At Salesforce we take pride in bringing innovations and new capabilities to our customers. However, first and foremost, we want to make sure that we create an environment of trust. In this post, we introduce an open source tool we developed to keep our systems operating with a high level of availability, security and performance.
Security patches: What’s the big deal?
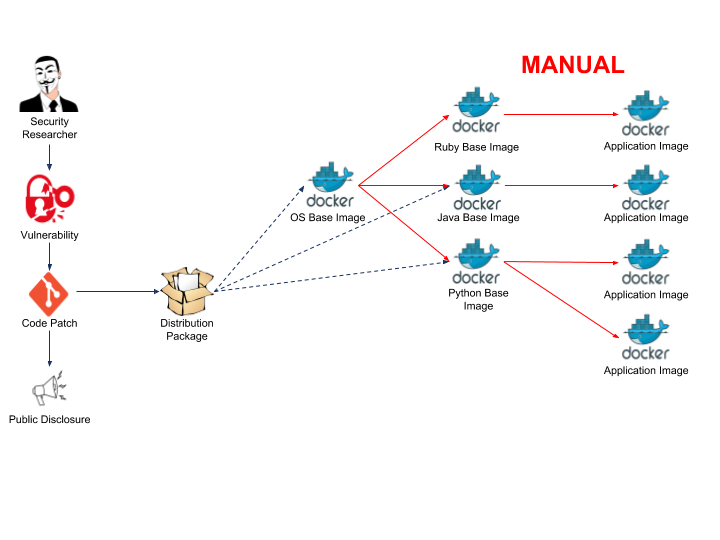
Security patches come in many forms. The recent Meltdown and Spectre vulnerabilities are great examples to use. Deploying patches to remediate these vulnerabilities requires an immense amount of effort from operators and software engineers.
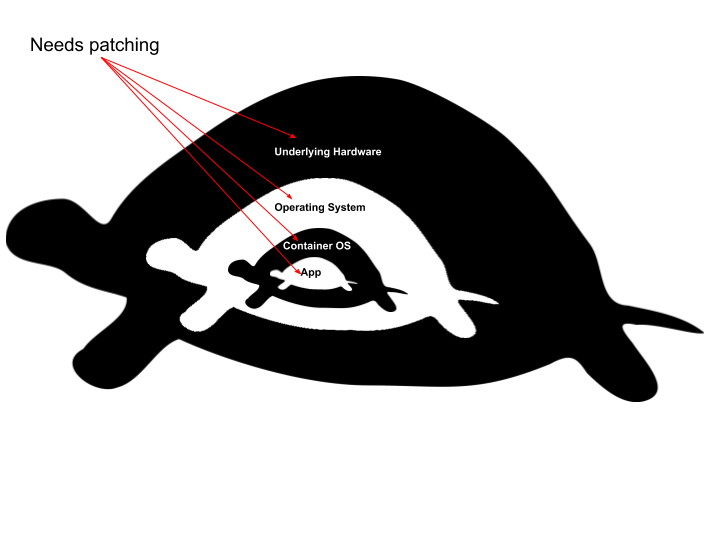
First you need patch to the underlying hardware, next comes the operating system that runs on the hardware. Patching these two can be done by rolling through physical hosts in an organized manner. So long as we have enough extra capacity, our users don’t notice any degradation because our applications are already instrumented to support individual hosts going down. We are big fans of Kubernetes and let it do the heavy lifting here. So far so good.
Patching the Container OS and application that is run on top of it is a lot trickier though. When you update your container base OS image, that doesn’t necessarily mean that your application image is updated. The greatest strength of Docker, immutability, becomes a drawback. A Docker’s container immutability means that you must rebuild all of the subsequent layers of the container image in order to make any changes. A lot of things go wrong:
- The base OS image likely gets more security updates than your application. Are you always going to remember to rebuild your application image when the base image changes?
- Your application might depend on a specific base image version. Unless you’re overwriting that version when you build your base image, your application will continue running on the vulnerable image.
- What if the base image security patch breaks the application?
- What if you have a set of intermediary images? Are you going to remember the order in which to rebuild those?
- How will you notify all of your developers that they need to rebuild their images? How are you going to verify that they actually do it?
Introducing Dockerfile Image Update
We decided to tackle the problems above by building a tool that would integrate with our CI/CD system. Our system was already building, testing, and publishing our Docker images, so why not add an extra step that would scan our GitHub repositories and send pull requests to all of the projects that need to be rebuilt?
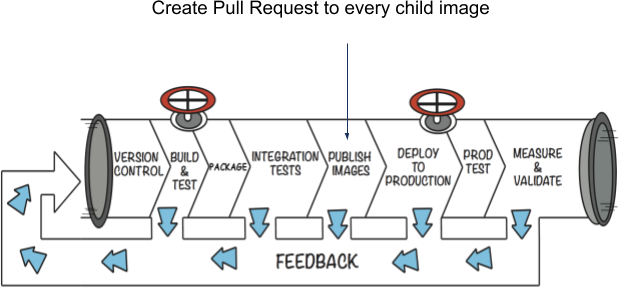
As with most software projects, it was easier said than done. The tool was designed to be run with three main modes:
- Child — Given a specific repository the tool sends a pull request to bump the image tag to a specific string. You can optionally store the image to tag mapping in a separate Git repo that is used for persistence.
- Parent — Given a specific image and tag, search GitHub for anything that depends on that image and send a pull request to bump the tag of discovered images. The intended state is persisted to a separate Git repo.
- All — Scan the full tree of images as declared in GitHub and send pull requests to those images that deviate from the intended state.
Initially, we designed our system to only run the Parent mode during publish images, however we realized that we were leaving additional cases uncovered. Developers could merge a change with out-of-date tags from their local repository. Race conditions and faults could also arise where a developer could merge their pull requests out-of-order. To alleviate these problems, we added an additional mode, All, that would run nightly and make sure to get things into their intended state. Refer to our project’s README for more information.
Putting theory into action
Today, we have about 200 images using our system. All of our CI/CD pipelines are generated from a user declaration. This strategy made it very easy to roll out the tool. If you are using Jenkins today, we recommend you use a Jenkinsfile shared library.
One major benefit we have with our overall pipeline — and that we recommend you also have — is an integration phase where users spin their Docker containers up and run black box tests against them. These tests are intended to run during the pull request phase, so if there is a breaking change anywhere in any of the parent images, users get the feedback well before their containers are in production. In theory, for performance sensitive apps you can add an additional phase to run performance tests in an environment suited for that.
Together, all of these pieces ensure that patches go out quickly without breaking anything. Before we rolled this tool out, we’d waste time deploying containers that would fail security scans because images were built out of order. This is no longer the case. As a corollary, we are able to run reports on unmerged Dockerfile image update pull requests and find abandoned or unmaintained projects.

Future work
We haven’t covered all use cases yet. Not all images are declared in Dockerfiles. We need a way to support other Docker declaration tools such as the Maven Spotify Docker plugin. Other users generate their own Dockerfiles, which throws another wrench in our tool. Beyond Dockerfiles, we still have to patch Go libraries, Maven and Gradle dependencies, Python packages, and others. It would be great if we could have a tool that would auto-update everything for us. While we’re at it, when are we going to have a tool that writes code for us? Dockerfile-image-update and the ideas behind it are now open source, so please bring your use cases, pull requests, and let’s collaborate!
Acknowledgements
Special thanks to Min-Ho Park, our summer intern who wrote the initial version of the Dockerfile-image-update. Additional thanks to Justin Harringa, Nelson Wolf, and Jinesh Doshi who were very involved during the design and rollout phases.
Follow us on Twitter: @SalesforceEng
Want to work with us? Let us know!