

In the current technology landscape, web APIs are used everywhere. In fact, almost every major software application around at the moment offers some form of web API. They connect gargantuan enterprises to hopeful entrepreneurial ventures, integrate different components within an enterprise, and connect systems between collaborating enterprises. At a more granular level, they even help an isolated system communicate within itself (think micro-services).
But what makes a web API successful and how do we set one up for success? From the developer’s perspective we can probably consider a web API set up successfully if it has been intelligently designed, fully documented, and well-tested. From the perspective of someone who consumes the web API, well, it just has to be easy to use (and preferably free).
Personally, I’ve spent the last 5 years engaged in the Ad-tech industry building and consuming RESTful web APIs. This includes working with Facebook, Twitter, LinkedIn, and Salesforce APIs (to name a few) as well as building them myself. On the surface this might sound like a barrel of laughs…but if you’re working with or managing a web API that is not structured, maintained, and presented properly — that barrel may as well be filled with screams.
The objective of this post is not to badger you over the basic principles and best practices of building a web API (we’ll leave that to the comments section of Stack Overflow). Rather, this post is to pass along the lessons I’ve learnt regarding how to set up a web API that is easy to use, robust, and ready for any stage of growth. All this in hope that one day when we meet, interface to interface, it will be with a knowing nod rather than a scathing email or bug report.
So I present to you five significant lessons I’ve learnt along the way while using and building web APIs, which are:
- Build Every Web API with Respect
- Be Obvious
- Automate Documentation
- Trust in Acceptance Tests
- Log, Monitor and Alert
It’s important to note that throughout the duration of this post when I refer to web APIs I am referring to RESTful web APIs specifically (sorry SOAP fans). Let’s get started.
Build Every API With Respect
This might sound a little strange, but every web API that gets built deserves to be treated with respect from the very first commit. Each should be built as if its eventual purpose will be to bridge two multi-million dollar subsystems together. Why, you might ask? Because who knows…one day it might.
I’ve come across several web APIs now which were initially developed as small “internal” components (perhaps to be used by a micro-service every other Thursday). Given their trivial nature, it’s understandable that they appeared to have been “hacked up” hastily to satisfy an immediate requirement. But as we all know, if you are lucky your software will grow. Demand for the product will increase and user adoption will surge. Perhaps the company will be acquired. Before you know it you’ll be told that a team from the other side of the planet need to use your web API for an integration project they’re working on — and they’ve already banked several million dollars on it happening without a hitch.
So it pays to build each web API meticulously from the very beginning. Be sure to always follow obvious best practices, build with tests, and have it code reviewed by developers who also understand the topic. Try to have documentation available, or at the very least, have summarised comments that can later be used by other developers and documentation generators.
The importance of starting a web API off on the right foot cannot be emphasised enough, as once it becomes adopted and other systems rely on it, it is much more difficult to make changes.
Be Obvious
During my time building and consuming web APIs, one thing that still surprises me (to this day) is the amount of times I end up surprised. Moments where I think, “oh, it’s a bit different with this resource”, or “that seems a bit off — but what the hell.” It’s the kind of early morning disorientation a developer doesn’t need.
Small nuances between endpoints, like jumping in and out of pluralising nouns, requires extra consideration and will probably garner at least one wince per “first time” user. Other confusing behaviour may include alternating verbs over different resources (but performing the same operation). Another classic is returning just an id for some newly created resources but the entire object for others. Of course there can be a specific need to set up some endpoints differently, but often it can appear to occur without any apparent reason. If there is not a uniform approach taken while developing a web API, then using it is not an obvious task.
In this example, imagine Developer A starts building a web API and creates CRUD operations for the books and authors resources. Then Developer B comes along and sets up the CRUD operations for the titles resource.
GET /books
GET /books/123
POST /books
PUT /books/123
DELETE /books/123GET /authors
GET /authors/123
POST /authors
PUT /authors/123
DELETE /authors/123GET /titles
GET /titles/123
POST /title
PATCH /titles/123
POST /titles/delete/123
You’ll notice there are three instances where Developer B decides to go off the beaten path, and in one foul check-in makes this API a whole lot less obvious. Users of the API are now forced to rely upon up-to-date documentation (if it exists) if they wish to understand how to manage titles.
The approach you take with the format of web API routes, requests, and responses ultimately comes down to what is best for your own situation. The most important thing is to be consistent throughout and not leave users guessing. If you work at a company that has their own set of guidelines to abide by like the team I work on then it’s easy — you just follow instructions. If you work somewhere where there is no guide then it might be a good idea to think about creating one early on in the project. If you keep the format uniform, you keep it obvious.
Automate Documentation
Just the word “documentation” can elicit a slow and steady exhale from many developers. The creation and maintenance of documentation is no fun for any developer to have on their list of responsibilities. However, creating documentation and maintaining its accuracy is crucial to the successful adoption and continuous use of any web API.
When a web API’s documentation starts to exhibit signs of outdated or incorrect information, hours (if not days) of head scratching can be added to the work schedule of teams using it. And of course, eventually, work will come back to the developers in the form of emails and reports that need to be responded to.
So why would one not relinquish themselves from the burden and automate documentation? There are tools out there which do a great job of converting a web API’s source code into well-presented and formatted “help” webpages. For example, if you are creating an ASP.NET Web API, a documentation generator is included in the WebAPI project template by default (ApiExplorer). Third party libraries like Swashbuckle can also aid by adding a more visually stimulating and interactive design to your documentation. If the routes in the source code are well commented, then the time required to setup automated documentation is minimal.
Below is an example of one webpage that was generated using ApiExplorer for a particular endpoint in an ASP.NET web API that I work with.

If we eliminate the need to maintain documentation manually, then we eliminate a potential point of failure in communicating how to use our web API.
Trust in Acceptance Tests
During and following any development to your web API, how do you ensure that all aspects of it are still working successfully? Any developer that’s been on the job more than two days will likely respond to this question with another question — “well, how well are you testing it?”
Adding as many unit tests as possible to your project is a good start, but ultimately it’s likely they won’t cover everything. Many web API projects are lightly coded, as the bulk of the business logic is taken care of by referenced packages and third party libraries (which may or may not be working). Therefore, it is important to consider setting up a suite of acceptance tests to cover all potential valid and invalid requests that could be made.
To provide an example, three ASP.NET Web APIs I’ve worked on recently use a BDD approach to acceptance testing using Specflow (.NET’s implementation of Cucumber). Using Team City, a suite of Specflow tests can be continuously run using the Specflow+ Runner tool at scheduled intervals and after each build. Each time the tests are run, Specflow+ Runner records a comprehensive execution report that details the results.
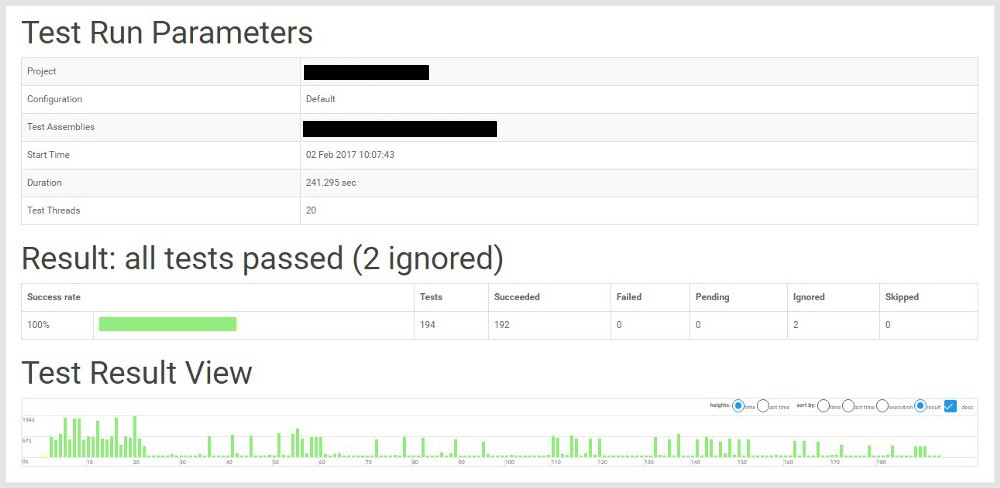
Having an extensive suite of acceptance tests running continually against a web API (and after each build) gives an acute sense of confidence to developers and product managers alike. If all possible scenarios are applied to each endpoint, and the tests are passing then the API is ready for release and success is virtually ensured.
Log, Monitor and Alert
Building our API meticulously with tests and presenting it accurately is a great start in setting it up for success. But there are some things we can’t control — infrastructure, connected components, referenced packages, and users that prefer the path less travelled. If we want our web API to continue to be successful, then we need to keep an eye on it while it’s being used.
Logging is a given for most APIs built today and is typically baked into the infrastructure layer of most architectures. However, monitoring and alerting is not. It is perhaps one of the most necessary but excluded elements of a successful web API project. It’s also quite easy to set up in the current era of software development, as where there is a need for something, someone’s probably built a tool for it.
Monitoring and alerting can tap into multiple data sources but typically into either logging or metrics data.
Logging data for web APIs will generally consist of full request and response content with context and correlation data. Also included typically are exception events and perhaps some lower level machine data too. Log management tools such as Splunk allow us to continually analyse our logging data, which can power informative dashboards and alert us when an unwelcome trend is uncovered.
If you haven’t already, it’s worth checking out some example dashboards that can be created in Splunk illustrating what can be rendered with logging data. With respect to web API logs specifically, it isn’t hard to imagine what can be done — pie graphs depicting categorised usage, time series graphs exhibiting total usage over time, and grids aggregating exceptions. There is plenty that could be done!
Metrics data for web APIs are typically counters, for example, a count of requests made to each endpoint with a corresponding HTTP status code. These metrics can give us a high level snapshot of how our web API endpoints are performing. An example of 2 counters might be:
Number of POST requests made to /books/ with the HTTP status code 500
Number of POST requests made to /books/ with the HTTP status code 201
Which could be aggregated to higher level, for example:
Number of POST requests made to /books/
How granular you are when querying or recording metrics is entirely up to you. However, metrics are usually implemented at quite a high level as logging usually takes care of lower level data.
In recent months I’ve been involved with implementing metrics monitoring and alerting on an ASP.NET Web API using Prometheus, Grafana and Alert Manager. This itself could be material enough for another post, but for now I’ll use it as an example of how monitoring metrics could be implemented.
Below is a Grafana dashboard for the aforementioned project, which consists of a web API that also accesses 7 other external web APIs. The health of the API and all externally used APIs are monitored, as well as aggregated to determine an overall health percentage.

Using Alert Manager, alert notifications were set up to fire when request success rates dropped below a configurable value (in this case 95%). We chose to send alerts to a Slack channel, but any number of mediums are available.
Logging, monitoring, and alerting become more aligned with the success of a web API the more it gets adopted. It may not be necessary during the early days when there is one user making three requests per day. However, once a web API is receiving several thousand (or million) requests an hour, dashboards and alerting reduce a scary amount of complexity to understandable bite-sized chunks.
Conclusion
Using, building, and maintaining web APIs has become commonplace for many developers in today’s technology landscape. They’re also quite fun to work with, as no two are the same. I’ve learned the lessons shared in this post by making the typical mistakes along the way while using and building web APIs myself. Perhaps including these practices in your project will help you avoid some of the common pitfalls in the first place! Do you have any tips you would add? We’d love to hear from you in the comments!



