

Zhidong Ke, Kevin Terusaki, Franklin Ye, Narek Asadorian, and Praveen Innamuri all contributed work to the project and this blog post.
With Sales Cloud Einstein, we built relationship intelligence and productivity tools to help sales reps save time by automatically capturing their email and calendar events in Salesforce. We store and manage tons of data to power these features and to train the machine learning models for Einstein.
However, the way we store this data is inefficient for our Einstein teams because they must read in large amounts of data that’s distributed across hundreds of files. So we compact the activity data into fewer, bigger files. We initially assigned a fixed computation resource for each organization. However, each organization has different data volumes and we can’t efficiently utilize resources in a fixed manner with such an unbalanced data distribution set. Separately, there are EU General Data Protection Regulation (GDPR) laws that legally require us to remove certain activity records on-demand. Both of these issues pose unique challenges around managing the storage of our customers’ activities.
With all that in mind, we’ll follow our journey toward a data compaction framework through the following waypoints:
- Activity Data Lake
- Challenges
- Requirements
- The first version of compaction job
- Metadata Store
- Dynamic job scheduler
- Failure recover system
- Use Case and Performance Impacts
- Future work
Activity Data Lake
Our Activity Data Lake, also known as the Shared Activity Store (SAS), is a distributed key-value object store. The ingestion of data takes place in several real time micro-batch jobs depending on the type of data. Specifically, we are using the Apache Spark Streaming framework to implement micro-batch processing of activity data. As Figure 1 illustrates, the Spark Streaming job listens to the Apache Kafka queue and processes activity data by batching activities per organization. Last but not least, the job dumps this activity file to SAS.

Challenge: The Small Files Problem
Our micro-batch streaming job works perfectly for the primary purpose of consistently storing data in real time. However, the micro-batched activity files have caused some side effects downstream. Downstream consumers have seen a decrease in performance due to the large number of files per organization, even though the size of each file itself is miniscule. This is a typical side effect of micro-batch processes and is commonly known as the small files problem. If the ratio of the number of files compared to the average file size is skewed, then you’ll see degradation in performance due to more I/O per input size when processing the data.
One might think that, if we have too many small files, then we should increase the micro-batch window size so that each batch will contain more data. Unfortunately, the trade off here would put more stress on the memory utilization of our Spark Streaming job which could potentially cause data loss or corruption. Keep in mind, we have one Spark Streaming job that aggregates the data of all of our customers by organization. Therefore, organizations that produce a large amount of activity data could cause problems for writing data for other organizations.
Another idea we explored is creating more Spark Streaming jobs that micro-batch data in the same way but read from different Kafka topics. Organizations with high activity volumes would come from a designated Kafka topic and the Spark Streaming Job would have a smaller window size, while organizations with low activity volumes would come from a different Kafka topic, and the Spark Streaming Job would have a larger window size. However, we decided not to go with this implementation for the following reasons:
- Bucketing organizations by data volumes (e.g. high volume, medium volume, low volume) is difficult and could change drastically depending on unforeseen factors.
- Managing multiple Spark jobs and Kafka topics could become cumbersome and was not scalable if we wanted to create more buckets of organizations.
Requirements: General Data Privacy Regulation (GDPR)
In order to be compliant with GDPR, we were required us to support on-demand requests to delete data for the Shared Activity Store. Delete requests could vary between an org wide delete, a user delete, or a deletion of a specific record solely based on an email address. The latter proved to be the most resource-intensive due to the structure of our activity data. In order to complete this request we have to scan all of an organization’s activity batches to a delete specific record. For this specific use case, we again encountered the small files problem for organizations with low data volume.
The first version of compaction job
Our initial design (Figure 2) was a Spark job that read activity data for all organizations. It partitioned the data by organization, and then again into single-day activity batch files. We started the Spark job with a large amount of memory, but the job died after 15 hours because of out of memory issues. We tried increasing the memory as well as the number of executors, but the job still died. And each time the job died, we had to clean up the dirty files.
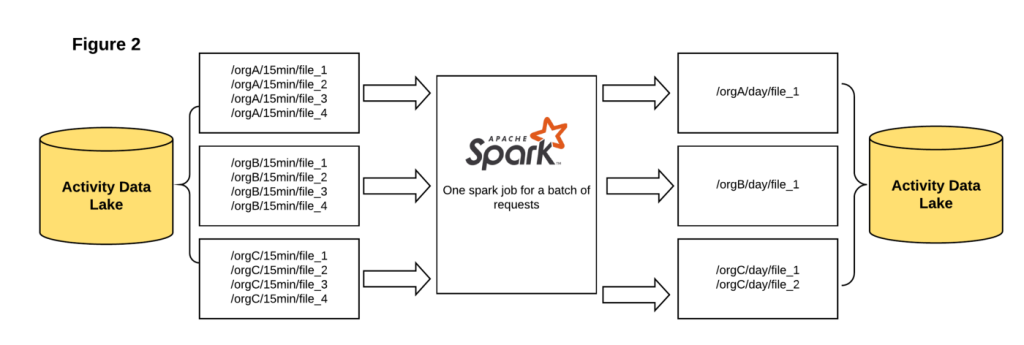
After a few executions, we found that it’s not a good idea to run Spark jobs for an extended period of time because the cost of failure is high. Instead, we broke down a single compaction job into smaller sub-jobs where each sub-job spanned a defined number of days. For example, if we wanted to compact the files for a given organization for the entire year, we created twelve sub-jobs where each sub-job is responsible for compacting the data for a different month of that year.
In most cases, this adjustment worked well. However, for some sub-jobs, the input was too big (around 5T!) and those took more than 10 hours to complete and exhibited high failure rates. Again, we changed our approach. We decided to chunk the input data differently depending on the total input size instead of the fixed time range. We tried to limit the input size to less than 100G per Spark job.
This first version design worked pretty well, but it required too much manual work up front. Too often, we found ourselves calculating our input size for a compaction job to ensure we would not run into memory issues. This process was so slow and painful that we ultimately decided to automate. Much of the manual work to calculate the input size came from just gathering metadata:
- Gathering the total input size (memory of all activity batch files) for an organization
- Given a date range and the total input size, calculating the required number of sub-jobs.
- Monitoring the health of the compaction job
Instead of running the above steps manually, we decided to design a better compaction scheduler that could intelligently partition the sub jobs for a given compaction request based on data lake metadata that we automatically gather. Additionally, we wanted to distribute the sub jobs across multiple Spark jobs to speed up the execution time. We’ll dive into the metadata store, dynamic scheduler, and distributed compaction in the following sections.
Metadata Store
We designed a backfill job to collect the metadata from our activity data lake for the existing data, and we scheduled the near-realtime job to consistently update the metadata storage (Figure 3).
What metadata we store:
- Number of Activity Batch Files
- Average Files Size
- Number of Users
How we collect Metadata:
- Query the activity data lake for file names and sizes
- Perform metadata calculations
- Write those metadata to storage

Dynamic Job Scheduler
Initially, our scheduler had a single worker responsible for the entire date range of crawled files for all organizations. We found that we could improve the resiliency by breaking up each request into smaller sub-jobs, but found it tedious to do this manually. In addition, we wanted the ability to allocate more resources for bigger requests, which resulted in switching to a distributed job flow. For example, an organization with more than 30,000 users requires more than 1 TB of memory, which is why we need a dynamic job scheduler and distributed workers based on the input size.

Scheduling for Distributed Flow
- Each organization is split between workers in a distributed flow based on current resource allocation.
Resource Scheduler
- Now that we’ve gathered metadata, we can intelligently schedule jobs based on the proposed input size. The Resource Scheduler reads average file size, number of files, and total days stored from the metadata store. This metadata helps estimate the size of creating a compacted file for one day, and gives each sub-job a number of days such that the size is not too big (bigger than the memory of the executor).
- The resource scheduler initializes the job state in the database for the compaction job tracker.
Compaction Job Tracker
- The overall request keeps track of all the sub-jobs and their states. Once a sub job compacts the relevant dates, it moves to a completed state and doesn’t need to be processed again.
The failure recovery system
- By breaking a compaction job into multiple sub-jobs, we create checkpoints in addition to memory management so we can recover from unexpected failure. If a sub-job fails in the processing state, it is picked up and completed on the next run.
Distributed Compaction
- After breaking up a compaction request into discrete sub-jobs, we can increase parallelism by running multiple compaction jobs. The Dynamic Scheduler not only creates the sub-jobs, but assigns the sub-job.
Use Case and Performance Impacts
With this new design, we’ve created an intelligent and fault-tolerant compaction framework that can handle large input sizes using a divide and conquer approach. In production, downstream consumers saw a 10x read performance gain. Additionally, this framework allows us to be GDPR compliant with its ability to not only compact files, but to remove activities (e.g. all activities associated with a given email address) related to a GDPR request.
Future work
Although we are quite satisfied with this Compaction Framework, there’s room for improvement.
- We want to build an auto compaction scheduler so compactions job aren’t just scheduled to run, but are triggered by reaching the size threshold of each organization.
- Dynamically increase the number of worker nodes depending on the number of sub jobs scheduled, allowing us to efficiently schedule compaction jobs based on the current demand.
- Sub Job compaction performance tuning to decrease the runtime of the compaction job process.


