

There’s a class of scalability challenges that are best approached using an asynchronous, event-driven architecture — particularly when it comes to doing data integrations. To support these uses cases Salesforce recently added a feature called “Platform Events” which exposes a time-ordered immutable event stream to our customers. Our multitenant setup posed some challenges for traditional messaging systems and luckily Apache Kafka came to the rescue by inspiring us to leverage the time-ordered event log paradigm. This post will detail the unique needs we encountered and how event logs helped us address those.
I joined Salesforce 5 years ago with a charter to improve the Salesforce Platform’s integration capabilities. Back then, data integration with Salesforce was mostly done by moving datasets in or out via the REST and SOAP APIs. Business process integration was done primarily by making web service calls via Apex.
Looking back at our progress since then, we’ve made incredible strides. The platform’s integration toolkit now includes external objects that provide data virtualization and federated query capabilities. But we also needed to better support business process integrations and event-driven architectural patterns, and that’s where Platform Events come in.
Enterprise Developers Need Events
As Enterprise systems grow, they tend to become more complex. Teams gradually add more and more independent services, with different development lifecycles, and eventually the system invariably reaches a point where decoupling these services becomes critical. Thus, a shift towards asynchronous interactions is a natural evolution; enterprise developers love event-driven architectures because they provide the runtime independence you need to tame this complexity.
As we talked to customers and ISVs, we found they were already building asynchronous applications on the Salesforce Platform. But, in the absence of native support, they had to emulate queueing with custom objects. This caused a lot of extra work and considerable runtime overhead, so customers had to maintain fragile and slow systems, and pay extra storage fees on top of that. This approach also tended to increase the load on our service, because it was not an optimal architecture for asynchronous events. We quickly came to the conclusion that delivering first-class eventing capabilities was an important feature — one we needed to add.
To address the widest range of event-driven applications, we settled on using a publish/subscribe model. This approach is more flexible than direct point-to-point messaging; a topic with only one subscriber can be treated just like a point-to-point queue, but you can’t go the other way, because a purely point-to-point queuing infrastructure can’t be easily exposed to multiple simultaneous (and independent) consumers. Based on our analysis of existing and potential use cases, we also included subscription durability (the ability to persist in-flight messages for some period of time) into the list of design requirements, so the system would be useful for more than just transient use cases.
Multitenant Pub/Sub is Tricky
Event-driven architecture is hardly new — there are a wealth of tools and frameworks, and an established set of patterns for building systems that interact asynchronously. But, that doesn’t mean those patterns are simple; in a typical enterprise application, the footprint of messaging infrastructure is significant, including a broker (or a redundant set of brokers, for high availability), a reliable storage system (for backing durable subscriptions), and a bespoke configuration of queues and topics for routing of the events.
The challenge for us was to transplant those concepts and patterns into our multitenant platform. Applications on the Salesforce Platform are metadata-driven; many tenants coexist on top of a shared, multitenant infrastructure. It doesn’t work to use the standard approach based on routing configuration files, because routing for each tenant might be different. Plus, there’s no (economical) way to spin up a new set of brokers for each individual tenant.
Subscription durability over traditional messaging protocols such as AMQP is achieved by individual acknowledgement of messages. This means that to the broker, each durable subscriber has to have its own private queue. A typical implementation of a durable subscription in the JMS/AMQP world amounts to a shared topic for notifications, and a subscriber-specific persistent queue. But the Salesforce platform deals with tenants that number in the hundreds of thousands, each of which may have multiple subscribers. Even if only a fraction of them required subscription durability, that would be a lot of state to hold on to in this way.
Based on this analysis, we concluded that it didn’t seem feasible to directly reuse any of the existing message broker products or frameworks.
Event Log to the Rescue
As we were first architecting this system, Apache Kafka was getting more and more popular inside Salesforce, and its simplicity and reliability seemed appealing. Kafka does not use a traditional queuing paradigm, but instead arranges events in the form of an immutable time-ordered log. It inspired a breakthrough in our search for a multi-tenant pub/sub architecture — in all the ways that a traditional message queue wouldn’t work for us, the Kafka paradigm seemed to fit the bill.

In this model, events are immutable and are stored on disk in a form of a time-ordered log. Publishers always append at the head of the log. Each newly written event is assigned a new offset — this is the point when its relative order is established. Subscribers can read events at their own pace. If a subscriber has to reconnect, it can supply the “last seen” offset to resume exactly where it left off. To conserve resources, the oldest events can be periodically purged. In this case a subscriber can miss events if it falls behind for more than the retention period.
There are several benefits of this model: each message is stored on disk precisely once, regardless of how many subscribers consume it. Tracking of a subscriber position can be the responsibility of the subscriber, so the broker does not suffer from a state explosion as it services more and more subscribers. Offset-based subscription durability ensures, and even dictates, strict order of events.
What About Schema?
What we’ve been talking about so far might best be described as “temporal decoupling”– a publisher does not have to worry whether a subscriber is available at exactly the same time it wants to publish a message, and a subscriber does not have to worry about temporarily losing a connection (since the messaging infrastructure ensures that the messages are preserved on publish and eventually delivered to subscriber).
But what about the contents of the message? If the publisher and subscriber need to agree on exactly how the message is formatted, it creates a different kind of logical coupling that might be just as bad: a private handshake that limits the growth of the system over time, and forces pairs of consumers and producers to directly depend on each others’ implementations.
Our solution is to have all participants in the system share a metadata repository that allows publishers and subscribers to evolve completely independently! You can think of it like this: a service might have a “story” to tell to the rest of the world. So it frames that story in a schema, and starts placing events of that schema on a topic. As long as the schema is published in the metadata repository, subscribers can discover the new message types and start listening to them completely independently from the publisher. A metadata repository, and an associated discovery mechanism, enables application lifecycle decoupling, which works well for large-scale integrations in the enterprise systems.
It turned out that the Salesforce Platform’s rich metadata management layer works well for event metadata, too! Events can be defined as custom entities and their custom definitions can be used as a schema for event serialization and consumption by the subscribers. So, this acts as our schema repository, and it comes with all the design tools, packaging and integration that Salesforce has built over time to power sharing apps in our ecosystem (with the AppExchange). In addition, we translate event definitions to Apache Avro so subscribers can consume events in this highly efficient serialization format with libraries in many language environments.
Platform Events are Time-Ordered and Metadata Driven
So, to sum up, Platform Events combine the elegance of a time-ordered event log with the power of Salesforce’s metadata layer.
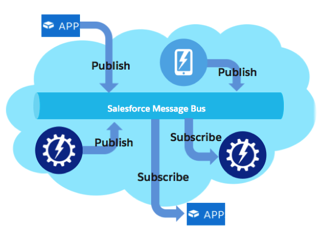
Events are defined just like custom objects. Subscribers can discover and describe them in the same ways as any other metadata: in the Salesforce Setup, Development Console, via Describe, Tooling, or the Metadata API. Subscribers can tap into the topics on the platform via Event Apex Triggers, Process or Visual Flow. For external integrations, topics are exposed via the Salesforce Streaming API. Publishers can live within the platform: Lightning, Apex and Visual Flow can send platform events. External publishers can use any form of SObject API that can save an SObject — Platform Events are first-class Salesforce Objects after all!
By building on Kafka and the Salesforce metadata system, we were able to add enterprise-ready, event-driven layer that has delivery and ordering guarantees, all the while living securely within our multitenant system!
Follow us on Twitter: @SalesforceEng
Want to work with us? Let us know!



