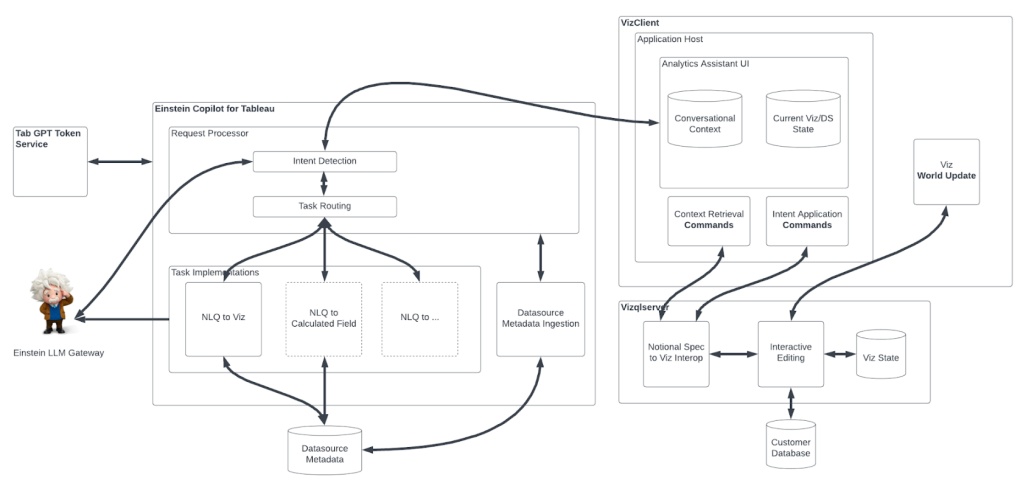
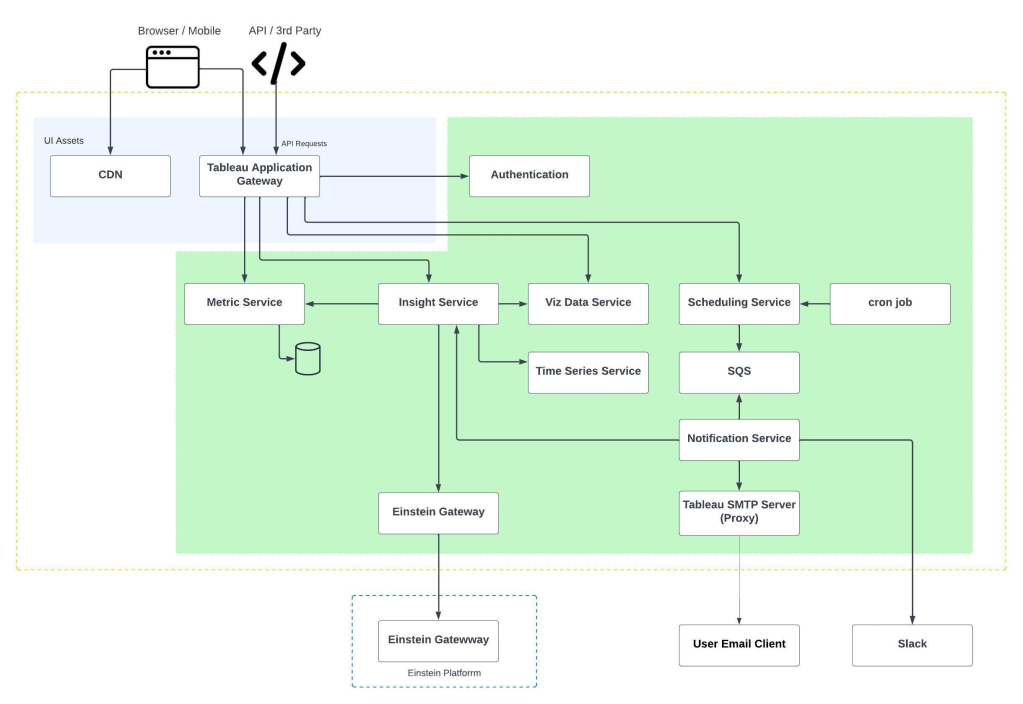
As you scale your company’s software footprint, with Service-Oriented Architecture (SOA) or microservices architecture featuring 100s or 1000s of services or more, how do you keep track of the performance of every service in every region? How will you know whether you are tracking every service? Of course every service is different, but how do you view health through a single lens? We faced these challenges at Salesforce. Looking at best practices both inside and outside of Salesforce, we developed a framework that prescribes the minimal set of indicators that every service needs to discern its health and performance using a common language at operational and executive levels. The minimal set we outline in this blog post follows two well-known frameworks: the RED pattern and the USE method. Each service will (and should) have its additional specific indicators to further understand its performance and debug production issues.
Health Indicators
The handy acronym READS describes the minimal set of indicators for every service: Request rate, errors, availability, duration/latency, and saturation. Every service owner is responsible for generating the right metrics to allow these indicators to be calculated or derived.
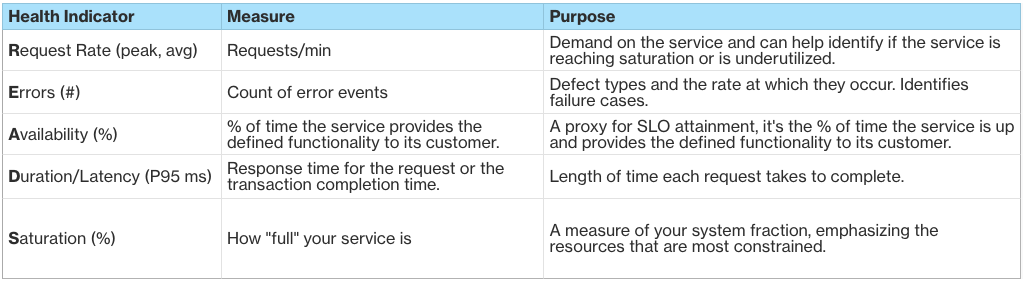
Let’s take a closer look at each of these important indicators.
Request Rate (Requests per minute)
This measures the number of requests that the service is processing per minute. Along with volume, this is a measure of utilization of the service and can indicate whether the service is reaching a threshold of the number of requests it can service with reasonable latency. While measuring this, we should report both the peak and average values for requests per minute. Average indicates the sustained load on the service, and peak indicates the maximum load on the service. Both are useful measures for planning.
Volume is a related metric that measures the number of requests to the service over a period of time. Trending this signal over a long period of time will help the service owner to understand the increase or decrease in usage. A week-over-week comparison of the same will help us understand anomalous behavior in the system. For example, for a REST service, the volume is the count of HTTP requests received by the service.
Errors (Errors per minute)
Application and system errors provide service owners with critical data about the service’s performance not only over time but also immediately following a new deployment. Increased errors per minute at that time might indicate a bug missed in testing or a degraded or failed dependency and may predicate the need for a rollback. There are two general categories of errors we recommend measuring and tracking to measure code and system quality.
- Failed requests — the number of requests that failed per minute. An HTTP service will generate when a request resulted in 5xx response code.
- Logged Exceptions — the number of unhandled and logged errors from your application.
Availability
Availability is a proxy for Service Level Objective (SLO) attainment and can be defined differently according to service type and architectural pattern. In plain terms, availability is the service’s ability to provide its capability to its customers. How a service defines availability depends on the key functions the service wants to provide, within an error threshold and/or within a latency (duration) threshold. There are two ways your service can measure availability.
- Measure availability by taking into account every operation/transaction/API call/request. The measure of availability likely will be an aggregate metric composed of various signals that the service may deem important to determine if the service is available or not. For some services, successfully servicing a request means that the service is available, while for others (such as an alerting service, a service that sends notifications, among other tasks) doing so within a specific time period is important and, if not met, the service is considered unavailable.
- Measure availability using a representative canary or synthetic test using synthetics testing tools from vendors such as Dynatrace or NewRelic (or Kaiju, in the case of Salesforce). This canary issues a customer transaction (preferably against an API) and measures the rate and quality of that transaction. These transactions generate pass/fail signals to a monitoring tool such as Argus (in case of Salesforce), which can then be used to calculate the availability of the service.
We prefer to measure availability by the first approach — taking every operation into account — as opposed to using a canary test, unless the volume of organic operations is lower than canary test volume. This provides a more comprehensive view of the health of the service. This also allows us to determine the percentage of customers for whom the service was available down the road, which is valuable for measuring the impact of service downtime. If we measured availability against a synthetic, we wouldn’t benefit from this insight.
Uptime is closely related to availability. The goal of capturing this signal is to determine if the service is up and running. This is purely a dial-tone signal. It is not a comprehensive check of whether the service is doing what it is supposed to do, nor does it provide any insights into the performance of the service. A service owner can capture uptime in multiple ways.
- If you are running a service which exposes a public endpoint, you can leverage a synthetic test to determine if your service is up or not.
- You can also run a cron job that periodically checks whether the service is up and sends the status to a monitoring tool.
- If you are running on Kubernetes, you can leverage the liveness and readiness checks that are already built-in. Internally at Salesforce, we capture both the liveness and readiness signals out-of-the-box and send them to Argus.
Duration/Latency (P50, P95, P99 secs)
Duration is the time taken to successfully service a request. It is important to measure this because a delayed response indicates poor service health and customer experience. For a REST service, duration is the delta time between when the request was received and when a successful response (say, HTTP Status code 200) was returned.
While determining this number, take only the successful requests into account. As a bonus, you can capture the latency of errors, but that should not be included with successful requests because doing so will result in misleading numbers. With latency, an average measure is not a good one as it will mask the long tail of response time that some requests (and thus some customers) may be experiencing. As such, we highly recommend collecting this metric as a histogram. This allows you to easily compute and report P95 and P99 values.
Saturation (%)
Saturation represents how “full” your service is with a measure of your system fraction, emphasizing the resources that are most constrained. (A few examples: In a CPU constrained system, show CPU usage; in a memory-constrained system, show memory; in an I/O-constrained system, show I/O). Why capture this signal? To start, you want to determine the most constrained resource for your service. This could be something like IOPS, disk space, memory, network bandwidth, or compute. Once you know this, then measure saturation to determine how much more capacity you have to furnish requests before the performance of the system or service starts to degrade. This is measured as a percentage. As a service owner, decide the most constrained resource for your service and track it as the basis of the saturation metric.
READS and Standardized Dashboards
By classifying health indicators into READS, storing this and other metadata (including service ownership, instantiation, and topology), and leveraging that data, at Salesforce we have been able to build standardized dashboards (out-of-the-box) to instantly view the health of services in your org in real time and the ability to analyze that information over time. The screenshots below show that information in Grafana and Tableau.


To READS and Beyond
The indicators in our list of READS metrics are just the beginning of monitoring your service’s health. In order to debug your service and understand its performance, you might consider additional metrics. Of course, because workloads and what every service does is different, it’s impossible to uniformly apply every single metric uniformly across all services, but the same categories of metrics can be broadly applied. For example, the metric to measure errors for an HTTP based REST service (say response code = 500) will be different than the metric to measure errors for a batch service.
Other metrics that services may want to capture could include:
- System metrics (for the system on which your service is running). These will automatically include the USE metrics for every resource. Within Salesforce, we collect these automatically and make them available in our monitoring tool.
- Runtime metrics (jvm, golang, etc), collected via collectD or in-process
- JMX Metrics for Java-based runtimes such as jvm heap, GC, thread, resource pool metrics, and others
- Similar metrics for other runtimes such as golang
If you would like to learn more about how you can build observability into your services from the ground up, check out our set of five design patterns for building observable services.