Did you know that the techniques used to recommend the next book to purchase or the next movie to watch for a user can also help suggest which tests to run for a given change?
At Salesforce, our core codebase is a monolith with around a million tests in our test inventory¹. This includes functional, integration, and User Interface (UI) tests. With a monolithic codebase and so many tests, it became really hard for a developer to know which tests might be impacted by their change.
An ever-growing number of tests and an ever-growing number of changes also created an issue for our Continuous Integration (CI) system as the time to feedback and the compute resources required also grew in tandem. We were already batching changes instead of running all tests on every change, and only the failures were run on every change in the batch to figure out which change broke the test. Even with our massive CI infrastructure, we could not infinitely scale, and developer productivity was suffering due to longer feedback cycles.
The idea behind the solution was that since every test is not relevant for every change and every test is not equally likely to fail, if we could build a service that prioritized tests for every change we could tackle the scale issue in a way that was not linearly impacted by the growth rate of tests and code.
Besides being a monolith, our code base is also multilingual. In addition, it has a large number of “non-code” and configuration files that all interact with each other. One such example is a group of XML files where developers can define metadata that leads to code generation and therefore heavily impacts tests. All this meant that a simple approach, like relying only on code coverage to determine what tests to run, was not feasible. One thing we had going for us was a large amount of historical data on test executions from our CI system. Based on research that, in our multilingual and heterogeneous system, a mix of signals performed much better at finding relevant tests than any signal by itself, we decided to create multiple rich features.
Out of this idea, Test Prioritizer was born — a service backed by a machine learnt model that provides a ranked list of relevant tests. The service allows querying for a prioritized list of tests for a given changelist² and a max number of tests or a max test runtime. The service also allows filtering tests by labels which are internal constructs separating out tests by type, function, and area.
The Features
The goal for each feature was to give a scored list of test recommendations. All the feature recommendations would then be fed into a model to provide the final recommendations.
Code Coverage
Since most of our codebase is in Java and JavaScript, code coverage performs well at finding relevant tests that execute the code under change. We periodically generate Java and JavaScript code coverage of all the tests using Jacoco and Istanbul respectively. Tests that cover more lines of the changed files or more files in the changelist are scored higher.
We are transitioning to Clover-based Java code coverage data which gives the exact line numbers from the source code that are covered by each test. We can then fetch tests that cover the exact lines that changed instead of all tests that cover the changed files. This will help improve the precision of recommendations from this feature.
Text Similarity
We have a couple of features that are based on textual similarity between the change and the tests. Our ‘path text similarity’ feature is based on extracting tokens from the test names and paths of the test classes and then fuzzy matching them with path tokens of files in the changelist. Tests whose classes share more of the path with the files in the changelist are ranked higher.
The ‘content text similarity’ feature uses Abstract Syntax Tree (AST) to convert the code for each test into tokens, and those tokens are then compared to tokens from the changes in each file of the changelist. The tests that have more textual similarity with the changes are prioritized.
We apply some basic Natural Language Processing (NLP) preprocessing to all the text tokens such as:
- converting to lowercase,
- “Stop word” removal: words that appear too frequently in the paths like ‘java’, ‘src’ are removed,
- “Stemming”: reducing a word to its most basic form e.g ‘running’ and ‘runs’ all convert to ‘run’,
- “N-gram”: splitting a token into multiple word tokens e.g. ‘CountryIsoCode’ generates ‘Country’, ‘Iso’, ‘Code’, ‘CountryIso’, ‘IsoCode’, and ‘CountryIsoCode’.
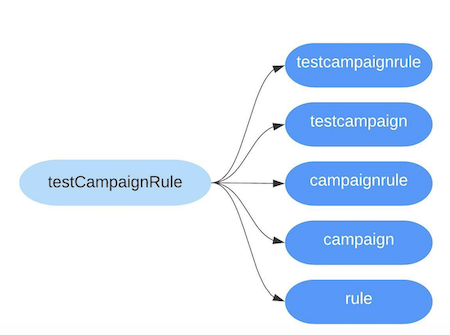
We periodically gather tokens from the test code and its file paths. These are then stored in Elasticsearch, a full text search engine based on Lucene, which allows us to perform fuzzy search to find tests that match the search tokens from the changelist.
Features Based on Historical Data
The following features are all based on historical test execution results data from our CI system.
Failure History Recommender
This feature is independent of the changelist and recommends recently failing tests from the system. The idea is that this signal would capture the parts of the codebase that are currently under active development and therefore likely to break. The recency and frequency of failure increases the test ranking. During evaluation this feature was found to be very noisy due to test non-determinism. A non-deterministic test is one that changes between pass and fail state without any code change. These tests would generally be the highest recommended through this feature, since they changed state frequently. While we got some good results from this feature, we decided not to use it in our model since it bloated the recommendations with too many unrelated tests.
File to Test Recommender
For this feature, if a changelist caused a test failure in the past, then all the files in that changelist are said to have relevance to the test. This feature also uses ‘Collaborative Filtering’ to recommend tests. Similar to how a website might recommend the next book to purchase or the next movie to watch to a user based on other users with similar preferences, we use cosine similarity to determine what files are similar to other files and add tests relevant to those similar files to the recommendation as well. The tests directly related to files in the changelist are given higher scores than tests added through collaborative filtering. The more files in the changelist a test is related to, the higher it gets ranked.
This feature implicitly gives more weight to tests that fail more often since this signal is based on failure data. This is desirable since our goal is to detect failures quickly for each change, so we want to assign higher scores to relevant tests with higher likelihood of failure.
A disadvantage is that this feature is negatively impacted by test non-determinism, so if a non-deterministic test was incorrectly assigned to a changelist by our CI system we would record that relationship and make decisions based on that data.
User to Test Recommender
This feature is similar to File to Test Recommender with collaborative filtering on users instead of files. We recommend tests broken by the user in the past and add in recommendations from similar users.
We experimented with determining similar users based on the user’s team, their broader division, and the overlap of tests the users had broken in the past. We then used the tests broken by one user in the past to recommend tests to similar users in the future. This feature did not end up providing great results for two reasons. First, a user that made a change and got a test failure as a result would learn from the experience and tend to not break the same test again. Second, due to internal developer mobility within Salesforce, our developers can change teams and even divisions which leads to very few users with similar history to be significantly useful for prediction. This feature was also dropped from the model.
The Model
Since all of our features provide ranked recommendations, the Test Prioritizer model is a fairly simple linear regression model which basically means the results of all the features are combined together by a simple weighted sum formula. The model is trained on historical data from our CI system to determine the weight of each feature. We decided to use a regression model (one that gives a scored list of test recommendations) instead of a binary classification model (relevant vs. not relevant tests) since it enables us to pick the top k number of tests with the highest relevance. Based on the capacity of the use case, we have the flexibility to fetch the top 500 or the top 1000 etc. most relevant tests from the same model.
Model Validation
The model recommends tests that are relevant to a changelist, but there is no existing data in our system to verify relevance. Instead, we rely on test failures assigned to a changelist by our CI system to measure how good our model is performing. If a test fails in the CI system and that failure is determined to be caused by a particular changelist, we want to make sure that our model recommends that test for that changelist.
Recall
We use recall as a metric for validating our model. This measures how many “good” recommendations were missed. In our case recall is the number of tests we recommended for the changelist that failed compared to the total number of tests that failed on the changelist. This calculated how many test failures the model missed.
RECALL = True Positives / True Positives + False Negatives
Where,
- True Positives: tests we recommended for a changelist and they failed on that changelist
- False Negatives: tests we did not recommend for a changelist but they failed on the changelist
- True Positives + False Negatives: Total failing tests for a changelist
Precision
Normally precision is calculated in addition to recall, which measures how many recommendations are actually “good” out of all the recommendations. In the absence of measuring precision, one could maximize recall by recommending everything.
In our case, precision is the number of recommended tests that failed divided by the number of total tests recommended. For us, a low precision does not mean that the recommendation is bad since the test might be covering the feature that changed but the developer did not break it. Therefore, this is not a good measure for our model. Depending on the use case, we have a limit on how many tests we can recommend, which automatically limits us from recommending too many tests.
PRECISION = True Positives / True Positives + False Positives
Where,
- True Positives: tests we recommended for a changelist and they failed on that changelist
- False Positives: tests we recommended for a changelist that did not fail on that changelist
- True Positives + False Positives: Total recommended tests for a changelist
Results
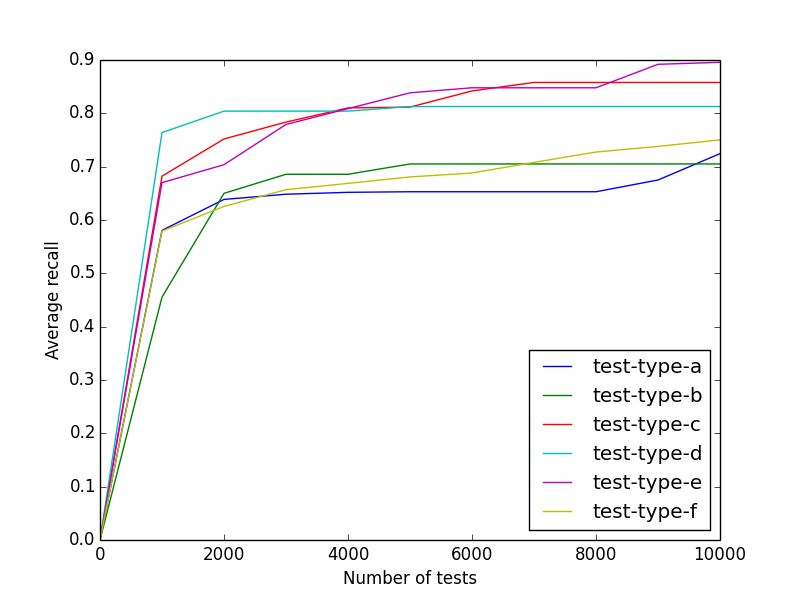
Our tests are internally divided into types (generated tests vs. sanity tests vs. UI tests, etc.) and our average recall per change for each of those types is currently between 60% to 80% at 2000 test recommendations, as seen by the graph above.
Test Prioritizer is now being used as a mechanism to select a few sanity tests to run at the code review stage before the developers checkin changes so we can catch issues before they make it into the codebase. Test Prioritizer is also being rolled out in our CI system to run relevant tests on small batches of incoming changes enabling our CI system to scale while providing faster feedback. The entire test suite is run periodically as a dragnet to catch any missed failures.
Conclusion
In large codebases where clear test dependency information is not available due to heterogeneity (multiple languages and file types) and scale (rapid changes, lots of tests), we can use a mix of features to train a machine learning model to prioritize which tests to run for each change. While this method does not provide 100% accuracy, in situations where it is infeasible to run all the tests for every change, it can allow us to do continuous integration and provide fast feedback to the developers.
[1] There are many other projects that are not part of this repository, but most of those are much smaller in codebase size and number of tests.
[2] The set of changes made in a single commit in a version control system.