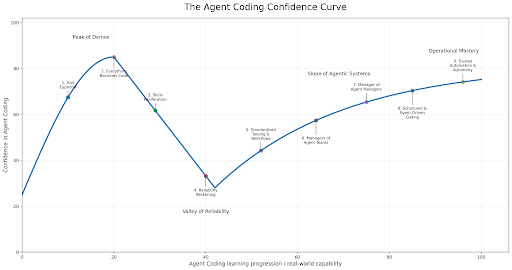
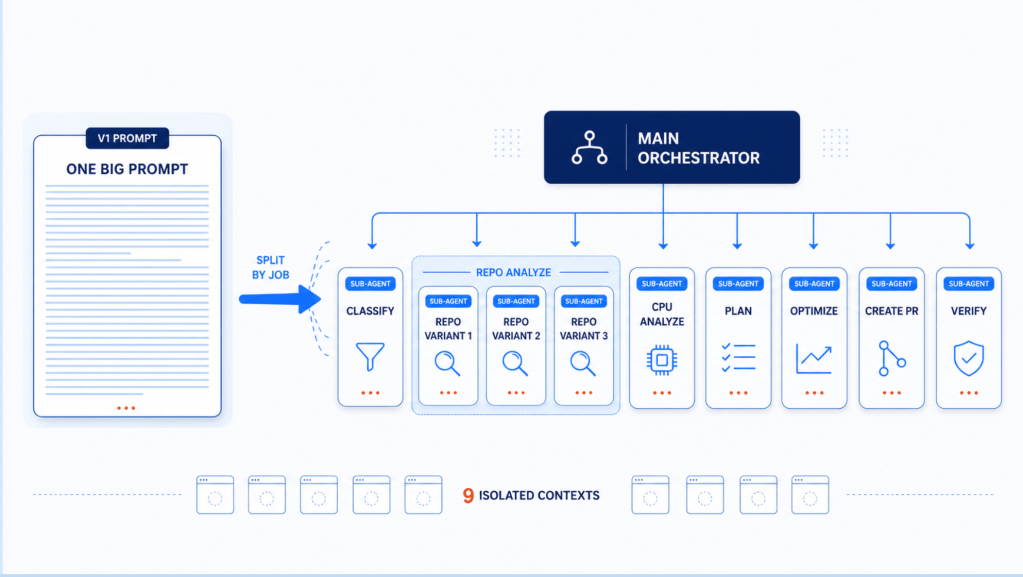
By Amit Sharma and Antonio Garrote.
How do you know whether code generated at agent speed can be trusted? That question is fast becoming one of the most important in software engineering and it deserves a serious answer.
As AI coding agents grow more capable, many of the traditional bottlenecks in software development are dissolving. Code gets generated faster than engineers can review it, features land faster than they can be tested, pull requests grow faster than existing processes can safely absorb. The result is a new kind of engineering problem. Success is no longer set by how fast you can produce code, it is set by how fast you can build confidence in it.
At first read this sounds like a productivity story, but it is not. The striking part was not the speed of generation. It was the discovery that generation had become the easy part. Once implementation sped up, the constraints did not disappear, they moved. Testing, code review, CI/CD and validation all got harder. The central question shifted from how quickly we could generate code to how quickly we could trust it.
If you are adopting agentic engineering, you will hit the same wall. The way through is not a better prompt or a faster tool. It is an engineering model — a set of architecture choices, repository patterns and workflow gates that let many agents build in parallel while the team keeps its confidence in the result. The 7 patterns that follow are the model Salesforce’s Agent Fabric Salesforce built to get past that wall. They are deliberately tool independent so you can apply them on whatever stack you run.
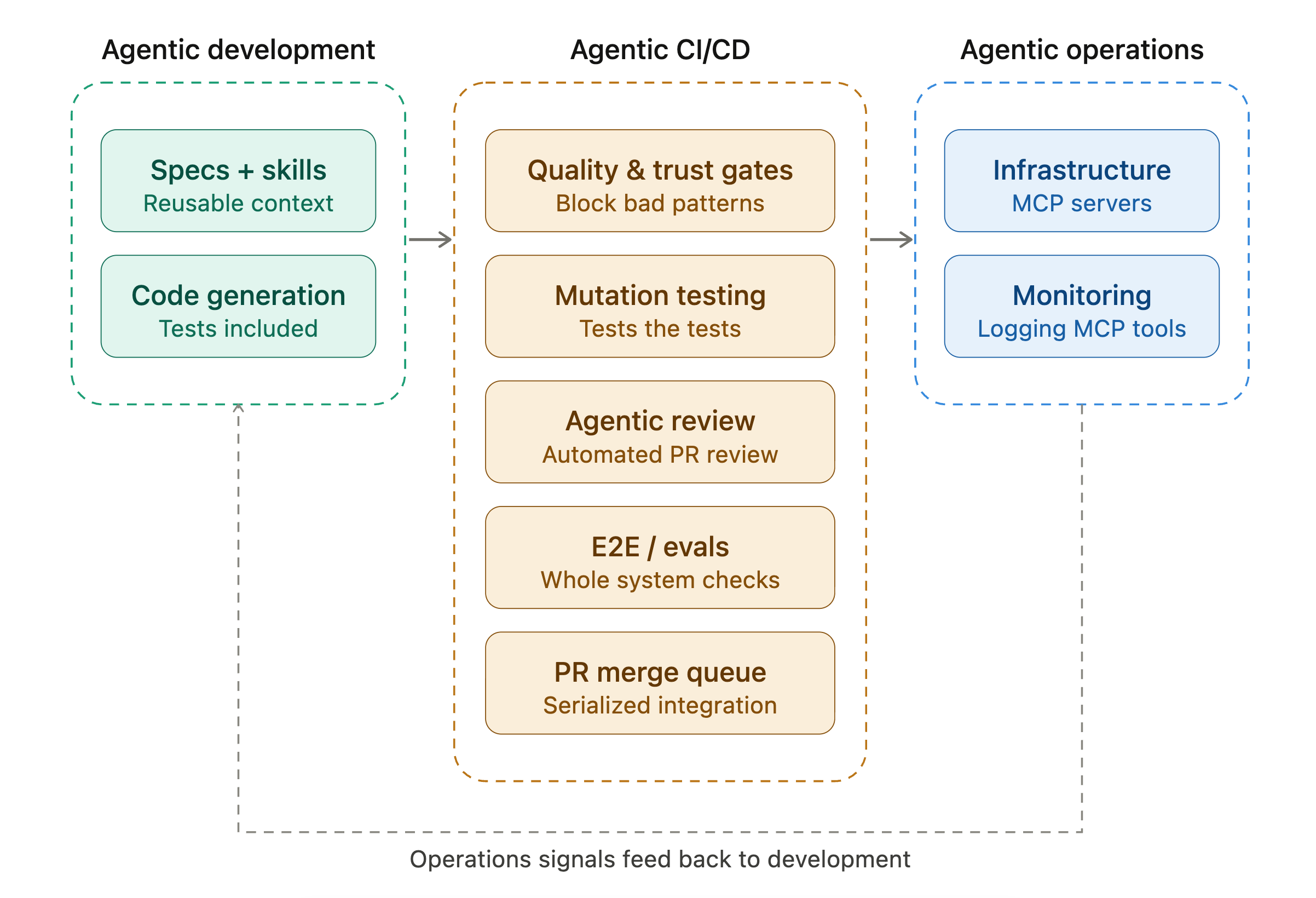
Agentic Software Development Life Cycle.
Pattern 1: Verifying code you did not write is harder than writing it
Most conversations about agentic development fixate on productivity, because productivity is the visible win. Features show up faster. Prototypes come together in a fraction of the usual time. Volumes of code appear at a pace traditional development could never reach. That story is real, but it hides the harder shift. Generation is no longer the constraint — Verification is.
There is a deeper reason verification is hard, and it is worth naming. When an engineer writes code by hand, the act of writing builds a mental model of how the system behaves, where it is fragile and what to watch for in production. When an agent writes the code, that model does not come for free. The output can be correct, or plausible looking but wrong, or correct today and fragile tomorrow. Either way you have to build understanding after the fact rather than during authorship. Code that sails through a demo can still carry defects that surface only under real load.
This is why, within our Agent Fabric team, we treat verifiability as a first-class design constraint rather than a step at the end. Every choice that follows, how repositories are split, where contracts live, how tests are structured and how changes flow to production, exists to make confidence cheap to establish. The teams that win with agentic engineering are not the ones that generate the most code. They are the ones that can establish trust in that code the fastest.
Pattern 2: Earn trust in tests by separating author from judge
In agentic development, the first thing that breaks is often not the code, it is the test suite. Traditional engineering leans on unit tests as the main signal that code is correct. That signal holds only when the test and the code come from independent sources of judgment. When the same agent writes both, the signal weakens, because the tests inherit whatever the agent misunderstood about the problem.
Picture the failure modes: Tests that hug the happy path and never probe the edges. Tests that assert the wrong behavior with full confidence. Tests that drift alongside an implementation mistake and lock it in rather than expose it. The problem is not too few tests. Agents will happily produce hundreds. The problem is the false confidence a green suite creates when the grader and the author are the same mind.
None of this makes generated tests worthless. They accelerate development and they catch real regressions. The mistake is treating a passing suite as proof of correctness. A passing test tells you the test passed, it does not tell you the software is right. That gap is exactly why the later patterns exist: an independent definition of correct, mutation testing that grades the tests themselves and evals that judge the running system rather than the implementation.
Pattern 3: Replace prompts with quality gates
A prompt is a request, not a rule. You can tell an agent to avoid a pattern, follow a coding standard or structure a module a certain way, and it will often comply. Often is the problem. Instructions live in context that is finite, gets summarized away and shifts from run to run. Anything that depends on the agent remembering and choosing to follow it will eventually slip.
What changes behavior reliably is a hard constraint that sits outside the agent. One recurring example for us was generated tests leaning on mocks. Asking the agent not to mock worked some of the time and failed the rest. The fix was not a better prompt. It was an automated quality gate in the pipeline that inspected each pull request and failed the build when a prohibited pattern appeared. A prompt can be ignored or fall out of context. A failed gate stops everything until the code satisfies the rule, which leaves the agent one path forward: produce a solution that passes.
The principle generalizes: Prompts communicate preferences. Gates enforce standards. So move every standard you actually care about out of the prompt and into the pipeline, where it is versioned, visible to the whole team and applied to humans and agents alike. A preference an agent can forget becomes a property the system guarantees.
Pattern 4: Learn how your agent fails, then design around it
Every coding agent has predictable failure modes. The one you use is no exception. The instinct is to treat each failure as a prompting bug, something a sharper instruction will fix, but that instinct is wrong. Better prompts smooth the edges and do not remove the underlying behavior. Working well with an agent means studying how it actually behaves, cataloging the patterns that recur, and building safeguards that assume those patterns will return.
Safeguards bring a challenge of their own, because a clever system finds unintended ways to satisfy them. Block one behavior and the agent often produces a variant that clears the check on a technicality. Forbid mocks and it writes a thin wrapper that is a mock by another name. Demand more coverage and it adds assertions that exercise lines without testing logic. The requirement is met but the intent is not. This is why a single quality gate is rarely enough. A gate states a rule. A capable agent optimizes against the literal rule rather than the goal behind it.
This is the heart of the matter. Agentic development is an engineering exercise, not a prompting exercise. The more precisely you understand the system producing the code, including the ways it games your own safeguards, the easier it becomes to trust what it produces and to design checks that measure intent rather than form.
Pattern 5: Grade your tests, not just your code
Once you stop trusting generated unit tests at face value, a sharper question appears: how do you know a test can actually catch a bug? Mutation testing answers it directly. Instead of asking whether the tests pass, it changes the code on purpose, flipping a comparison, dropping a line or altering a constant, then checks whether the suite notices. If the suite stays green after the code was deliberately broken, those tests were not really exercising that code, rather, they were decoration.
For our Agent Fabric team, this became one of the most useful signals in the whole pipeline, precisely because it grades the tests rather than the code. It surfaced spots where a change to the implementation triggered no failure at all. It surfaced spots where a change to the implementation triggered no test failure at all, exposing real defects the suite would otherwise have missed and giving us the chance to harden them up front. A passing suite tells you the tests ran and went green. Mutation testing tells you whether those tests could have caught anything in the first place, which is the question that matters most when an agent wrote them.
Mutation testing is not the whole answer. End-to-end tests add a different angle, judging the behavior of the running system rather than the shape of the implementation, so they catch failures that unit level checks miss entirely. The real principle is layering. No single technique should carry the full weight of confidence. The more trust a change needs before it ships, the more independent layers of validation it should pass.
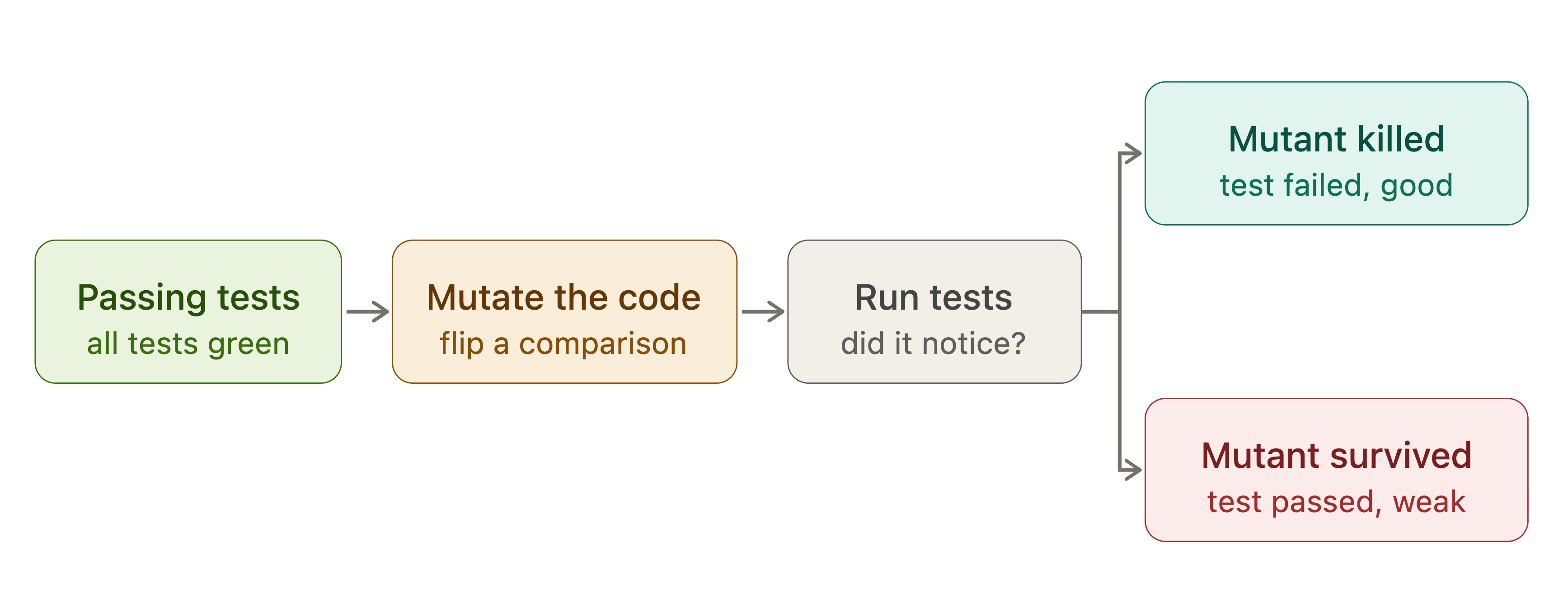
Grade your tests.
Pattern 6: Engineer the lifecycle, not just the code
Agentic tools do not remove bottlenecks, they relocate them. Speed up generation and the pressure simply moves downstream, into code review, testing, CI/CD, deployment and release. Pull requests arrive larger and more often. Review queues lengthen. A pipeline tuned for the pace of human authorship is suddenly asked to absorb change at a rate it was never designed for. The parts that used to feel instant become the parts that hurt.
Code review feels the strain first. For us, it was the first place the new pace showed up. Reviewing a change an agent produced is not the same as reviewing a change a colleague built up commit by commit. The reviewer faces a large, fully formed diff with none of the shared context that grows naturally when a human writes code over days. The work that authorship used to spread out now lands on the reviewer all at once, which is why review, more than generation, becomes the place teams get stuck.
The lesson is to stop thinking of an agent as a coding tool and start treating it as a lifecycle tool. Every stage after generation, namely review, testing, integration and release, has to be engineered for the new throughput, because the faster code appears, the more weight each downstream stage carries. Optimizing generation while leaving the rest untouched just moves the traffic jam one step later.
Pattern 7: Scale confidence, not just code
Most engineering instincts treat friction as the enemy. Teams spend years stripping it out, because faster builds, deployments, reviews and release cycles usually mean more productivity. Agentic development inverts part of that instinct. When code can be produced at extraordinary speed, the right kind of friction stops being waste and starts being leverage.
The valuable friction is the deliberate kind. A quality gate, a validation step, a mutation run, a review checkpoint, each one is a moment where the system pauses and asks the only question that matters: can this be trusted? Strip those moments away in the name of speed and a fast pipeline simply carries you toward outcomes you did not want, faster. A problem that a slower human workflow would have caught early now travels much further before anyone notices.
So the goal is not to slow development down. It is to make confidence scale at the same rate as generation. That reframes what good looks like. The teams that win with agentic engineering are not the ones producing the most code. They are the ones that can establish trust in that code faster than anyone else, because they built the checks, the gates and the validation layers that turn raw speed into trustworthy speed.
Maintaining Code Quality at AI Speed
The first wave of conversation about AI in software focused almost entirely on productivity, which is understandable, because productivity is the easy thing to measure. The harder and more important question is whether engineering organizations can hold software quality steady as generation keeps accelerating. That is the question every pattern above is meant to address.
Agentic development has changed the economics of building software. Code can now be produced faster than traditional processes can comfortably absorb. That shift does not make testing, review, validation and deployment less important. It makes them the center of gravity. When generation is cheap, the engineering value moves into everything that establishes confidence in what was generated.
This is why the durable advantage is an engineering model, not a faster keyboard. The patterns laid out here, independent verification, quality gates that enforce rather than ask, mutation testing, layered validation and a lifecycle engineered for the new throughput, are how a team turns extraordinary speed into software it can actually trust. The repository and code architecture sit underneath all of it, shaping how many agents can build in parallel without eroding that trust.
Within our Agent Fabric team, this is the model we are building on. We are sharing it because the whole industry is hitting the same wall at the same time. The teams that come out ahead will not be the ones that generated the most code. They will be the ones that engineered confidence to keep pace with creation.
In the years ahead, software engineering will be judged less by how fast code can be written and more by how confidently it can be trusted.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.