

This blog post summarizes a Dreamforce 2017 session that was delivered on Tuesday, November 7. To watch that session, check out the recording!
Superheroes get noticed. They wear flashy, bright outfits and are typically airborne. But there’s another kind of hero, the kind who want to go unrecognized by keeping things running smoothly. These folks keep the lights on in the dark and the water tumbling from an open tap. In fact, any service you come to rely on has teams of shy heroes who keep it reliable.
Salesforce has teams of heroes who prefer to stay rather inconspicuous to our customers. They provide incident management and service protection in order to maintain customer trust. They deliver some of the tech industry’s highest standards in system availability, performance, and security. With millions of daily users and trillions of yearly transactions, incidents that result in a service disruption can and do happen, but these heroes employ their superpowers to prevent them or minimize their impact.
A Rare Sighting
On Tuesday at Dreamforce 2017, Vijay Swamidass, Director of Software Engineering, and Fabio Valbuena, Principal Architect/VP of Engineering, spoke about these superpowers in their Availability and Incident Response for the World’s Most Trusted Enterprise Cloud session. Both Vijay and Fabio are Salesforce veterans who’ve helped develop the innovative tools, strategies, and procedures that have made us the most trusted enterprise cloud.

Incident Detection and Response
Heroes are ever vigilant, and Salesforce has an assortment of lairs and hideouts for monitoring so we can detect potential problems and respond to and resolve incidents when they occur. As one of these monitoring centers ends its workday, duties are handed over to the next one where the workday has just begun. This strategy is based on the Follow the Sun model because, well, that’s the direction it follows. The result is continuous global vigilance that no Batcave can equal.
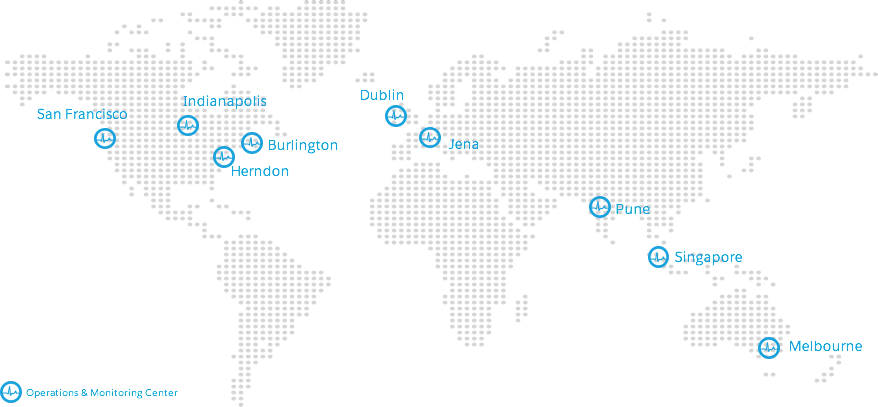
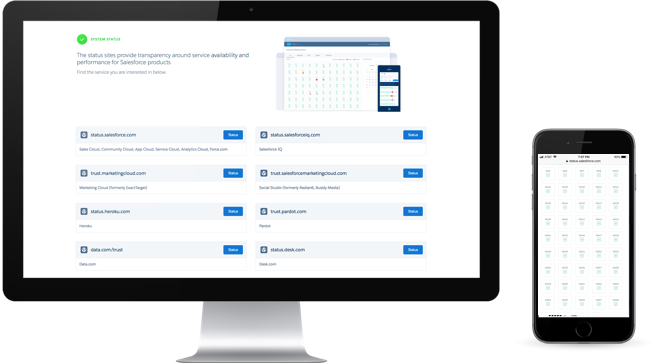
Vijay’s team develops the tools that enable this vigilance, including the Trust status site, which provides real-time status and forward-looking maintenance information about our core CRM and other Salesforce services. From the Trust status site, customers can see service status or subscribe to Trust Notifications, which notifies them about ongoing service issues and upcoming system maintenance.
Incidents that make an appearance on the Trust status site must impact multiple customers and be at least five minutes in length. The site then provides regular updates until the incident has been resolved.
How Customers See Incidents
What customers see on the Trust status site is actually an aggregation of data from tools that monitors system alerts and then provide a platform to respond to and resolve them. The time that the incident started, what instances are affected, and what action is being taken represent separate streams of data that our heroes first interpret and then make customer-friendly for the site.
How Salesforce Sees Incidents
The data streams coming from the monitoring and alerting tools is how our Site Reliability Engineering heroes see potential incidents. They use this data to shrewdly determine if an alert is truly an incident, and, if so, if it should be posted to the Trust status site. Vijay’s team is also responsible for developing these indispensable tools:

- Refocus is a visualization tool that presents a unified view of our core CRM service and other Salesforce services. Refocus is open source software that’s actually used by some customers to monitor their Salesforce integrations.
- The Global Operations Console (GOC) is a workspace where Site Reliability engineers view, acknowledge, and resolve alerts. They can also use GOC to contact on-call personnel and access a knowledge base that allows them to resolve issues quickly.
- The Incident Management Console (IMC) is an incident-gathering space that brings teams together to resolve an active incident. It gives them a running timeline of the incident and the ability to post statuses with direct links to the Trust status site.

Service Protection
Fabio’s team are the heroes who provide proactive and automated service protection and resource balancing. They monitor for resource usage patterns that indicate an upcoming service degradation or disruption, and their tools allow them to identify the source of each pattern at the customer level. Many of these patterns indicate some sort of service resource imbalance, which can be caused by customers installing third-party components or running large background jobs during peak times. Intensive search requests executed by a Universal Resource Identifier (URI) are also a common cause.

When these patterns are detected, Fabio’s team springs into action and uses the following procedure to protect our service.
- An early warning goes out that a resource imbalance has been detected.
- Internal background jobs are stopped to correct the detected imbalance. The early warning is cleared if this action resolves it.
- If the imbalance is not resolved in Step 2, the customer’s use of system resources is slightly restricted within our Fair Usage Allocation parameters.
- If the imbalance continues, a deeper analysis is made before redirecting traffic and throttling back system resources.
- If a service disruption is imminent without action, the customer activity is restricted or isolated from consuming more system resources.
To the Rescue!
Service protection heroes don’t leave customers confused and wondering who those masked people were. In fact, they proactively contact customers to let them know that service protection is underway. They also work with customers to help resolve issues on their side and even propose ways to improve what the customer was attempting to do.
An example of this type of issue is customer installation of third-party components. Customers might do these installations during peak times and without first testing them in a sandbox environment. These installations can become a significant resource load that’s hard to debug.
Fabio’s team always leaves customers with helpful advice, which includes following our Infrastructure Best Practices, building quality code, and thorough testing in sandbox environments.

“Our work here is (never) done.”
The heroics don’t end when a service degradation or disruption is resolved. The teams that ensure availability through service protection and incident management always look for ways to improve our tools and processes. Their path forward includes providing a more unified customer experience on the Trust status site and improved responsive detection through the use of machine learning. When incidents do happen, they take proactive measures to resolve them and prevent them from reoccurring.



