In our “Engineering Energizers” Q&A series, we shine a spotlight on the innovative engineers at Salesforce. Today, we feature Lovi Yu, a Senior Software Engineer on the Data Cloud Model Management Lifecycle team. Lovi helped develop multi-DMO support in Data Cloud Model Builder, a groundbreaking feature that allows customers to build predictions across multiple related data objects for the first time.
Learn how the team meticulously balanced functionality with SQL query performance through extensive trial-and-error testing, tackled UI navigation challenges with caching and progressive disclosure techniques, and ensured 99.999% reliability through rigorous quality assurance at an enterprise scale.
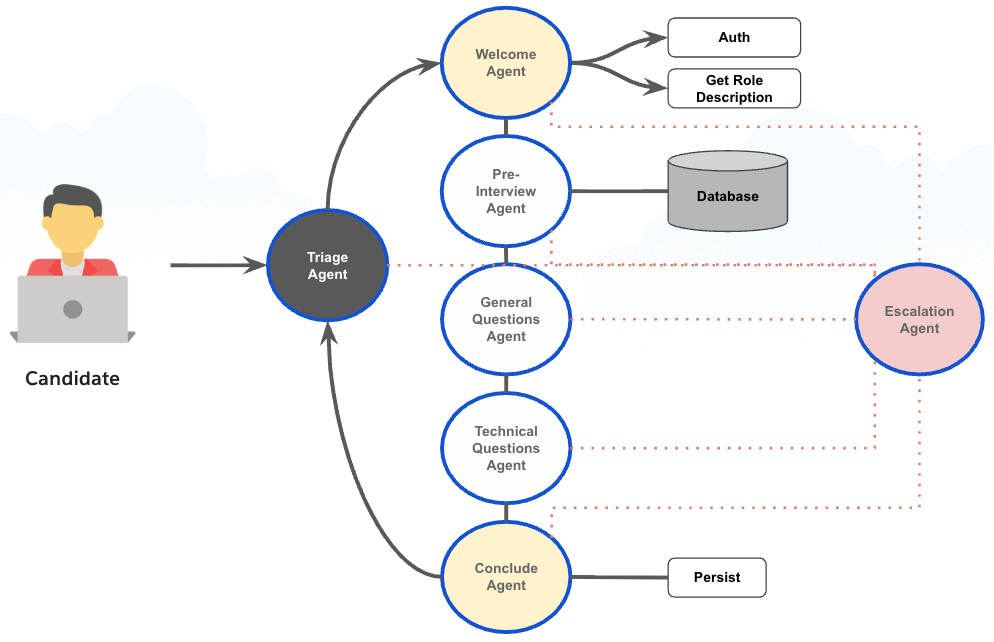
What is your team’s mission building Data Cloud Model Builder?
Our mission is to empower customers to leverage both predictive and generative models with their Data Cloud data, enhancing productivity and helping them reach their business targets more effectively. While the power of generative AI is very exciting and seemingly endless, predictive models remain a very powerful tool. Data Cloud Model Builder allows user to use both, whether they solve their use case by using one or the other or in combination. We offer flexibility in model creation, allowing customers to build models with clicks or integrate existing models from third-party platforms such as AWS SageMaker or Databricks.
Our team is dedicated to creating seamless UI and API experiences, ensuring that the interface is intuitive and user-friendly while maximizing the capabilities of predictive modeling. This focus on user experience is crucial for making advanced technology accessible and valuable to our customers.
The true value of predictive modeling is evident in practical use cases. Rather than applying one-size-fits-all solutions, our models analyze data patterns to determine whether specific customers respond better to BOGO offers or 10% discounts. This targeted approach not only increases efficiency and effectiveness but also sets businesses apart from competitors who rely on generic strategies. By harnessing the power of data-driven predictions, our customers can make more informed decisions and drive better outcomes.

Training a model with multi-DMO can help our customers solve more complex cases.
What customer limitations and pain points drove your team to build multi-DMO support?
The primary driver for introducing multi-DMO support was customer feedback requesting the ability to solve more complex use cases. While many scenarios can be addressed with a single DMO, multi-DMO enables users to handle more intertwined data, elevating the accuracy and depth of their predictions.
This need for feature parity highlighted a significant pain point: in relational database architecture, customer data is often spread across multiple connected tables rather than being contained in a single object. Previously, customers had to use workarounds like calculated insights, which generate SQL statements to consolidate related data into a single computed object. While this approach worked, it required creating new data structures instead of leveraging existing relationships.
With multi-DMO support, Data Cloud now provides the flexibility customers need. They can build accurate predictions without the hassle of creating new objects when relationships already exist. This feature allows for the integration of related data across multiple objects, such as:
- Loan Data: Credit scores, loan amounts, default history
- Employment History: Job tenure, number of positions, industry changes
- Financial Records: Income levels, transaction patterns, payment behavior
By connecting this data, multi-DMO support delivers far more accurate predictions than single-object models, enabling customers to make more informed and effective business decisions.
Lovi shares the power of Cursor, a new AI tool for her team.
What SQL performance challenges did your team overcome building multi-table machine learning models across relational databases?
The biggest challenge we faced was balancing functionality with query execution time. Customer data can have unlimited relationship depths, potentially extending hundreds of levels deep. We needed to set practical traversal limits while maintaining scalability and high-quality support. This balance impacted every team’s function:
- UI Team: They couldn’t store all relationship data upfront, so they had to implement a level-by-level database drilling approach.
- Backend Teams: They grappled with the complexity of SQL statements when joining multiple tables.
- Performance Teams: They evaluated query execution times across different join configurations.
- Product Management: They needed to find solutions that made sense for users while maintaining high quality.
Each of these constraints fed into a critical downstream concern: the decision impacted inference latency when making actual predictions. To address this, the team conducted extensive trial-and-error testing. We evaluated the performance impacts of three joins and then tested one join at ten levels deep to assess the UI experience difficulty.
Ultimately, we settled on one join with three levels of traversal for the first iteration. This decision was influenced by the natural isolation provided by org boundaries, which meant that scalability challenges common in distributed systems were not an issue. Each org functions independently within the replication process, so our primary bottleneck was query execution time, not cross-org coordination overhead. This approach effectively solves numerous use cases while allowing us to plan for future enhancements that will support additional joins.
Lovi shares what makes Salesforce Engineering culture unique.
What database navigation challenges emerge when building Lightning Web Components interfaces for non-technical users?
The main challenge we faced was the difficulty of storing relationship data upfront at scale. As users move through objects, we continuously drill into the database at each level. We needed a UI design that was easy to use, clearly showed the user’s position within relationship paths, and helped them find target fields quickly.
To tackle this, we built the solution using Lightning Web Components, with close collaboration between engineering, product management, and UX design. This ensured that our technical implementation matched how users naturally think about navigating relationships. System responsiveness was crucial — users shouldn’t have to wait ten seconds for data to load.
We implemented three key strategies to address these challenges:
- Caching Optimization: When users traverse the relationship tree, we retrieve cached results instead of making repeated database queries. This ensures that navigation remains fast and smooth.
- Search Functionality: Users who know the field names can simply type them in, rather than manually navigating through complex relationships.
- Intelligent Filtering: We removed unusable fields, such as standard timestamp fields like last modified date, which can’t be used for predictions. This reduces visual clutter and makes the interface more user-friendly.
Our team also customized standard Lightning Web Components with progressive disclosure patterns. Each level of the relationship tree loads on-demand, rather than fetching the entire graph upfront. This prevents memory bloat and keeps interactions responsive, making it easier for non-technical users to navigate through intricate data structures.
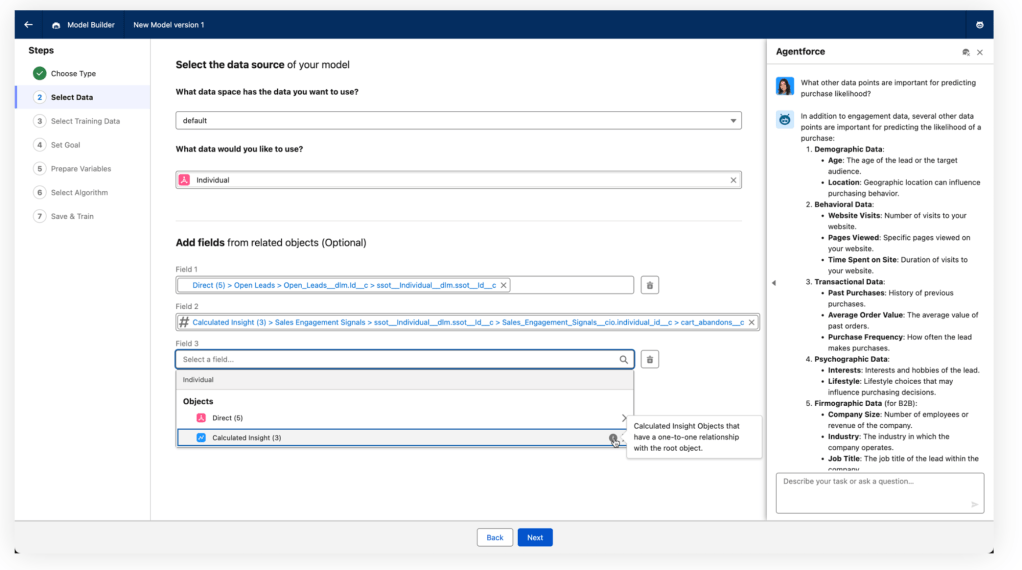
Users can now traverse from their primary DMO and select fields on related DMOs or calculated insights.
What reliability and scalability challenges arise when maintaining machine learning prediction quality across multiple data tables?
The biggest challenge we faced was query execution time. While finding UX solutions for traversal was difficult, the more significant obstacle was the SQL response latency when joining multiple tables. Executing queries with ten table joins can take a considerable amount of time, leading to throughput concerns that required careful evaluation.
To address these performance issues, our team prioritized rigorous quality assurance, as trust is our top principle. We invested a lot of time in automated testing, covering several areas:
- Unit Tests: These validate individual join operations to ensure they work correctly.
- Functional Tests: These ensure that predictions remain accurate across relationship chains.
- Performance Tests: These measure query execution times under load to maintain system responsiveness.
Our test framework is designed to validate that inference latency remains consistent as customers scale from simple single-object models to complex multi-table joins. We use internal dashboards to monitor availability and success rates, aiming for five nines (99.999%) reliability, which translates to less than 5 minutes of downtime annually.
We never release features without being confident in their performance across all customer environments. Before shipping any capabilities, we thoroughly validate that the solutions won’t cause issues in any configuration. This conservative approach led us to start with a single join rather than waiting to support ten joins. The single-join solution addresses many use cases immediately, while we continue to iterate on performance improvements and scalability enhancements. This ensures that we can eventually support additional joins without degrading prediction quality or system reliability.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.