By Sunil Kumar Konduru Subramanyam and Ibrahim Bin Abdul Rahim.
In our “Engineering Energizers” Q&A series, we shine a spotlight on the brilliant engineers fueling innovation at Salesforce. Today, we introduce Sunil Kumar Konduru Subramanyam, a lead engineer on the Search Platform team. This team powers Salesforce’s structured data search, allowing users to quickly find leads, accounts, cases, and more across all Salesforce Clouds.
Discover how Sunil and his team manage unpredictable traffic spikes, handle large-scale migrations, and balance multiple workloads—all while delivering lightning-fast search results across countless organizations, processing billions of monthly queries, and maintaining low latency over 6.9 petabytes of indexed data.
What is your team’s mission?
The Search Platform team is dedicated to providing fast, reliable access to structured data across the Salesforce ecosystem. The goal is to ensure that users, whether support agents or sales reps, can instantly find relevant records such as accounts, leads, cases, or knowledge articles, no matter which Cloud is in use. Search serves as the gateway into the Salesforce data model, spanning Sales Cloud, Service Cloud, and beyond. This enables entity lookups, case history resolution, and cross-object queries within milliseconds. The mission is to deliver this capability at scale, with consistency and low latency for a global customer base.
Recent architectural advancements include extending search capabilities across the Salesforce ecosystem. While the core focus remains on structured CRM data, the team now supports integration with Data Cloud and hybrid search workflows that enable retrieval across external sources. The system currently indexes 6.9 petabytes of data and supports over 900,000 monthly active organizations (up 36% year-over-year).
Your platform handles 30 billion searches a month. What’s the hardest part of delivering fast, reliable results at that kind of scale?
The most significant challenge is ensuring low-latency, high-reliability query results despite volatile, customer-driven traffic patterns. The growth has been remarkable — monthly queries jumped from 22 billion to 29.4 billion (a 34% increase) from January 2024 to January 2025. These surges often stem from events outside Salesforce’s direct control.
Industries experience regular traffic spikes. Health insurers see increased load during open enrollment, food delivery services surge during major televised events, and Asian retailers experience spikes during regional holidays. These events concentrate massive loads in specific geographic or business domains within a short time frame.
These bursts create high variance in resource utilization, making real-time adaptation essential. Traditional capacity planning is inadequate because preparing for the worst-case load across all orgs would be inefficient and prohibitively expensive. The challenge is to dynamically balance infrastructure costs, system throughput, and customer-facing latency without compromising availability.
What specific technical challenges arise when supporting search operations at this scale?
One of the key challenges involved managing cascading load during a platform-driven migration event. Approximately 9,000 orgs were scheduled for migration, each triggering significant indexing activity. As the event progressed, CPU utilization surged to 500% across the affected cluster.
This surge created extreme contention within the system. Indexing, query serving, and internal replication processes all vied for the same compute resources. Our load shedding mechanism proactively detected increasing error rates from search server responses – our primary stress indicator – and automatically began shedding lower-priority traffic. Without immediate intervention, query latencies would have exceeded SLA thresholds, resulting in a degraded user experience and potential incident escalation.
A traffic protection mechanism had been developed but not yet tested under real production pressure. This event became the first major test. The challenge was not only to activate the mechanism under stress but also to ensure that system resilience remained intact without the need for additional hardware or downtime.
The event highlighted a critical lesson: defensive engineering features must be production-ready before the need arises. Real-time pressure validated both the system architecture and the fallback safety mechanisms, ensuring robust performance and reliability.
You had 9,000 orgs migrate at once and CPU load spiked 500%. Why didn’t the system collapse—and what did you learn from managing that moment?
The system maintained stability thanks to automated load shedding capabilities designed to protect high-priority traffic under stress. As CPU pressure surged, the load shedding mechanism dynamically suppressed lower-priority operations, including background indexing and replication tasks.
No manual intervention or additional infrastructure was necessary. Query requests from end users continued to meet SLA requirements — sub-300 millisecond latency — despite a 5x increase in CPU utilization. The system automatically deferred non-critical workloads using priority-based filtering and exponential backoff strategies.

Figure 1: Search Server CPU load before/after load shedding.
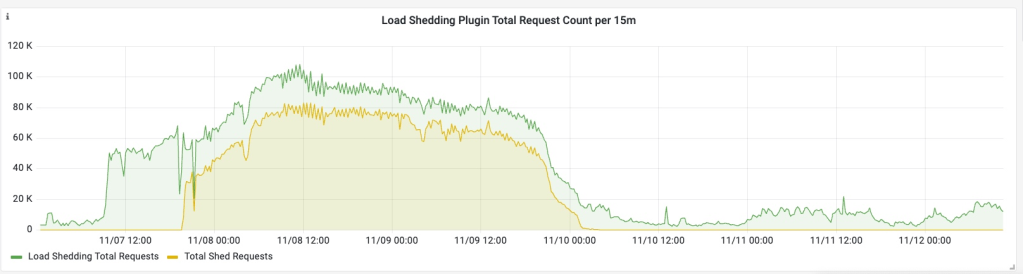
Figure 2:Total Requests vs. Shed Requests Over Time.
All deferred tasks were retried during off-peak hours, utilizing adaptive scheduling windows. Retry intervals were extended incrementally — 30 minutes for initial failures, with longer intervals for subsequent retries. The automation framework ensured task completion without the need for developer involvement or support escalation.
The key takeaway: a resilient platform must have automated degradation strategies that activate independently of human intervention. This incident validated the robustness of the architecture and eliminated the need for costly capacity increases or emergency response rotations.

Figure 3: Comprehensive load shedding framework with error-rate-driven thresholds ensuring critical traffic flows while deferring lower-priority requests.
When traffic spikes, how do you decide who gets served and who doesn’t — and what goes into protecting the right users under pressure?
Salesforce uses a priority-based request scoring system to manage all inbound traffic. Each request is assigned a score between 0 and 100, reflecting the urgency and business impact of the request. Priority 0 requests, such as live user queries initiated from user interfaces requiring real-time responses, are given the highest priority. Priority 100 requests, including background batch tasks, replication jobs, and low-urgency indexing, are given the lowest priority.
A dynamic threshold engine continuously monitors the health of the system. If the error rates increases, the threshold is automatically lowered. Requests with scores above the active threshold are dropped, ensuring that critical traffic continues to flow while low-priority requests are deferred.
This approach ensures that performance degrades gracefully under load. The system avoids total failure by reducing the scope of operations, rather than the overall capacity. No user-facing traffic at priority 0 is dropped under any condition.
The threshold engine also applies smoothing functions to prevent oscillation and unnecessary shedding. The result is a traffic shaping system that guarantees service to critical workflows and prevents performance regression during system contention.
What key principles for building resilient search systems at scale have emerged from this work?
From our experience in building and refining our load shedding system, several fundamental principles have emerged that are applicable to distributed services facing variable load patterns:
- Prioritization Over Scaling: Prioritizing critical traffic over non-critical traffic has proven more effective than simply adding more capacity. This approach yields better overall performance and resource utilization.
- Black-Box Monitoring: Using error rates as the primary signal for monitoring has enabled faster and more efficient responses to system stress, without the need for complex instrumentation.
- Smooth Response Curves: Implementing sigmoid scaling and EMA-like calculations has prevented oscillations and ensured stable system behavior during varying load conditions.
- Clear Numeric Priority System: A numeric priority system (0-100) has allowed for fine-grained control and easy adjustments as business needs evolve, providing more nuanced management compared to simple categorical tiers.
What enhancements are you now developing to further improve the system?
Building on our load shedding framework’s success, we’re focused on several advanced capabilities to increase resilience as we continue to scale. We’re expanding beyond binary accept/reject decisions to implement multi-faceted rate limiting with more nuanced throttling approaches at different stack layers. We’re also developing decoupled autoscaling and rebalancing strategies — load shedding reacts instantly while autoscaling adds capacity if needed, alongside automated cross-cell distribution for long-term stability.
Additionally, we’re incorporating adaptive, multi-metric observability that considers signals beyond error rates. By including latency measurements, queue depth metrics, and garbage collection pressure, we’ll achieve more comprehensive health assessment and make even smarter decisions about traffic management during peak loads.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.
.