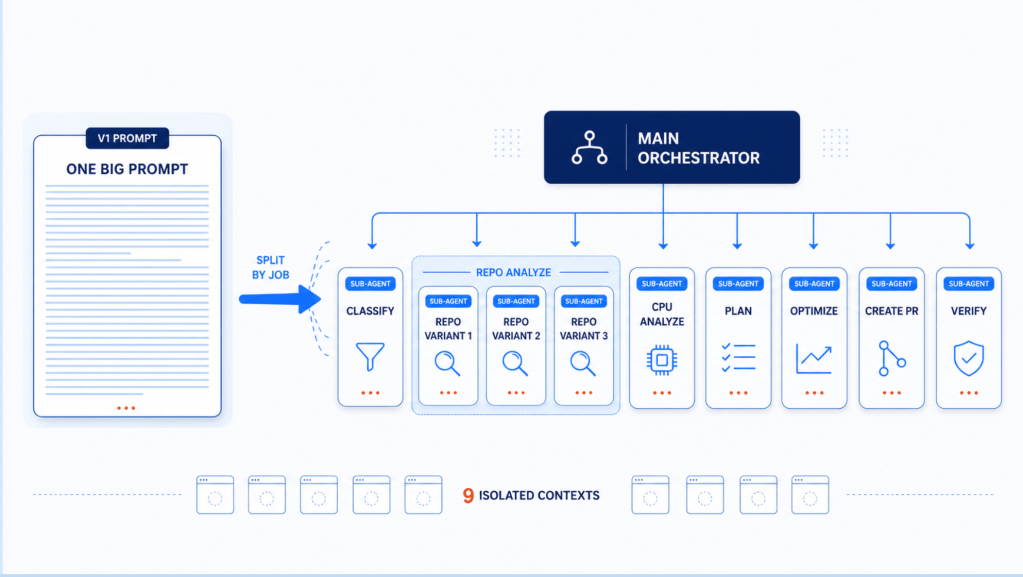
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Melissa Cazalet, Senior Vice President of Software Engineering at MuleSoft, whose teams are shaping how MuleSoft delivers software safely in the agentic era. One of the initiatives leading that charge is Golden Gate, an AI-powered PR-time governance system designed to hold every code change, regardless of who or what authored it, to Salesforce’s bar for security, compliance, and operational trust at the merge boundary, surfacing risks to developers before a change reaches production. Golden Gate operates uniformly across every enrolled MuleSoft repository, turning AI governance into a secure software development lifecycle enforcement layer embedded directly inside developer workflows.
Explore how the MuleSoft team built repeatable governance infrastructure that holds every code change to a consistent trust bar across the MuleSoft repository fleet without slowing developer velocity, and how they validated probabilistic, LLM-based enforcement logic rigorously enough to earn the right to block merges. This is a model any engineering org adopting agentic development can apply.
Why did agentic development change the code trust model at MuleSoft?
Historically, the code trust bar was enforced through manual reviews, downstream validation, and human expertise. That model worked when human-paced review cycles matched human-paced code production. Agentic development changes the economics. Code now reaches the merge boundary at a velocity and volume those workflows were never designed to absorb. The same acceleration that shortens delivery cycles also narrows the window in which trust issues can be caught. The stakes make that compression unforgiving: customers run production workloads directly on MuleSoft infrastructure, so any change that ships can flow into customer runtime environments and downstream Salesforce systems across the software supply chain. Every change has to clear the same trust threshold, every time, regardless of how it was authored.
The defining problem is the combination of volume and velocity at once — and the existing controls were built for a different cadence. Design reviews validate architecture, but they cannot reliably catch line-level risks: insecure dependencies, exposed secrets, vulnerable libraries, injection vulnerabilities, weak cryptography, or compliance violations embedded inside a pull request. Static analysis after merge, compliance audits, bug bounty findings, and penetration testing all operate too late in the lifecycle, long after the developer has context-switched away from the change and the cost of remediation has multiplied. Risky patterns can propagate through the software supply chain faster than downstream review systems can react.
The MuleSoft and Salesforce teams’ mandate is to embrace the acceleration while raising, not relaxing, the trust bar across the repository fleet and the interconnected services running on it. That forces a move from human-driven reviews to deterministic, automated governance that runs continuously across the secure Software Development Lifecycle (SDLC), and a materially further-left shift of security and compliance enforcement into the pull request itself. The answer is not more reviewers or more reviews, rather, it is programmable governance at the merge boundary. Golden Gate is exactly that: a PR-time enforcement layer that intercepts risky patterns before they reach production. It is a reusable model for any engineering org looking to make trust enforcement keep pace with agentic development.
What did it take to scale Golden Gate across MuleSoft repositories?
The hardest part was not the AI, it was the operating model. Golden Gate had to function as organization-scale governance infrastructure that thousands of pull request workflows would touch every day, without becoming a tax on the very development lifecycle it was meant to protect. Building an AI code reviewer is a tractable problem; building one that an entire engineering org will accept as a merge gate is a different class of problem entirely.
The first hurdle was false positives. Developer trust is the real currency of any governance system, and once it is spent, no amount of technical sophistication earns it back. The team’s response was to make trust a measurable property, not a marketing claim. Every Golden Gate skill flows through a deterministic validation pipeline: schema validation, fixture testing, open-source evaluation, and large-scale backtesting against a corpus of real merged pull requests. Skills only become eligible for merge-blocking enforcement once they clear a high detection-accuracy threshold against that evidence base. Promotion is earned, not assumed.
Rollout discipline mattered just as much as detection quality. Skills enter the fleet in advisory mode first, surfacing findings and remediation guidance so developers can pressure-test the signal before any enforcement is on the line. Layered on top is operational hygiene that keeps the developer experience clean: false-positive suppression, criticality ranking, and finding caps that keep attention focused on the highest-priority risks. The combined effect is a PR-time experience that stays high-signal at fleet scale, which is the only way merge-time governance remains sustainable over time. In the 30 days prior to this post, Golden Gate’s production skills executed roughly 77,000 times over more than 14,000 pull requests, with developers rejecting under half a percent of all findings as false positives.
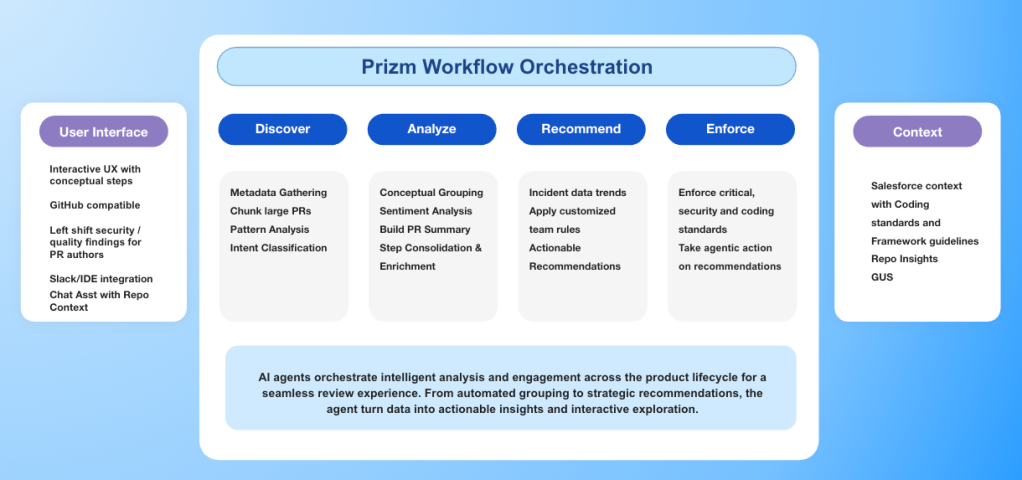
The work also had to land on a moving target. PR-time enforcement depended on Prizm, Salesforce’s internal pull-request governance platform, including its deployment infrastructure, org-scope enforcement model, and merge-blocking capabilities, all of which were maturing in parallel. The team was building AI-powered governance infrastructure on top of a foundation that was itself still being poured, a coordination problem that any org standing up agentic governance from scratch should expect, plan for, and treat as a first-class part of the architecture.
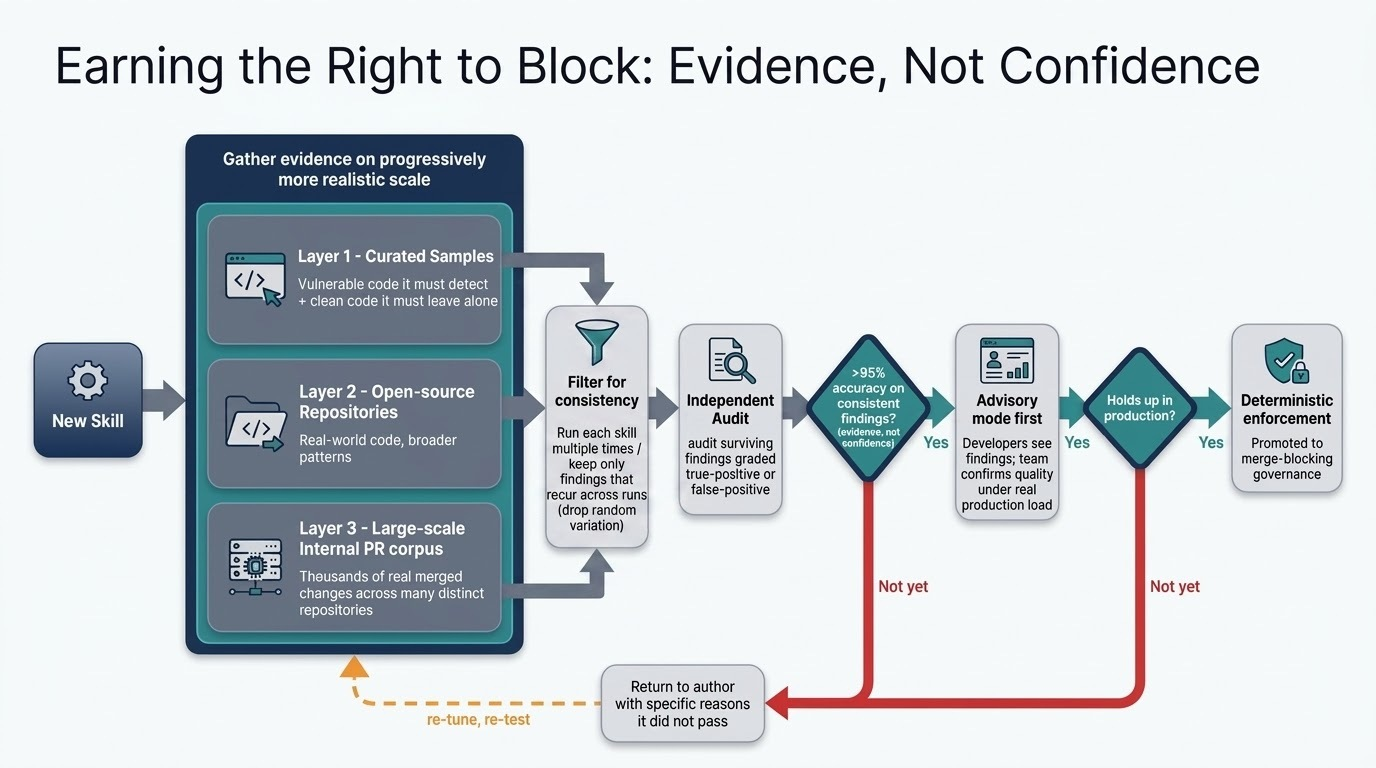
How does Golden Gate turn probabilistic AI output into deterministic enforcement decisions?
The core tension is structural. LLMs are probabilistic by design, while trust governance has to be deterministic by definition. A merge gate cannot operate on signal that drifts between runs, contradicts itself across evaluations, or surfaces noise at a rate developers will eventually start ignoring. Closing that gap is the central engineering problem of any LLM-driven enforcement system.
Golden Gate closes it by treating determinism as a property the system produces, not one the model provides. During qualification, every skill is executed at least three times against the same curated corpus of real merged pull requests, and only findings that reproduce across a strict majority of runs are accepted as evidence. That consensus filter strips stochastic variation out of the pipeline before any result is even considered for promotion, converting probabilistic model output into stable, evidence-grade signal.
Layered on top is a validation architecture that exercises each skill against a deliberately diverse evidence base: curated vulnerable code samples, clean-code baselines, open-source repositories, and large-scale internal pull request corpora. Findings flow through AI-assisted triage workflows and roll up into evidence models that measure promotion eligibility against predefined thresholds. Promotion decisions are mechanical, driven by data, not subjective judgment or model confidence scores.
The result is a system where the right to block merges is earned through measurable validation evidence, not asserted on the strength of model output. Engineering deterministic governance on top of non-deterministic LLMs, before turning enforcement on, is the move that makes AI-driven trust systems credible at scale, and it is the part of the Golden Gate blueprint most directly transferable to any team building agentic governance of their own.
What does it take to make merge-time AI governance feel like a collaborator, not a gate?
Any team standing up AI governance learns the same lesson early: these systems do not fail because the model is wrong; they fail because developers experience them as noisy, hostile, or impossible to escape. The safeguards Golden Gate is built on are a direct response to that failure mode, and they generalize to any org adopting agentic engineering.
The first is an escape-valve architecture. Developers and repository owners retain human override paths that let enforcement be bypassed or rolled back quickly when a skill misbehaves under production conditions. The principle is simple: no single skill should ever be capable of becoming an organization-wide deployment incident, and any team building governance infrastructure should design the rollback path before the rollout path.
The second is strict scoping. Skills run only against the file types and repository patterns where they are explicitly relevant, so the blast radius of any individual skill is bounded by construction rather than by hope. Take “enforcement-bypass”, one of the skills live in production today. It watches for changes that quietly switch off the tools meant to catch bad code, such as a TypeScript strict-mode flag turned off, a security linter rule disabled, a CI test stage set to continue-on-error, or source files quietly added to a static-analysis exclusion list. It is scoped to the configuration, CI, and source files where those weakenings actually happen, so it stays out of the way everywhere else. Pair that with a remediation-first interaction model, where every finding ships with concrete, actionable guidance rather than a vague alert, and developers experience the system as a collaborator that unblocks them, not a gate that interrupts them. In the past 30 days, enforcement-bypass ran on more than 2,200 pull requests and surfaced 369 findings, only 3 of which developers rejected as inaccurate.
The third, and most important for anyone replicating this pattern, is the discipline around promotion. False-positive fatigue is the single fastest way to lose an engineering organization, and once trust is gone the system is effectively dead regardless of its detection quality. Golden Gate refuses to promote a skill into blocking mode until the validation pipeline has produced quantified evidence that enforcement quality clears the bar, including at least five repositories tested, a sample of findings independently audited, and 95% precision on consensus-stable findings. The discipline cuts both ways: one skill, change-impact-review, scored just 45% precision across 75 reviewed pull requests (well below that bar) because it kept flagging routine maintenance and everyday bugs as system-wide risks, so we held it in draft and it never reached a developer. The principle reduces to one line worth stealing: merge-blocking governance requires evidence, not confidence. Any team building agentic governance should treat that as a non-negotiable, encode it into a promotion pipeline, and only turn enforcement on for the skills that have earned it.
How is Salesforce scaling MuleSoft’s agentic governance model across the software lifecycle?
The next phase is the one most teams investing in agentic governance will eventually reach, turning a platform that works for one organization into infrastructure that works for many. For Golden Gate, that means evolving from a MuleSoft-specific enforcement system into reusable lifecycle governance infrastructure that operates cleanly across different engineering organizations, technology stacks, and operational models inside Salesforce.
The mechanism we are building is what we call internally a Skill Factory, which is an automated governance pipeline that productizes the parts of the system that have historically required hand-holding: skill validation, evidence generation, promotion workflows, deployment automation, and cross-org portability. The point is to make governance self-service. New teams should be able to author a skill, run it through the same evidence pipeline that earned merge-blocking trust on MuleSoft, and have it promoted and deployed across their own engineering surface without rebuilding the substrate underneath. For any org adopting this pattern, the lesson is to invest in the factory, not just the skills: the multiplier on every future skill comes from the pipeline that ships it.
The second frontier is Ambient Code Hygiene, which extends governance beyond the pull request and into the technical debt already sitting inside large codebases. Pull-request enforcement only ever addresses newly introduced risk; the existing surface area, including deprecated dependencies, outdated cryptographic implementations, and drifted patterns, accumulates faster than humans can chase it. Ambient agents traverse repositories continuously, identify those patterns, and autonomously open remediation pull requests during low-activity windows, turning hygiene into a background process rather than a periodic project.
Together, these two directions describe the long-term shape of agentic governance: from PR-time enforcement to autonomous remediation, and from a single-org platform to lifecycle-wide infrastructure. The vision is governance systems that continuously enforce trust policies across the entire software development lifecycle without slowing engineering delivery, and the blueprint for any team trying to get there is the same one Golden Gate is following: build the factory, earn the trust, then expand the surface.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.