Imagine you’re choosing between two burger joints.
On your left is McStandard, which always makes their burgers the same way. On your right is Meta King, the burger joint that lets you declaratively customize your burger and have it exactly the way you want it. All things being equal, which would you choose?
I don’t know about you, but I’d choose customization every time. (Especially if those burger joints were thinly veiled analogies for software architecture.) And in the domain of software, customization means that your software’s behavior must be flexible, not hard-coded. It needs to be based on metadata.
In this episode of the Architecture Files, we’re going to talk about the basic approach we take to metadata within the Salesforce architecture, to give you a glimpse into why it’s so important, and how we do it.
Metadata can be a bit of a nebulous term, so let’s start by talking about what it really means.
Everything a computer works with is data — ones and zeros — from the firmest firmware to the most ephemeral state of a pixel on the screen. By metadata, however, I’m talking specifically about data that describes or constrains the behavior of software. It’s what tells us that this byte is an instruction in the OS, and that byte is one pixel in a catchy song about cheeseburgers.
Now, let’s clear something up right away: by “metadata”, I specifically don’t mean just “additional data”, like a timestamp, or a browser fingerprint. It’s certainly not uncommon to hear people use the word that way (“I want to know what metadata these fast food companies are collecting about me …”), but that’s not at all what I’m talking about here. That’s “meta” if you’re talking about the original Greek sense of the word (“beyond”), since things like this are beyond what we usually see in the user interface. But you probably weren’t talking about the original Greek sense of the word, were you? No. So for the purposes of this article, let’s go with my definition: metadata is data that alters the behavior of software.
Now, in the context of Salesforce’s architecture, we can get a little more specific. In our case, metadata covers a spectrum of ways that our customers can alter the behavior of our multitenant software. That spectrum ranges from “more constrained” to “less constrained”:
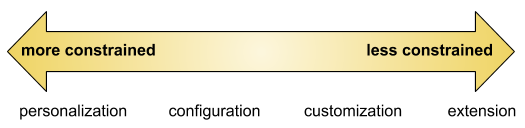
On the left side, metadata has a very concrete and simple effect on behavior.

An example would be a user-level setting for something like “show high contrast on charts”. This shows up as a per-user checkbox that has a single purpose: if checked, the system will display charts for that user using an alternate color scheme designed to make it easier to read text. Simple! (And yes, this is a real option in our configuration settings, because that’s actually something that matters for people with special vision accessibility requirements!)
On the right side (customization / extension), metadata can have a much more open-ended impact on the system’s behavior.

This is where you work if you want to define complex and arbitrary new behaviors — say, things that the Salesforce engineering team never considered, which change the system in unforeseen ways. This includes code (like Apex), process flows, rules, custom APIs, Lightning Components, etc.
And in between … well, it’s a spectrum. Every kind of metadata — user preferences, picklists, roles and profiles, analytics dashboards, etc. — lives somewhere on this spectrum.
Salesforce exposes a ton of metadata through our Metadata API. Most of it falls in the vicinity of “per-customer configuration” (from simple toggles, up through complex things like report definitions), though it exposes some things from the other end of the spectrum as well (like Apex classes). Every type in that Metadata API represents some specific way our engineering teams have made our software flexible, open to runtime adjustment. (And in addition to these pre-defined types, we also offer the ability to create custom metadata, so that customers and partners (like ISVs) can add configurations that their code will obey.)
While there’s no hard and fast rule, it’s generally true that things on the left side of the above spectrum are declarative (structured data values that code will inspect and obey at runtime), whereas things on the right are imperative (a series of steps, with control flow and encapsulation). In other words: the former is configuration, and the latter is code.
Declarative and imperative approaches are both useful, but they’re different. Speaking in very broad generalities, our declarative platform is the way we embody all the things we’ve learned over the years — our accumulated domain expertise at building systems for business users, encoded in such a way that non-technical customer users can use it to deliver real value, with minimal cost. In most cases, we can build simple point-and-click tooling on top of the declarative metadata that means anyone can interact with it, even if they have little or no technical expertise.

On the other end, the imperative side of the platform is our acknowledgement that, as much as we know what makes people happy in the domain of business software, we can’t know or build everything. Some problems require piercing the abstraction entirely, and letting people craft entirely new kinds of behavior that we didn’t think of.
Generally speaking, we follow the advice to “Make simple things simple, and hard things possible.” That means that most stuff you need should be doable via the declarative side of the spectrum; crossing over to the coding side should be reserved for cases where you need especially high levels of control, like pixel-perfect user interfaces or highly complex business processes. Everything else valuable should be customizable via declarative metadata.
It’s also worth noting that this “crossover” point isn’t static. Our engineering teams are continually enhancing the declarative capabilities of the platform, so something that initially requires custom code may eventually become something that can be done declaratively. As we grow, we discover new general business software problems, and things that previously appeared to be too customer-specific or complex become more viable to address in the declarative platform.
Is one end of the spectrum better than the other? No, they’re just different, like “fried vs flame broiled”. The declarative approach is usually closer to what we mean when we say the word “metadata”, but they both count.

But … It’s Really About Schema, Right?
One particular flavor of metadata deserves special attention: schema. Schema is the shape of the data that customers store in the system to do their work (Accounts, Contacts, Widgets, etc). It’s composed of objects, attributes and relationships. Objects (also known as Entities) are “named containers” for data, and Attributes (aka Fields) define the internal makeup of that data — for example, the fact that a Contact has a first name, last name, etc., and belongs to a particular Account (a relationship).
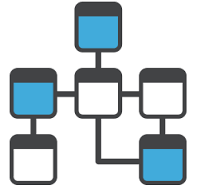
Like other metadata, schemas are mostly configurable per-customer, because each customer’s business is different. (For example, MetaKing might add “favorite soda flavor” to their “customer” object, whereas other customers wouldn’t care.) Schemas are defined declaratively, but they’re still pretty far to the right on the spectrum, in that they have a broad (unconstrained) impact on the system’s behavior. When you create Custom Objects to represent your business concepts, you can essentially transform Salesforce from a CRM system into anything you can imagine: a financial ERP, a health care system, a non-profit admin system, and more. So, schema is an extremely potent and important form of metadata.
Salesforce schemas are actually much richer than traditional databases. Beyond tables, columns, and data types, we also include lots of attributes about governance, classification, searchability, compliance, etc. A full list of the dozens of public settings on objects is here, but a few examples include:
- description — some text (1000 characters or less) about what this object is meant to be used for
- enableHistory — whether the system tracks historical changes to records in this object or not.
- enableStreamingApi — whether this object is enabled for the Streaming API feature to get push notifications of changes to this object’s data. (There are dozens more “enableX” settings for various behaviors, in fact.)
- gender — Yes, that’s right, gender. This is for localization; our system’s grammar-aware translation engine (which we released as open source, BTW) needs to know how to treat instances of this object in languages that gender their nouns.
You won’t find things like “gender” in the schema of most relational databases. Why does Salesforce have it (and hundreds of similar types)? Because the Salesforce data model is embedded in a running software application, and that application includes a wealth of behaviors on the objects themselves. That’s what’s really valuable: anybody can install a database, but Salesforce offers one that’s surrounded and supported by tons of other functionality: user interface, APIs, reporting, search, workflow, chatter, etc.
The set of available field types is also a lot richer than the “string” and “number” options you get in most relational databases; if you look at our list of field types, you’ll see things like:
- Phone, Email, URL, etc, which are strings with different display data;
- ComboBox, which is like a picklist that allows the user to also type in their own value;
- Calculated, which are fields defined by a formula based on other fields, expressions, or values.
- PersonName, which has special logic around how to show human names;
And so on. While a lot of these are just specializations on other types (a “phone number” is ultimately just a string, right?), the deeper typing here gives our system a lot of behavioral options that we wouldn’t get otherwise—not just data validation (which is important) but also tips to other parts of the system about how to behave (for example, as inputs to more specialized machine learning algorithms).
And there are a variety of other mechanisms, too: relationships (connections between object records), generalization (connecting related objects with super- and sub-typing) and access control (restrictions on which users can actually get to all this data).
Now, I made the point above that all of this is customizable for each customer, because it’s based on metadata. This is true, and important. But if that’s all we had, it wouldn’t be a great “out of the box” experience. It’d be like walking into a burger joint and being told “Oh, sure, you can have fries. Here are some potatoes and a knife, and the deep fryer is over there.”
For this reason, parts of Salesforce’s data models are actually shared, not specific to any one customer. Many of the most common entities you’ll work with in Salesforce aren’t defined by each customer separately, but by Salesforce engineers (using a mostly-declarative system called the UDD, or “Unified Data Dictionary”). This means that our internal engineers can efficiently add new entities (objects) and attributes (fields) across all customers, in service of the products they’re building. Customers can complement the majority of these objects with additional “custom fields”, but the objects themselves come “out of the box”. At last count, there are several hundred customer-accessible standard entities like this (which you might not interact with unless you buy or enable a particular feature).
We also support shared entities defined by third parties, called ISVs (independent software vendors). Our system provides them ways to package and resell their own code and data models on our platform, which get instantiated for every customer that has installed their package. (So, if you want “inventory management” objects in your org, you could create them all yourself … or you could buy and install an ISV app that defines all these objects for you, at which point the ISV controls those definitions, not you.) This ISV ecosystem is a critical part of our success: it’s a “marketplace of ideas” that can build things our customers want, but that aren’t on our roadmap. We even have some open source packages (like Salesforce.org’s Non-Profit Success Pack)!
So ultimately, the schema for a customer is composed of a mixture of standard objects (defined by Salesforce engineers), packaged objects (defined by ISVs) and custom objects (defined by the customer themselves).

So that’s one of the big things that really distinguishes the Salesforce software stack. Not only do we offer a powerful set of out-of-the-box products for Sales, Service, Marketing, Commerce, etc, but we allow each tenant to bend the software to their own needs, through extensive use of metadata that lets them express the needs and shape of their own business — without us having to change any of our code. The system is deeply malleable, by every customer, in real time. And, most of it can be changed without the help of highly skilled programmers — people with a few trailhead badges under their belt can do it. But it’s also rich and layered enough that an entire ISV ecosystem can exist on top of it, with partners who create their own packages to extend the schema and functionality of Salesforce.
But … can you have too much of a good thing? Sure! If you walk into a burger joint and they had to ask you what kind of napkins you want, what flavor of ketchup, etc. … that’d be a hassle, not a value.
Every time an engineer writes a line of code, they’re making a choice about behavior — and a complex system like Salesforce is composed of millions of these tiny (and not so tiny) choices, made over a space of years. Should we let the user change their time zone? (Yes!) Should we add standard fields to every contact record to store a person’s Twitter handle? (Maybe … ?) Should we have an configuration option to replace all system buttons with clown faces? (Probably not …)
The point is, every point of configurability has a (small) cost, and the costs add up over time, in a couple ways:
- There’s a cost for the software development team — all things being equal, hard-coding is simpler to create and maintain, if it’s not something that really needs to change.
- There’s a cost for our end users: complexity (i.e. cognitive burden). This can really accumulate over the years, as your system gets more mature. (There’s a reason that even “Salesforce for Dummies” is 434 pages long at this point …)
So, it’s not just about “more”; a lot of our effort goes into weighing the business value of customizability. We do the research and figure out not just what is theoretically possible to customize, but what’s actually valuable to customize. That’s why we don’t always answer with a “yes” when a customer suggests making some specific aspect of the software metadata-driven. (Though, of course, when enough people ask for something, that’s a strong signal that it is valuable, and that’s why we put such a premium on retiring idea exchange points each release.) We have to balance the needs of the many against the needs of the one; and, of course, for the things we don’t choose to make metadata-driven, that’s what the coding end of the spectrum is for!
Metadata is the bedrock of Salesforce, and it matters a lot more than you might expect. It goes way beyond asking for extra ketchup; as the recent article in Wired explains, well-groomed metadata for our customers’ business data models is part of the secret sauce that makes Einstein possible. Because the system is already richly intelligent with respect to the shape and nature of each customer’s logical model, adding in algorithmic enhancements based on AI and Machine Learning is a natural next step. (And that’s definitely something we’ll talk about in a future Architecture Files episode!)

Got questions or ideas you’re grilling up, about how metadata interacts with software? Let us hear em!
Big thanks to the folks who contributed to and reviewed this post: Susan Levine, Kelly Henvy, Lars Martinsson, Leo Tran, Bill Jamison, James Ward, and Nate Horne.