

At Salesforce, Trust is our number-one value, and it has its own special meaning to each part of the company. In our Technology, Marketing, & Products (TMP) organization, a big part of Trust is providing highly reliable Salesforce experiences to our customers, which can be challenging because of the scale of the Salesforce infrastructure, its range of tech stacks, and the many products that those tech stacks support. Because of that challenge — and because TMP must gauge reliability at both that high level (across products) and from a zoomed-in view (for individual services supporting those products) — agreeing on what “highly reliable” means and how to measure it is absolutely critical. So just as Salesforce employees refer to standardized branding guidelines to speak the same product language, we also need standardized service ownership guidelines to ensure that we’re speaking the same reliability language. This blog post is about the Salesforce journey to framing reliability in terms of service-level indicators (SLIs) and objectives (SLOs), which are often used in the enterprise software business to represent the true customer experience in a clear, quantitative, and actionable way.
Understanding the “Before” Picture of Service Ownership
In the past, teams stored SLOs in custom dashboards, documents, and a mix of other resources, all of which had to be manually updated by data analysts. Those analysts spent hours upon hours updating health metrics across the Salesforce product lines, and finding health metrics for a given team was also difficult. That search meant reaching out to colleagues and scanning through multiple repos and documents to get historical data. And when you found those numbers for one team, product, or service, you couldn’t always compare them with the numbers from other teams, products, or services because how the numbers were calculated often varied. With this distribution of data, varied calculations for it, and no central view for comparing it, analyzing an SLO over longer periods of time — especially across properties — wasn’t always possible. As a result, we didn’t have as clear and direct of a read on customers’ Salesforce experience as we wanted.
Starting the Journey to Improved Service Ownership
The piecemeal reporting on reliability wasn’t working for us, and we knew that we needed a standardized view for the actual health of products, features, and services — and into how that actual health compared to the health that internal and external customers expect. With that view, we could more easily identify customer-impacting incidents, diagnose their root causes, and analyze dependencies between systems.
- Standardized measurements of product and service health: We standardized on READS as the minimum set of SLIs required for services, with any SLIs that didn’t apply to a service being exempted for it. The previously published READS: Service Health Metrics blog post outlines the SLO framework established at Salesforce.
- Standardized tooling to support those measurements: We built a dedicated SLO platform for hosting SLI definitions; SLO definitions; and service definitions, which include service ownership information, health thresholds, alert configurations, and more. Because this rich metadata for services was all published in the same data store, finding and learning about services became easy. Service owners could even integrate their SLOs with Salesforce-internal operational workflows to ensure that those SLOs become an integral part of their day-to-day work.
- Standardized visualization tied into that tooling: After a service owner instruments their service to emit health metrics, they get a standardized, out-of-the-box view into those metrics. That view includes the standard READS SLIs that apply to their service and any custom SLIs that they created to represent their service’s unique capabilities, reflect their customers’ reliability expectations, and capture a fuller picture of their service’s health.
Providing Standardized Service Ownership Capabilities at the Org Level
Combined, the standardized measurements, tooling, and visualizations have have the ability to allow teams to:
- Have confidence in SLOs being calculated in a standardized way.
- Gain insights from visualized SLI/SLO metrics.
- View those metrics with daily, weekly, and monthly granularity during operational reviews.
- Use SLO targets to judge whether a service is meeting user expectations.
- Set up alerts on SLI/SLO metrics.
- Correlate SLO breaches with active incidents.
- Identify service dependencies, which can be especially useful during incident analysis.
- Continuously improve the Salesforce experience based on a data-driven approach.
Onboarding a Given Service to Service Ownership
For a service owner to take advantage of the previous capabilities for their own service, they must onboard that service to service ownership, which involves adding it to a service directory on the previously described SLO platform. They create a service definition file that codifies the name of their service and a configuration file that includes the queries for calculating the service’s health data, the SLOs defining expectations for that health data, and other service-specific information. For the queries, they use a templated framework that minimizes configuration redundancies and idiosyncrasies.
After the service owner runs the configuration pipeline and commits their files in Git, they get:
- A Grafana dashboard specific to their service for realtime monitoring, which is automatically generated, gets populated with data collected and aggregated by a data pipeline, and can be used for real-time debugging and validation.
- Their service added to the service analytics dashboard, which is regularly reviewed during operational reviews and drives conversations about service health and availability — without making any additional demands of the service owner’s time.
- Long-term storage and retention of their service’s health data, giving them visibility into historical health trends.
- The ability to generate automated alerts for their service using configs that are set up using rich metadata.
- The service’s topology information included in health and availability aggregates, which can help to pinpoint the instance(s) of the service that breach the service’s SLOs.
Getting to Know the SLO Platform’s Architecture
Now that we’ve covered the benefits that the SLO platform provides to service owners, let’s explore how it’s structured.
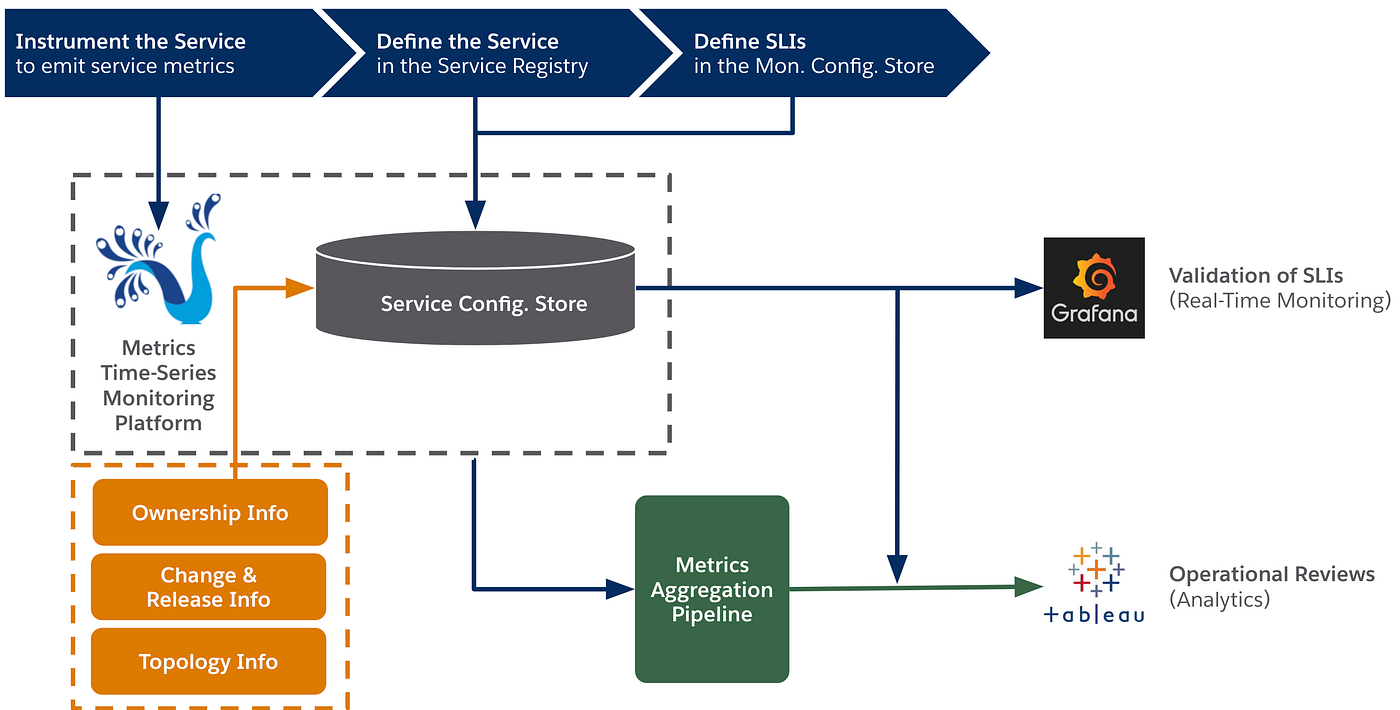
- Service Registry — The store for service ownership information, service statuses, and service-specific configurations.
- Service configuration store — The store for SLI and SLO information, triggers, and warning and critical thresholds required for monitoring and alerting.
- Topology information — The service’s substrate(s) and deployed instances.
- Change and release information — In the future, information that allows us to correlate change and release artifacts with SLO breaches to quickly diagnose their causes.
- Ownership information — Service Ownership information that can be integrated seamlessly with alert-related metadata and correlate with actionable notifications.
- Metrics time-series monitoring platform — After a service owner instruments their service to emit operational metrics, the store for those metrics, which then feeds those metrics (some aggregated, some not) into the metrics aggregation pipeline.
- Metrics aggregation pipeline — Running across various substrates to provide aggregated service health data for operational analysis, this pipeline finds queries for SLIs from the monitoring configuration store, executes those queries to get raw time-series data in 1-minute intervals, and then rolls up that data on a daily and weekly basis.
Fostering Service Ownership Success on the SLO Platform
After the SLO platform was built, we saw massive adoption of it, with ~1,200 services onboarded to it in just its first year. Through onboarding, cataloging, instrumenting, and analyzing services — and setting up carefully crafted SLIs and SLOs for them in sandbox and development environments — the platform has enabled service owners to extract deep, actionable insights into the health of their services and how to improve or maintain it.
And by driving operations reviews from the unified service health dashboard, which the following screenshot was taken from, we’ve witnessed several availability success stories. Service owners have been able to catch dips in SLIs, highlight dependencies that weren’t meeting their defined SLOs, review availability trends, and better understand and communicate customers’ experience with their services. At times, analysis of that data from the SLO platform has even prompted the rearchitecting of certain critical services and driven conversations about strategic investments and tactical improvements.

In the future, we want to provide a more comprehensive view of the layers of dependencies required for any service to maintain its health, which would allow us to pinpoint exactly where a failure occurs and to minimize recovery times. Then, we could set threshold expectations across the entire stack, not just service by service, and better enable critical services to meet their SLOs. We plan to make the SLO platform an API-first platform, which would allow us to set up integrations with change and release management data, and to scale up the data architecture to meet the platform’s massive computational needs. We’re excited to see the platform continue to grow and look forward to sharing more success stories in the future.
If you would like to learn more about how you can build observability into your services from the ground up, check out this previously published post about READS: https://engineering.salesforce.com/reads-service-health-metrics-1bfa99033adc
Acknowledgments
Thanks to Alex Dimitropoulos for additional contributions to this post and to the entire development team, who created the SLO Platform and continue to evolve it!



