:
SELECT id FROM Menu WHERE field1 like ‘%banana%’ OR field2 like ‘%banana%’ or …
UNION SELECT id FROM Stock WHERE field1 like ‘%banana%’ OR field2 like ‘%banana%’ or …
UNION SELECT id FROM Order WHERE field1 like ‘%banana%’ OR field2 like ‘%banana%’ or …
UNION …
In other words, you’d have to explicitly spell out all the names of entities and fields that you want to look in, and direct the database engine to try to find that string anywhere within the field of text. And while this massive SQL query would be a pain in the banana (even formulating the physical query plan would be a nightmare!), the real problem is how it would perform at query time. Even if you automatically generated the query and cached the physical plan, it would still be dog slow, because all those wildcard string comparisons would incur a huge cost every time you went looking for your banana.
And that’s just one term! Imagine searching for multiple terms, like “there’s always money in the banana stand”!
So, that’s why search is actually not done this way at all. The typical model is that as data is created or changed in its source system, you also feed a copy of that data into something called a “search indexer”, which then creates and stores a data structure called a reverse index. That looks something like:
“banana”:
Orders Table
Row 3669 Field 19 Position 1
Row 77381 Field 3 Position 5
…
This is way over-simplified, but you get the basic idea: it’s like an upside-down version of the data, where the string points you to the location, rather than the other way around. Queries can be answered much more quickly by just accessing this data structure, rather than scanning through all the source data. This makes search possible, by doing all the hard work ahead of time!
(To split hairs just a little bit: typical databases do also offer the ability to build an index on the values of data fields; in fact, this is critical to a system’s ability to run most common queries with filter predicates, not to mention joins. The difference is that in the case of a dedicated search index, these fields are tokenized–that is, broken up–into smaller chunks like individual words, and the query engine can be completely optimized for this method of returning results. You could theoretically do something similar with most relational database engines, but the resulting system wouldn’t be very performant as either a database or a search engine!)
Now, if it were that simple, we’d be done, and we could all head off to our Yogalates classes. But it turns out there’s more to search quality than just finding strings of text in other strings of text.
For example: a search might return hundreds (or millions!) of results, and no user is going to page through all of them. So, the ordering of the results you return is extremely important — a problem called relevance. There are many ways to compute relevance, even differing from user to user (what’s most relevant to you might not be the same thing that’s relevant to me.) And this is just the tip of the iceberg — you also have to think about synonyms, misspellings, and a host of other problems. Search is a pretty deep space, and there’s lots of work just to get it up to the baseline of what modern internet users expect.
Let’s talk about a couple of the other interesting complexities that come up.

Search Is Schematic
If you’ve read the previous Architecture Files episode about Metadata, you know that the schema of entities in a domain is an important concept; it’s how we represent the semantic concepts of the real world directly in our computer systems. You can say things about a person (like name, email address, etc) that you can’t say about a food like bananas. (Or, rather you can say them, but people will think you’re pretty odd if you name all your bananas.)
It might not be obvious, but this idea of schema is important in search, too. Every search implies some schema in its results, whether you know it or not.
“But Ian!”, you say, “I don’t see any schema when I do a web search!” Au contraire! Your friendly neighborhood web search isn’t just giving you back generic “results”; it’s giving you results from an entity called “Web Pages”. When I search for “banana”, I see:
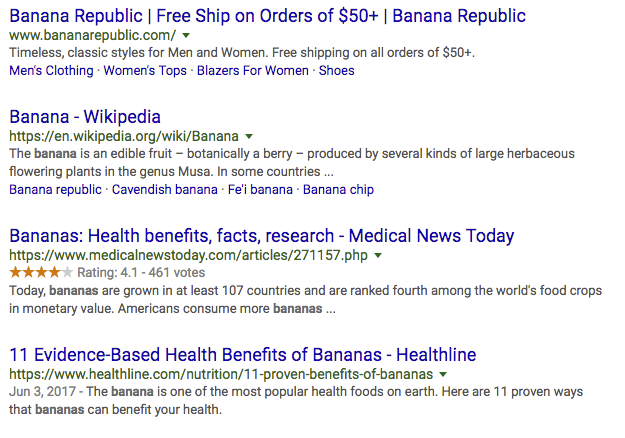
Each of these results is a specific kind of thing: a website. No matter what you search for, you get back a list where each thing on the list is … a website.
(As an aside: you’ve probably also noticed that sometimes, a clever search engine like Google will get a little bolder, and use a dash of machine learning to detect the real-world entity you’re probably searching for. In this case, it detects that banana is a food, and shows you nutrition facts, which is something you can say about a food, but not a web page. But that’s in addition to the web page results, which are the main attraction).
In a system like Salesforce, which has tons of structured data entities with business meaning (like Accounts, Contacts, Activities, etc) search results are almost always returned in terms of these entities. When you search for “banana”, you see results broken down by entity: Accounts (like “Banana Republic”, if they’re a company you sell to), People (“Johnny Bananaman”, if he’s one of your contacts), Collaboration Groups (like “Airing Of Bananas”, which is actually a real group in our own Salesforce instance because … well, it’s a long story.) You get the picture: a system with richer data structure can express search results directly in terms of that structure.
The entity schema also has a lot to say about the behavior of the search results: for example, which fields are searchable, which properties to show as facets, etc. Within CRM Search, this metadata is exposed on objects (e.g. the enableSearch flag), and the specifics of how search results are presented back for an entity are in SearchLayouts.
And, as one particular user of a system, you might want your personal interests to influence which entities you get results from by default. If I’m not a Salesperson (which I’m definitely not), then I might prefer my search for “banana” to return results from the entities I regularly interact with in the system (like collaboration groups) rather than the more sales-oriented entities, like, Accounts and Contacts.

One search system, or many?
While most religions generally want you to believe that they’re the only way to eternal paradise, a quick glance around the globe will show you that this isn’t a given; there are plenty to choose from, and each has its own particular selling points.
Search technology is similar, in that it’s not a “one-size-fits-all” deal. Most large deployments (including Salesforce) have a gaggle of different search systems, each covering a different subset of use cases. For us, the two most prominent search engines, which power 80% of our queries, are:
- CRM Search (which powers Sales Cloud, Service Cloud, etc.); and
- Commerce Storefront (which power the consumer product search)
Outside of that, there are also dozens of other search systems, covering area like social media feed search (in Marketing Cloud), Trailhead, Help & Training, Quip, App Exchange, and more. (And on top of that, there are also several internal-facing search systems, for things like our bug tracking system, our IT help desk, etc.)
These systems run on a variety of underlying software projects (including Apache Solr, Lucene, Elasticsearch, and more), but more importantly, they are designed to behave differently. While they all follow the same basic reverse index pattern I described above, there are a variety of factors that distinguish them.
For one thing, not all searches are supposed to behave the same way. At base, the job of a search system is to intuit what the searcher is really looking for. And that’s going to depend on the context! Searching for products on a store website is a pretty different behavioral pattern from searching through your friends on social media.
For this reason, most search systems have some degree of business logic built right into the engine. They’re programmed with behaviors that are specific to certain uses — for example, the customer-configured ranking in Commerce Cloud storefront, which allows merchants to tailor the ranking of search results to highlight specific products (say, to improve top-line revenue, or maximize unit-sales using a price elasticity analysis). The goal is to get the searcher (and the searchee!) what they want, as quickly as possible.
Systems might also have to accomodate things like permissions. For example, in our CRM products, the search system pays attention to our complex sharing logic (which allows airtight control over who can see or do what, even within a single tenant). That means that if you don’t have access to see a record, it won’t be returned by the search, even if it would be a perfect match for your query. (And, you’d better believe that doing that efficiently and at scale is no simple problem!)
Search systems also differ in their needs for scalability. The amount of processing you need for real-time search of Twitter’s firehose is quite different from the amount you need to power searches of our (mostly static) help & training content. A consumer-facing product search has huge query volumes, but a (relatively) small amount of data (a product catalog), and thus might set up lots of index replicas. On the other hand, a use case with a high data volume but fewer queries (like, say, a Data Management Platform, or DMP) would have a few larger shards, to control the number of indexing threads.
Similarly, we might also want to control indexing latency, the delay between when data is changed and when the modification appears in the search index. Optimizing for this parameter has huge impact on the underlying architecture; if you’re content with your data being re-indexed each night, that’s a lot less demanding than when you need latency in seconds or minutes (which is required for many enterprise use cases, like searching call center data).
There’s also the question of whether the domain to be searched is multitenant or not (If you’ll recall, we covered multitenancy in the last episode, and now would be a good time to reread that, if you have no idea what I’m talking about). Salesforce CRM search is multitenant (obviously), as are a lot of other search functions embedded in our products, like Commerce Cloud search, Quip search, etc. But other things, like our search for Help & Training or Trailhead aren’t, because the subject matter is all one big body of public data, shared by everyone.

Coexist
So, it’s clear that we’ll probably always have lots of different religions, and we need them to coexist because that’s much nicer than everybody killing each other.
Similarly, it’s clear that there’s a case for having multiple search systems in an organization. Even if you share one search implementation, you’ll likely still have different domains for behavioral and physical reasons.
But that doesn’t mean you should push all that complexity down to the end users of your system. Instead, you should do what you can to make sure their perception of search is more integrated. A couple ways to do that include:
- Federation, which means using a query-side API protocol (such as Open search protocol) across your different search silos, physical installations, and even tenants (in cases where you’ve got access to more than one).
- Unification, which means giving users a consistent experience when they search, no matter which domain they happen to be in. In practice, that means unifying common functionality and features like Spell Checking, Multiple Language Support, Typeahead Suggestions, and Result Faceting. It also means you want the non-functional aspects of search — that is, the QOS (Quality Of Service) things like performance, availability, etc. — to be consistently good as well.
Of course, like religious harmony, both of these things are easier said than done. For example, universal spell correction sounds nice, but if you use a machine learning model that’s trained on one domain (for example, enterprise software), it might not be very useful in a totally different one (say, commerce and consumer applications). If I typed “banadas”, did I mean “banana”? Or “bandana”? Or “Antonio Banderas”? This depends to a large degree on the details of what kind of search system this is–that is, what you’re trying to help people find.
Conclusion
Search is more than just “another way to access information”; it’s central to the way modern users think about navigating around the information spaces they use. That means it’s central to any system’s software architecture, too. At Salesforce, we’ve been building large-scale search systems for decades, and as we grow, we’re thinking about what search means for the coming decade as well.
Do you have experiences with search? We’re always hiring and we’d love to hear from you if this kind of problem sounds like something you’d love to help solve.
(Big thanks to all those who contributed heavily to this episode, including many of our search experts here at Salesforce: Anmol Bhasin, Dylan Hingey, Gennadiy Geyfman, Ilan Ginzburg, Jeff Fitzgerald, Jordan Lutes, Matthew Canaday, Nishant Pentapalli, Tim Gilman, and Victor Spivak.)