In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Pratima Nambiar, a Distinguished Architect with 17 years of experience at Salesforce. Pratima has played a crucial role in developing and scaling the service mesh architecture that facilitates secure communication among thousands of services on Salesforce’s Hyperforce platform.
Dive into how the team overcame infrastructure challenges when adopting public cloud, solved key technical challenges like reducing blast radius and optimizing scale, and established robust deployment processes while actively contributing to open source innovation.
What is your team’s mission as it relates to service mesh?
Our mission is to ensure that service-to-service communication is secure, resilient, and observable at scale. We serve as the foundational layer upon which all of Salesforce’s clouds are built, providing the robust infrastructure needed to guarantee high trust before our solutions reach our customers.
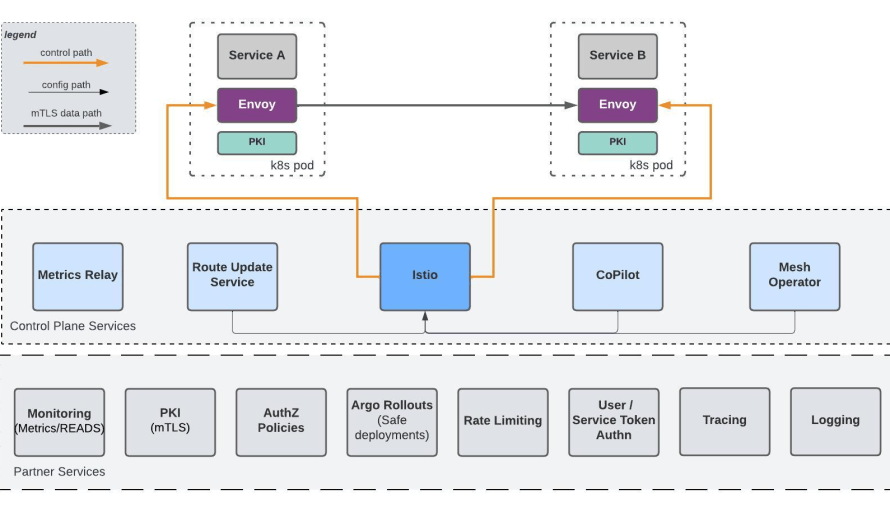
To achieve this mission, we developed an infrastructure platform leveraging open source products such as Envoy and Istio, seamlessly integrated with our internal tools for metrics, PKI infrastructure for mutual TLS, rate limiting, and other essential enterprise capabilities. This platform underpins all Salesforce clouds, handling the non-functional requirements of service-to-service communication. This allows our cloud teams to focus on developing business logic, rather than the undifferentiated heavy lifting of service connectivity.
The elasticity of public cloud infrastructure has been a key enabler in our rapid innovation, allowing Salesforce to create groundbreaking products like Data Cloud and Agentforce. Service mesh further amplifies our ability to scale this architecture by providing default security, resilience, and observability capabilities to development teams. Through our integrated, opinionated platform, we ensure that these critical features are built into the fabric of our services, enabling our teams to deliver exceptional value to our customers.

A look Inside the service mesh architecture.
What communication and infrastructure challenges did adopting public cloud create that required implementing service mesh architecture?
When Salesforce adopted public cloud infrastructure, our team encountered fundamental infrastructure challenges that demanded a new approach to service communication. Our first-party infrastructure relied on static, bare metal hosts that were always up and didn’t scale dynamically. Transitioning to public cloud, however, unlocked significant advantages, including the scale and elasticity of compute resources and the dynamic nature of the infrastructure. This shift brought about a new set of resilience challenges, particularly when we adopted Kubernetes as our infrastructure platform. With Kubernetes, services could go up and down independently, which required us to rethink how we ensure reliability and stability.
In addition to these infrastructure changes, we implemented a zero trust architecture to enhance security. Zero trust means that we don’t trust a caller simply because it’s inside our private network boundary; we always verify that the caller is authorized. This approach introduced complex security implications for inter-service communication, as we needed to ensure that every service interaction was secure and verified.
To tackle these challenges, service mesh became even more essential in the public cloud environment. Service mesh addressed the issues by building an application networking layer with all the necessary plumbing baked into sidecars. These sidecars handle security, observability, and reliability automatically, so individual services don’t need to implement these capabilities themselves. By onboarding to the mesh, services immediately benefit from secure communication, resilience to dynamic service states, and visibility into inter-service interactions.
Moreover, we recognized the need for multi-substrate capabilities from the outset. The team began with AWS but anticipated the addition of other cloud environments, such as GCP, in the future. Service mesh provided a substrate-agnostic foundation that works seamlessly across different cloud platforms. This flexibility allowed us to stand up various types of services on Hyperforce, each with unique requirements for service-to-service communication. To support this, we became more active in the open source community, contributing back to CNCF projects like Envoy and Istio to ensure they met our needs and continued to evolve.
What were the most significant technical and deployment challenges your team faced with service mesh?
We are currently tackling two major technical challenges: blast radius reduction and scale optimization. For blast radius reduction, we are implementing control plane sharding to ensure that if there is a control plane issue, it only affects a subset of services rather than the entire mesh. The team is also working on reducing the blast radius within single clusters and developing more robust data plane upgrade processes.
In parallel, the scale optimization challenge involves optimizing configuration delivery to sidecars as we expand to larger meshes. With thousands of services running various use cases, we need to ensure that the configuration delivered to all those sidecars is efficient and doesn’t overwhelm the system.
Beyond these technical challenges, from a deployment perspective, we run the service mesh as a software-as-a-service, handling all upgrades for our internal customers. The team has invested heavily in a robust upgrade process that includes integration testing and validation across different use cases. We follow a deliberate progression through our established environments — development, test, performance, staging, and production — validating various service types and use cases at each stage.
To ensure reliability, we employ a methodical approach to rolling out new features, starting from low-risk to high-risk environments. This process includes automated integration tests to catch any issues early on. Our strategy builds on the well-established release processes from the open source projects, while also incorporating our own robust processes to guarantee enterprise-grade reliability. By carefully staging our rollouts and leveraging automated testing, we can introduce new features with confidence, knowing that they will perform reliably in all environments.
What challenges did your team face integrating with open source projects like Envoy and Istio while meeting Salesforce’s specific service mesh requirements?
To ensure our managed mesh platform meets Salesforce’s unique needs, we leveraged Envoy for the data plane and Istio for the control plane. However, as an multi-tenant enterprise software platform, we also required custom solutions. We introduced web assembly extensions to add custom logic to the data path for service-to-service communication. These extensions, along with the built-in open source features, provide reusable out-of-the-box capabilities that address Salesforce’s specific enterprise requirements. This means our internal developers can use pre-built features without having to manage all the Salesforce-specific details themselves.
The cornerstone of our success has been our active participation in the open source communities for Envoy and Istio. We’ve established Salesforce as a trusted and valued contributor, which has been essential for enhancing our managed mesh capabilities across Hyperforce. When we face new use cases or need specific features, we contribute to the open source projects instead of developing everything in-house. This approach allows us to solve problems in a standardized, industry-wide manner, which is crucial for our fast-paced product development.
By contributing to the broader community, we ensure that our solutions are both industry-standard and tailored to Salesforce’s unique requirements. This symbiotic relationship has been a key factor in the success of Hyperforce, enabling our teams to build products quickly and efficiently on our platform.
What technical limitations and capability gaps in current service mesh technology are driving your ongoing R&D efforts?
A key focus is developing multi-tenant API policy capabilities on top of our mesh in partnership with Mulesoft. Given our distributed architecture, we need a robust internal API platform that services can easily leverage for various API policies. This will help us maintain governance and consistency across our entire service ecosystem. We are expanding it further to enable Agentforce.
Additionally, we’re researching advanced telemetry and debugging tools. Although we already have a wealth of telemetry data, we need more effective ways to analyze and debug issues in our complex service topology. With call paths spanning multiple services, making this data actionable for troubleshooting is an ongoing engineering challenge.
Overall, our mission is to bridge the gap between industry innovation and Salesforce implementation and simplify service to service communication for our internal developers. We assess new Envoy features and actively contribute to their development when they align with our needs. This ensures we stay at the cutting edge of service mesh technology while meeting the specific demands of our enterprise environment.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.