By Shafiq Rayhan Joty and Scott Nyberg
In our “Engineering Energizers” Q&A series, we examine the professional journeys that have shaped Salesforce Engineering leaders. Meet Shafiq Rayhan Joty, a Director at Salesforce AI Research. Shafiq co-leads the development of XGen, a series of groundbreaking large language models (LLMs) of different sizes.
Delivering critical general knowledge, XGen serves as the initial foundational model from which Salesforce AI teams use, adapting the model through fine-tuning or continued pre-training to create safe, trusted, and customized models for distinct domains and use cases, supporting sales, service, and more.
Shafiq dives deeper into XGen’s role as a foundational model.
Read on to discover how Shafiq’s XGen team pushes the limits of LLMs to drive AI innovation and meet Salesforce customers’ evolving needs.
What technical challenges did the XGen development team encounter?
From performing massive data collection to training the colossal model and fine-tuning it for unpredictable user needs, XGen’s development journey posed multiple challenges.
- Collecting the data: To train the model effectively and at a large scale, the team required a vast volume of high quality data. Leveraging their extensive experience in data mixing, the team assembled a massive and diverse dataset, drawing from public sources such as Common Crawl and code domains like GitHub. This enabled them to scale the training data, reaching an astonishing 2 trillion+ tokens, while curating a safe, unbiased, well-rounded, and legally compliant dataset that was derived from diverse knowledge domains.
- Cleaning pre-training data: Cleaning the data at a tremendous scale presents a substantial hurdle as the team needed to eliminate toxicity, manage copyright issues, and ensure data quality. To address this, the team closely collaborated with Salesforce legal and ethics experts to establish a robust data cleaning pipeline, integrating model-based and keyword-based methods for high accuracy.
- Modeling: The team navigated the complexities of training its large-scale LLM on Google’s TPUs by integrating technologies such as Flash Attention and Sliding Window Attention. This helped drive the fast and efficient modeling process, ensuring the model could manage the intricacies of various tasks.
- Fine-tuning the model: The team was challenged to fine-tune its model to support user needs that were not anticipated during initial training. This involved interpreting diverse tasks and instructions, complicated by the random ways users interact with the model. Fine-tuning was a key phase for aligning the model with real-world user requirements and values. The team used both the standard supervised fine-tuning and learning methods from human/AI feedback.
How was the XGen model trained?
XGen’s training process unfolded over multiple stages. In the pre-training stage, the model established its foundational knowledge about world and language to support various applications and domains. This stage did not involve any human annotation and the model was trained to simply predict the next token given a context of previous tokens, drawing from raw text data on a colossal scale, usually using trillions of tokens.
Next, during the fine-tuning stage, the model was trained to interact with users just as a human would. Humans supervised this stage, which incorporated techniques like supervised fine-tuning and reinforcement learning from human feedback to help the model understand and deliver what users need – learning their intent via numerous task instructions and the corresponding output or feedback on model generated outputs. Also at this stage, the team ensured that the model maintained ethical considerations – ensuring safety and legal compliance.
Lastly, the evaluation stage measured the model’s ability to perform tasks unseen during training, confirming its robust generalization across a diverse set of tasks. The team also benchmarked the model’s performance against open source and closed-source counterparts – ensuring its accuracy.
Shafiq shares more about the training process.
How does XGen distinguish itself from general-purpose, external LLMs?
The model separates itself from general-purpose LLMs in three major ways:
- Supports unique customer needs. While general purpose LLMs support a wide range of public needs, XGen was specifically tailored to power private Salesforce-based use cases and meet our customers’ unique requirements.
- Ensures data privacy. Unlike external API-based sources, XGen drives stringent data privacy controls. This complies with Salesforce’s restrictions on keeping customer data inside its own secured platform. Consequently, the model remains the sole viable solution for highly sensitive industries like banking, where it is impractical to share customers’ information with third-party LLMs and data privacy remains paramount.
- Reduced cost to serve. By laser-focusing on Salesforce customer use cases, XGen is a smaller scale model that is customized for particular domains (use cases). As a result, its reduced size decreases its inference cost due to lessened computational needs.
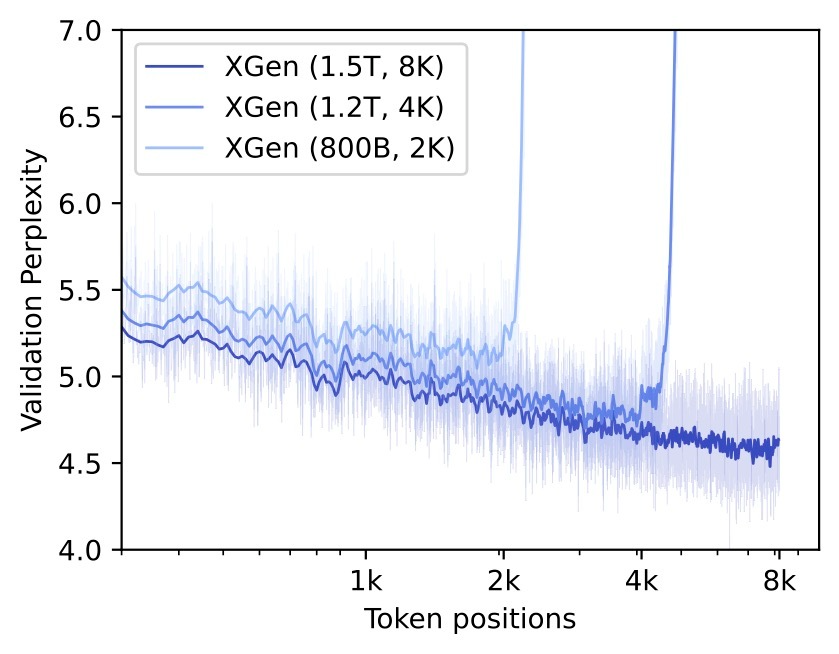
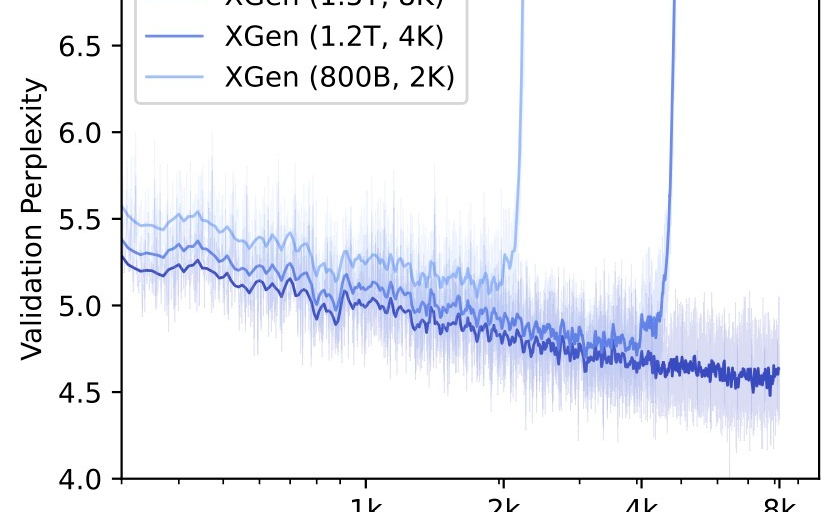
A look at validation set perplexity for XGen pre-trained models with different context sizes.
What are the significant new and upcoming developments for XGen?
XGen’s 7 billion parameter model will soon evolve into much larger models, surpassing other open-source models at the same scales while subsequently leveraging a Mixture of Experts (MoE) architecture. Building this more powerful model involves leveraging experience from the 7 billion parameter model, which kept development costs reasonable because the team was not starting from scratch.
This new model can serve as a teacher, driving knowledge distillation to smaller, cost-effective models which, in turn, support unique domains.
Looking ahead, the team is developing XGen Mobile, a 4 billion parameter model version of XGen. This innovation allows customers to install XGen directly on their phones, removing the need for an Internet connection. As a result, users are empowered with on-the-go access to XGen, no matter the setting. For example, using XGen Mobile, field service agents could extract information from their offline documents, enabling them to efficiently complete jobs such as fixing appliances while on the go.
Learn more
- Interested in more AI stories? Read this blog to learn how Salesforce’s cross-cloud Scrum team built Einstein for Flow, a game-changing AI product that revolutionizes Salesforce workflow automation.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.