In our “Engineering Energizers” Q&A series, we explore the innovative minds shaping the future of Salesforce engineering. Today, we meet Erwin Karbasi, who leads the development of the Salesforce Central Evaluation Framework (SF Eval), a revolutionary internal tool used by Salesforce engineers to assess the performance of generative AI models.
Explore how SF Eval addresses AI testing challenges, enhances application reliability, and incorporates user feedback to continuously improve AI model outputs.
What is your AI team’s mission?
Our team ensures that Salesforce AI components, such as Einstein Copilot, deliver outputs that are not only high-quality, reliable, and relevant but also ethically aligned. This commitment builds trust with our users, as we rigorously test these components through SF Eval. (Think of it as a chef taste-testing dishes before serving!) This robust framework helps us identify and address potential issues such as bias and accuracy, ensuring our AI tools exceed user expectations in terms of quality and dependability.
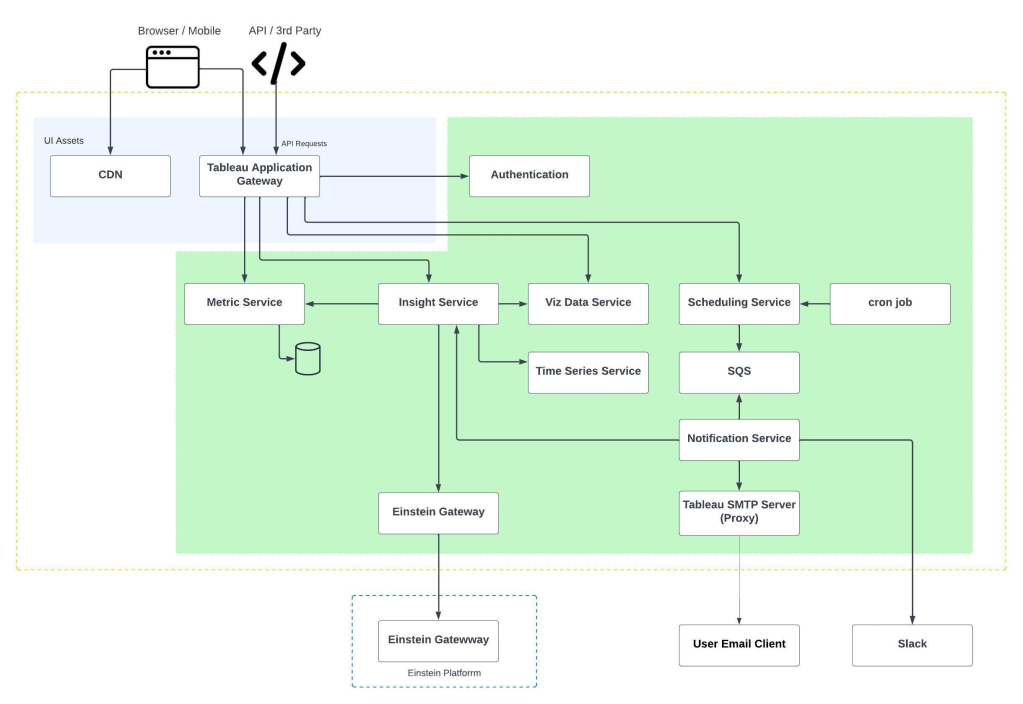
SF Eval is a comprehensive, layered platform that integrates traditional machine learning metrics with AI-assisted metrics to assess the performance of AI models comprehensively. This includes evaluating various components like prompts, large language models (LLMs), and Einstein Copilot. By ensuring these components meet high standards of accuracy and relevance, we empower businesses with dependable AI tools.
What are the challenges in evaluating the accuracy and relevance of generative AI and LLMs?
- Ambiguity of Prompts: This can lead to irrelevant responses from the AI. To mitigate this, the team refines prompts for clarity and consistency, ensuring they are precise and less likely to generate off-target outputs.
- Factual Accuracy of LLM Outputs: Salesforce tackles this challenge by incorporating real-time fact-checking mechanisms and human oversight. This dual approach allows for the verification of critical outputs, confirming that the information provided by the AI is both accurate and trustworthy.
- Accuracy of Retrieved Information: The team addresses this by using reliable sources for data retrieval and implementing reranking algorithms. These algorithms help in validating and ensuring the relevance and accuracy of the retrieved data, which is crucial for maintaining the relevance and integrity of AI-generated responses.
These strategies collectively enhance user trust and dependability in AI applications.
What were the initial challenges in developing SF Eval?
Initially, defining the appropriate metrics was a major hurdle. The team had to decide whether to adopt existing industry metrics or develop new ones tailored to their specific needs, such as CRM data relevance. This was crucial for ensuring the quality and relevance of the AI outputs.
Integration posed another challenge, requiring seamless coordination between various components of Salesforce’s extensive platform. This integration was essential for creating a cohesive framework that could support both internal applications and external user needs effectively.
Lastly, addressing the needs of both internal and external customers was complex. The team aimed to create a unified platform that could cater to diverse user requirements, integrating seamlessly into their development pipelines. This required continuous feedback and adjustments to ensure the framework met all user expectations and enhanced their overall experience with Salesforce AI tools.
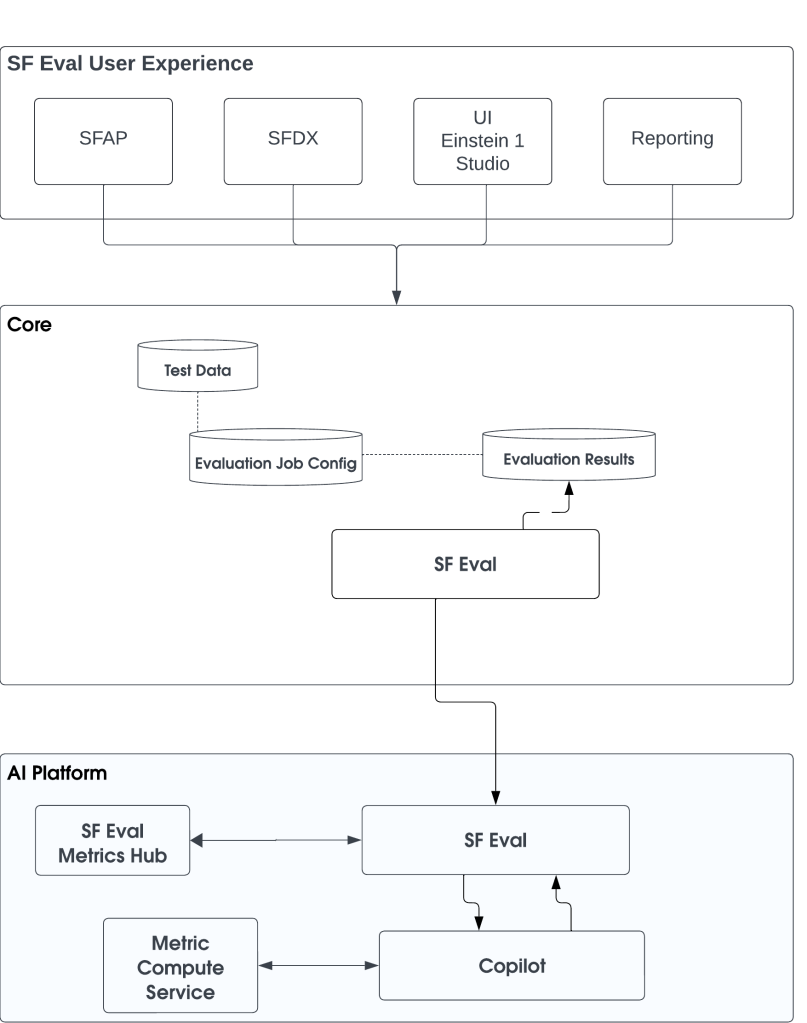
The SF Eval ecosystem, accessible through SFDX / Einstein 1 Studio, allows users to perform gen AI evaluations and score them using metrics from the metrics hub.
What is a key additional feature of SF Eval that addresses a major challenge in testing AI applications?
One specific feature is its comprehensive benchmarking and prompt evaluation and improvement capabilities. This feature is crucial for systematically assessing and enhancing AI performance. By using a variety of standardized tests and metrics, SF Eval can benchmark AI models against industry standards and best practices. This process helps identify strengths and weaknesses in the AI’s output, providing a clear pathway for targeted improvements. Additionally, prompt evaluation and improvement ensure that the prompts used to test the AI are continuously refined for clarity, relevance, and effectiveness, resulting in higher quality AI interactions.
Another critical feature focuses on the retrieval aspect, known as RAG (Retrieval-Augmented Generation). This feature implements context-aware evaluation models that enhance the AI’s ability to generate contextually relevant responses across various domains and scenarios. By ensuring that the retrieved data is pertinent to the prompts, this feature addresses significant challenges related to the accuracy and relevance of AI-generated content.
How can SF Eval be utilized across different stages of its application, and what are the specific purposes for each?
SF Eval is utilized in three key phases:
- Development: During the development phase, SF Eval is employed to rigorously test and validate the initial prompts and strategic plans. This involves identifying and rectifying any potential errors or inefficiencies early in the process, ensuring that the foundational elements are robust and effective before moving to the next stages.
- Benchmarking: In the benchmarking phase, SF Eval conducts a detailed comparative analysis of various LLMs based on key criteria such as accuracy, trustworthiness, performance metrics, and cost-effectiveness. This phase is crucial for decision-makers to select the most appropriate LLM that aligns with the organization’s specific CRM requirements and strategic goals.
- Production: Once in production, SF Eval continuously monitors the deployed system to ensure it adheres to the quality standards established during the development phase. It detects any performance drifts or deviations, enabling timely adjustments to prompts or strategic plans. This continuous evaluation ensures the system remains efficient, reliable, and aligned with the desired outcomes in a real-world operational environment.
How does SF Eval enhance AI application reliability and performance from development through post-deployment?
SF Eval is structured in layers, starting with ad hoc testing at the development stage, where developers can receive immediate feedback on AI outputs. This is followed by batch testing, which simulates real-world scenarios to assess outputs more comprehensively. The top layer involves runtime monitoring and observability, ensuring continuous assessment even after deployment. This multi-tiered approach allows for thorough testing and refinement of AI applications, ensuring they perform optimally in real-world settings.
How does customer feedback influence the development of AI applications at Salesforce?
One specific feature is its dynamic adaptability to customer feedback. This feature is crucial for refining AI outputs based on real-time user interactions. By incorporating feedback directly into the evaluation process, SF Eval can adjust prompts to enhance their relevance, clarity, and effectiveness. This feedback loop mechanism ensures that the AI applications remain aligned with user needs and expectations, significantly improving the responsiveness and adaptability of prompt-based interactions.
Customer feedback significantly shapes the development of AI applications at Salesforce, ensuring that the tools not only meet but also adapt to user needs. For instance, feedback has led to the enhancement of sentiment analysis models to detect subtle emotions like frustration or confusion, thereby improving the effectiveness of customer support interactions.
Salesforce’s feedback loop mechanism within SF Eval facilitates this process of continuous improvement. This mechanism allows users to provide real-time feedback on AI outputs, which Salesforce integrates into ongoing AI development. This integration helps in making dynamic adjustments to AI models and algorithms based on user interactions and inputs, ensuring that the AI applications are practical, user-centric, and aligned with the evolving expectations of users.
Customer feedback is not just influential but central to the iterative development process at Salesforce, fostering enhancements that refine user experience and application reliability.
Learn More
- Hungry for more AI stories? Learn how Amazon SageMaker enhances Salesforce Einstein’s LLM latency and throughput in this blog.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.