

Anyone who takes monitoring their services seriously knows that alerting is an important character in the monitoring saga. There is no point in collecting a huge amount of metrics if our teams won’t be notified when they breach. When a television show has a successful first season, sometimes you’ll notice it gets a makeover for season two: new intro music, better costumes, higher production quality. As metrics scale, alerting also needs a makeover. This was the exact problem we were trying to solve — giving our alerting service a makeover to handle 20% YoY growth.
The problem
With Salesforce Commerce Cloud (CC), we provide an e-commerce platform enabling customers like Adidas, L’Oréal, and many more to run their websites. E-commerce is all about having high availability and high throughput. To provide a robust platform, we continuously monitor its health and get alerts when it deteriorates. These alerts need to be in real time and they need to be accurate. Flapping alerts reduce our confidence in identifying the issue. Trust is our #1 value here at Salesforce. It is extremely important that customers have trust in us and, for that, we need to have trust in our alerts.
To achieve this, we capture key health indicators (metrics) from our platform. These indicators are applied to all the customers. We call an indicator specific to a customer a check. For example, "$CUSTOMER.jvm.heap.used" is an indicator and “customer-1.jvm.heap.used” is a check.
Thus, [num_of_checks = num_of_customers * num_of_indicators]
Indicators - Format {name, acceptable-threshold}
[
{$CUSTOMER.jvm.heap.used 80},
{$CUSTOMER.active.request.count 10000}
]Customers
[
customer-1,
customer-2,
customer-3
]Checks
[
{customer-1.jvm.heap.used 80},
{customer-2.jvm.heap.used 80},
{customer-3.jvm.heap.used 80},
{customer-1.active.request.count 10000},
{customer-2.active.request.count 10000},
{customer-3.active.request.count 10000}
]
When new features are added to our e-commerce application, engineers define additional indicators to track. As we see our platform being adopted by more customers, the number of checks is increasing quickly.
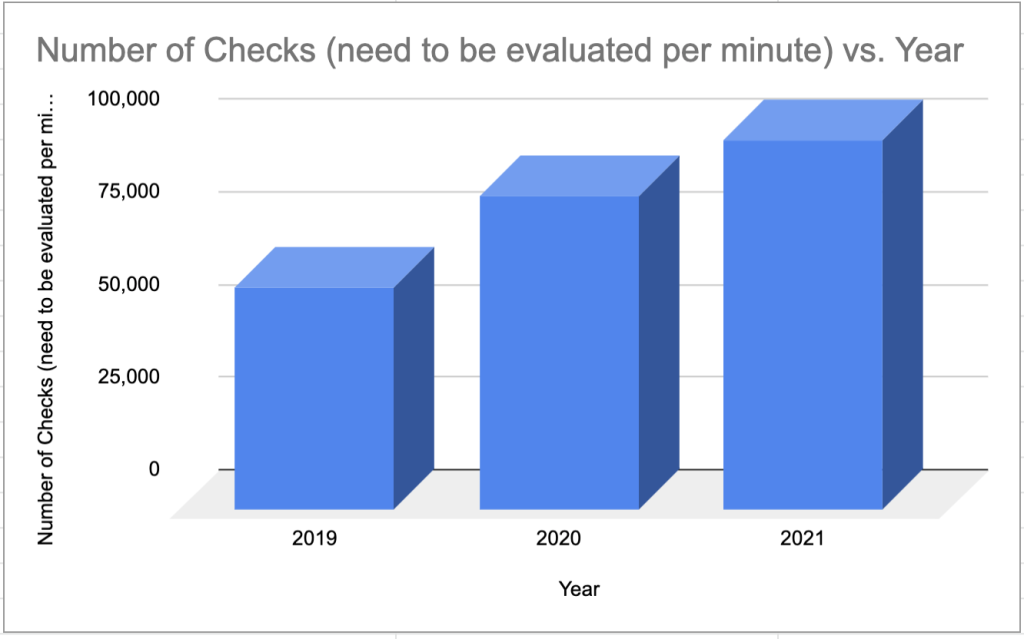
Every check needs to be processed every minute since the lowest resolution of our metrics is one minute. Because of the growth every year, our alerting service has 20% more checks to process per minute, and it needs to scale. Our legacy design had major limitations to horizontal scaling, and we had hit limits with vertical scaling. This meant we needed to re-design the system in a way such that it meets this growing traffic for the next 3–5 years.
Growth numbers (These are approximate numbers)
Legacy design and workflow
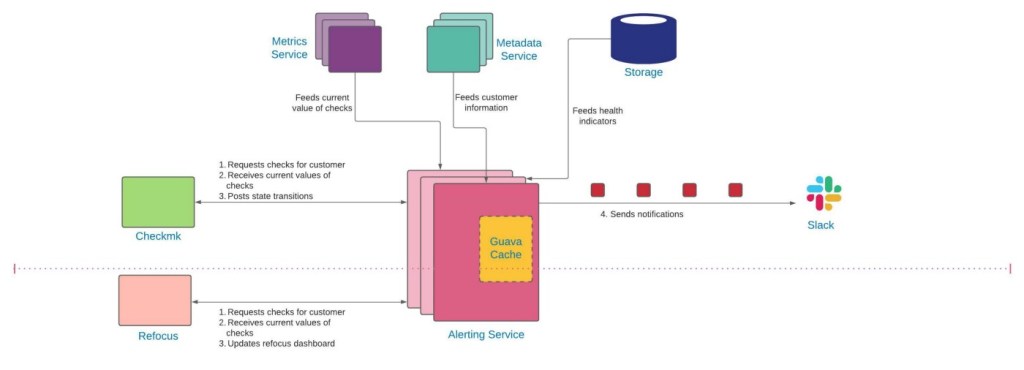
In our legacy design, we had the following major components
- Metadata Service (an internal service) to provide customer information
- Storage backend to provide health indicators (defined by engineers)
- Metrics Service (an internal service) to provide metrics, i.e. the current value of a given check
- CheckMK — an open source tool for Infrastructure and Application monitoring that acted as both state machine and client to our alerting service.
- Refocus — an internal service; a platform for visualizing the health and status of systems and/or services under observation, which acted as another client to our alerting service.

In our legacy workflow, CheckMK acted as a client and issued a batch of requests to our alerting service. Each request corresponded to a subset of customers and, as a response, the alerting service returned checks for those customers and their current values. CheckMK compared those values with previous state of the checks and determined if there is a state transition. For these checks, CheckMK then invoked its notification logic. Once the processing of one batch was complete, CheckMK issued another batch.
This synchronous pattern posed significant challenges to scaling. We couldn’t get CheckMK to process more customers in one batch. We made some attempts in that direction by tweaking its settings but they didn’t lead anywhere.
One solution was to reduce the processing time for one batch so that we could process more batches per minute. But there were limitations on that. Even though we fetched current values for every check in parallel, we couldn’t have an infinite number of threads within a process. Additionally, usage of high capacity machines drove up the overall cost of the service.
Another obvious solution was to horizontally scale and have multiple instances of CheckMK that could issue requests in parallel. But our legacy setup didn’t allow that; we could run only one instance of CheckMK.
The second bottleneck was the internal Guava cache within the Alerting service. Our service was running as a cluster of multiple processes and the cache was internal to every process. In addition to CheckMK, Alerting service had another client, Refocus, that consumed the same response but used it to update the Refocus dashboard. This use case was very well suited to serve the data from a cache. In-memory caches work well if only one process is running or if all processes have the same exact copy of the data, none of which was true in our case. This meant that, depending upon which client hits which process, there was a potential for a cache miss.
The third and final bottleneck was CheckMK itself. In addition to the scaling issues discussed above, it was very difficult to debug. Upgrading CheckMK was a non-trivial effort. Since there is no managed service option for CheckMK, the burden of operation also fell on us. Changing various of its settings would result in unpredictable behavior, hence tuning it was also a big challenge.
Because of all these bottlenecks, our Alerting Service was lagging and it could not reliably process every check every minute. In short, we needed to act.
Makeover!!!
In the course of the TV show’s makeover, its characters may evolve, but they don’t fundamentally change. Similarly, we did not want to alter the functionality of our service. We focused mainly on performance and scaling as goals for this makeover.
Our goals for the makeover were to:
- break the workflow into services such that they can be scaled independently — both vertically and horizontally.
- use a Publish-Subscribe pattern instead of Request-Response pattern.
- replace CheckMK with a state machine built on top of a managed service.
Details
We broke our workflow into three distinct components — Derivation, Evaluation and Notification.
Derivation corresponds to applying indicators to a particular customer and generating checks. Evaluation corresponds to fetching current values for those checks. Notification corresponds to notifying via Slack or email if there is a state change. This means data flows from Derivation -> Evaluation → Notification.
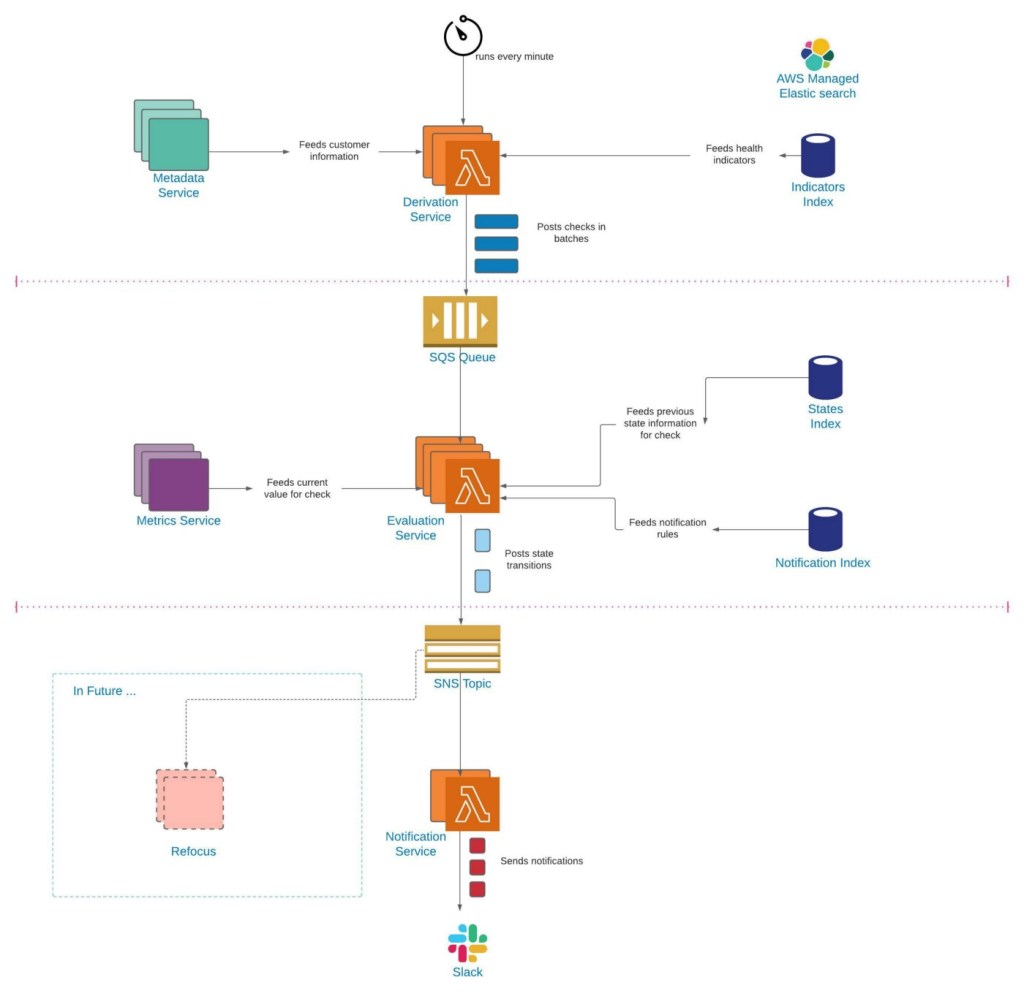
Each of these components are optimized further, e.g. even though the customer list and the indicators list are not necessarily static, they also do not change every minute. Therefore, the Derivation component can cache the results in memory for some configurable time — say 10 minutes. Since this is a compute intensive operation, it is a huge saving. Our lowest resolution for the metrics is one minute and hence all the checks should be evaluated every minute, which is why the Derivation component runs every minute and posts its results to the queue.
The SQS Queue acts as a buffering mechanism between the Derivation and Evaluation components. This queue is a crucial component in the design because it makes all the input available to the Evaluation component at once, in contrast to one batch at a time in the legacy design. The evaluation component is stateless and can be run as multiple processes in parallel that can consume from the Queue.
These processes post their outputs to a topic such that different consumers can consume from it.
At present, the Notification component is the only consumer, but we see an immediate need for another type of consumer (Refocus) coming and, therefore, we designed the solution with a topic to accommodate independent subscriptions.
Technology choices
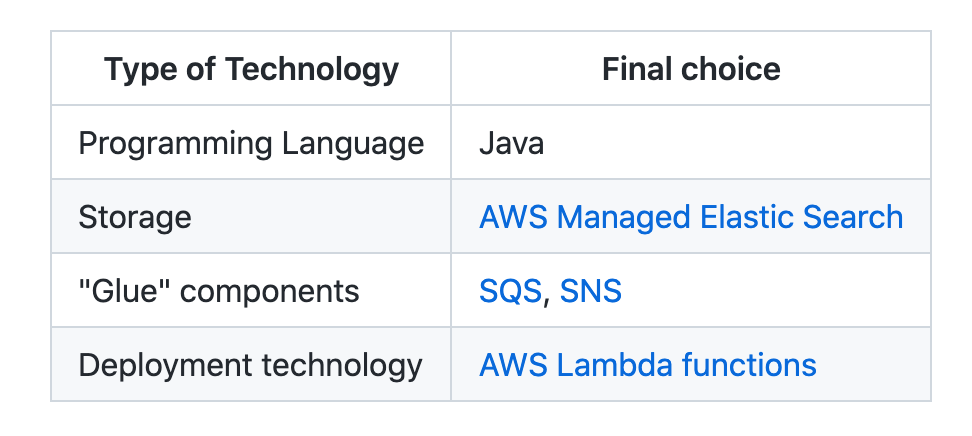
To determine which technologies we should use for our new design, we focused mainly on existing expertise within the team and the consistency of technologies with other services. All our setup is hosted on AWS and our services are predominantly written in Java, which is why we chose the Java ecosystem for these services too. Each of the above three components are a separate service, each of which can be scaled independently from the other.
We decided to replace CheckMK with AWS ElasticSearch (ES) since it is offered as a managed service and suits our scaling needs. Our team already uses it for other services and has good operational knowledge. ES now stores indicators, previous states for checks, and notification rules. ES also offered a nice feature to see the history of a particular check over a period of time.
We evaluated READ and WRITE API thresholds for Amazon Simple Queue Service (SQS) and Amazon Simple Notification Service (SNS) respectively. They were sufficient for our needs. Our team has significant operational knowledge for these two services, so they were our natural choice.
For the deployment technologies we evaluated Kubernetes (k8s) as well as AWS Lambda Functions. Our team has expertise with both the technologies and has a good framework for deployment and monitoring both types of applications. But AWS Lambda Functions provide an ease of integration with SQS and SNS that is crucial to our design. Thus, we chose AWS Lambda functions as our deployment technology.
Results
Our new system is currently running in our staging environment. Hence, the results below were obtained in our staging environment.

- All checks are getting evaluated every minute.
- We compared the alerts generated by the new system with a legacy system and they match, i.e. the alerts show correct metric value and correct state. We do not see flapping alerts.
- The most crucial component, the Evaluation service, can run with 512MB of memory and can finish all the work within a minute with 100 concurrent invocations. This means we have a lot of room for both vertical and horizontal scaling. Also, initial cost estimates are well within our budget.
- We have key metrics such as number of checks generated, number of checks evaluated, back-pressure in the queue, and number of alerts generated that we can use to monitor and tune this system.
Lessons learned
- Component-ization is a great way to scale systems. Every component consumes a different input and produces a different output. Hence, they don’t need to scale the same way. By dividing a system into components, you can scale only what is needed rather than trying to scale the whole system.
- In a microservices world, metrics and tracing are crucial to debugging issues in production. We had metrics even in the legacy system, but we did not have distributed tracing. Integration of AWS Lambda functions with X-Ray functionality was one more reason we chose Lambdas over k8s.
- Predictable behavior is an important characteristic of software and it should be considered while evaluating a new technology. The software can have tons of settings and customizations, but if users can’t tweak it to get predictable behavior, they are of no use. This was our biggest problem while working with CheckMK.
- While choosing a new technology, existing knowledge and frameworks within the team are important aspects to consider. We could get this project up and running quickly since we had relevant expertise and tooling already available within the team. That not only reduced the time to production but also eased our operational burden.
- Similar to above, we learned to use managed services wherever appropriate and cost effective. Even though at times the absolute cost of running a service on your own is less than the managed option, operational burden can incur a significant cost.
- Last but not the least, no makeover is perfect and there is often room for continuing to refine the show in further seasons. Our alerting story is not over yet. It will keep evolving and we will need more makeovers. But this one looks convincing enough for upcoming seasons and we can’t wait to take it to production!!!
Appreciation Note
Thanks to Ben Susman, Christian Bayer and Tim Cassidy for all the help with the reviewing and refining. You guys are awesome!!!
If you’re interested in solving problems like this for Commerce Cloud, a leader in the Gartner Magic Quadrant for Digital Commerce, check out our open roles.


