Context
Our Commerce Cloud team that is in charge of the Omnichannel Inventory service uses Redis as a remote cache to store data that lends itself for caching. The remote cache allows our multiple processes to get a synchronized and single view of the cached data. (See our previous blog post, Coordinated Rate Limiting in Microservices for an example of how we used Redis for Rate Limiting access to our system by tenants.) The usage pattern is entries that were shorter lived, high cache-hit and shared among instances. To interact with Redis, we utilized Spring Data Redis (with Lettuce), which has been helping us to share our data entries among our instances and provide a low-code solution to interact with Redis.
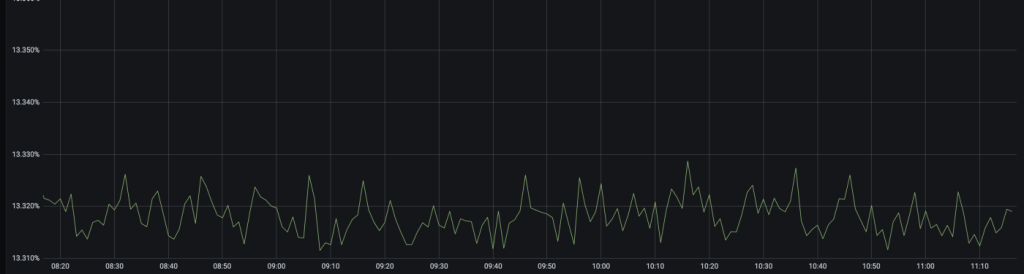
A subsequent deployment of our applications showed an oddity, where the memory consumption on Redis was continuously increasing, with no indication of reducing.
The memory growth on the Redis Server is reflected in the following graph:


The memory consumption showed an almost linear increase over time, with increased throughput on the system and no significant reclamation over time. The scenario reached such extremes that it warranted a manual flush of the Redis database as the memory increased and neared 100%. The above seemed to point toward a memory leak happening with the Redis entries.
Investigation
The first suspect was that the Redis entries were either configured without a Time to Live (TTL) or with a TTL value that was beyond the one intended. This was indicative that the Redis Repository entity class we had for Rate Limiting was devoid of any TTL configuration:
@RedisHash("rate")
public class RateRedisEntry implements Serializable {
@Id
private String tenantEndpointByBlock; // A HTTP end point
...
}
// CRUD repository.
@Repository
public interface RateRepository extends CrudRepository<RateRedisEntry, String> {}
To validate this on Data that the TTL was indeed not set, a connection was made to the Redis Server instance and the Redis command TTL <name entry key> was used to check the value for TTL on some of the entries that were listed.
TTL "rate:block_00001"
-1
As shown above, there were entries that had a TTL of -1 indicating non-expiring. While this clearly appeared a suspect for the issue at hand, and fixing it to explicitly set TTL values to practice good software hygiene seemed the direction forward, there was some skepticism that this were the real cause of the problem due to the relatively small amount of entries and memory used being reported.
With the TTL added, the entry code is show below.
@RedisHash("rate")
public class RateRedisEntry implements Serializable {
@Id
private String tenantEndpointByBlock;
@TimeToLive
private Integer expirationSeconds;
...
}
When doing this exercise, we also noticed that on the entities that was, there was an extra entry created using the hash value that we declared, and this was happening in all of our interfaces that extended from CRUDRepository.
An example was the following hash declared for rate entries.
@RedisHash("rate")
In order to check this, we used the following Redis commands:
KEYS *
1) "rate"
2) "block_00001"
As you can see, there are two entries. One is an entry with key name “rate:block_00001” and an extra entry with key “rate”. The “rate:block_00001”was expected, but the other entry was surprising to find.
Monitoring the system over time also showed that the memory associated with the “rate” key was steadily increasing.
>MEMORY USAGE "rate"
(integer) 153034
.
.
.
> MEMORY USAGE "rate"
(integer) 153876
.
.
> MEMORY USAGE "rate"
(integer) 163492
In addition the to increased memory growth, the TTL on the “rate” entry was -1 as shown by the below:
>TTL "rate"
-1
>TYPE "rate"
set
It clearly pointed to the most plausible suspect where its growth showed no sign of reducing over time.
So, what was this entry and why was it growing?
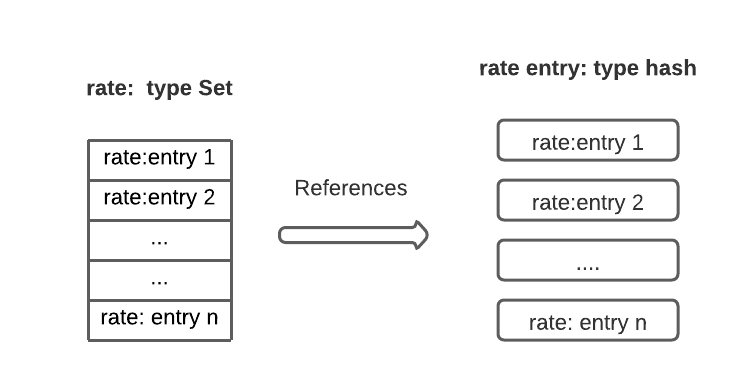
Spring Data Redis creates a SET data type in Redis for every @RedisHash. The entries of the SET act as an index for many of the Spring Data Redis operations used by the CRUD repository.
The SET entries, for example, look like the below:
>SMEMBERS "rate"
1) "block_00001"
2) "block_00002"
3) "block_00003"
...
We decided to post our situation in Stack Overflow and on Spring Data Redis’s GitHub page requesting some assistance from the community on the issue on how best to address this issue — either to prevent the growth of this SET, or how to prevent its creation, as we really did not need any other indexing feature.
While awaiting a response from the community, we discovered that enabling a property of the Spring Data Redis annotation EnableRedisRepositories will actually make Spring Data Redis listen for KEY Events and clean up the Set over time as it receives KEY expired events.
@EnableRedisRepositories(enableKeyspaceEvents
= EnableKeyspaceEvents.ON_STARTUP)
With this setting enabled, Spring Data Redis will ensure that the memory of the Set does not keep increasing and that expired entries are purged out (See this Stack Overflow Question on details).
"rate"
"rate:block_00001"
"rate:block_00001:phantom" <-- Phantom entry in addition to base
...
The Phantom Keys are created so that Spring Data Redis can propagate a RedisKeyExpiredEvent with relevant data to Spring Framework’s ApplicationEvent subscribers. The Phantom (or Shadow) entry is longer lived than the entry it is shadowing, so when the primary entry expired event is received by Spring Data Redis, it will obtain values from the Shadow entry to propagate the RedisKeyExpiredEvent, which will house a copy of the expired domain object in addition to the key.
The following code in Spring Data Redis receives the phantom entry expiration and purges the item from the index:
static class MappingExpirationListener extends KeyExpirationEventMessageListener {
private final RedisOperations<?, ?> ops;
...
@Override
public void onMessage(Message message, @Nullable byte[] pattern) {
...
RedisKeyExpiredEvent event = new RedisKeyExpiredEvent(channel, key, value);
ops.execute((RedisCallback<Void>) connection -> {
// Removes entry from the Set
connection.sRem(converter.getConversionService()
.convert(event.getKeyspace(), byte[].class), event.getId());
...
});
}
..
}
The primary concern with this approach is the additional processing overhead that Spring Data Redis incurs for having to consume the expired event stream and perform the clean up. It should also be noted that, since the Redis Pub/Sub messages are not persistent, if entries expire while the application is down, then expired events are not processed, and those entries will not get cleaned up from the SET.
Using CRUDRepository effectively means more shadow/support entries are created for each entry, causing more consumption of memory from the Redis server’s database. If one does not need the details of the expiration in the Spring Boot Application when an entry expired, you can disable the generation of the Phantom entries with the following change to the EnableRedisRespositories annotation.
@EnableRedisRepositories(.. shadowCopy = ShadowCopy.OFF)
The net effect of the above is that Spring Data Redis will no longer create the Shadow copy but will still subscribe for the Keyspace events and purge the SET of the entry. Spring Boot Application Events propagated will only contain the KEY and not the full Domain object.
With all the above discovered around performance and additional memory storage, we decided that it felt that for the use cases we were dealing with, this additional overhead added by Redis CRUDRepository and KEY Space events was not something that was appealing to us. For this reason, we decided to explore a more leaner approach.
We made a proof-of-concept application to test the differences in response time between using CrudRepository or working directly with the RedisTemplate class that exposes the Redis server operations. Through testing we observed RedisTemplate to be more favorable.


The comparison was made by executing GET operations non-stop for five minutes and taking an average of the time it took to complete the operation. What we saw is that the almost all GET operations using CRUDRepository were in the milliseconds range, while the proof-of-concept without CRUDRepository was mostly on the nano-seconds realm. Another thing we noticed was that CRUDRepository also has a tendency to have more upticks when performing the operations, increasing the latency of executing its operations.
Solution
Based on the research, we were down to the following paths forward:
- Spring Data Redis CrudRepository: Enable Redis Repository’s key space events and enable Spring Data Redis to purge the Set type of expired entries. The upside of this approach is that it is a low-code solution achieved by setting a value on an annotation, letting Spring Data Redis subscribe for KEY expired events and clean up behind the scenes. The downside is, for our case, the additional usage of memory for something we never utilize, i.e., the SET index and the processing overhead occurred by Spring Data Redis subscribing for Keyspace events and performing the cleanup.
- Custom Repository using RedisTemplate: Handle the Redis I/O Operation without using the CRUD Repository, use the RedisTemplate, and build the basic needed operations. The upside is that it results in creating only what data we need in Redis, i.e., the hash entries, and not other artifacts like the SET index. We avoid the processing overhead of Spring Data Redis subscribing and processing Keyspace events for clean up. The downside is that we stop availing the low-code magic of Spring Data Redis’s CRUD repository and the work it does behind the scenes and instead do all the work with code.
After considering all of our findings, especially the metrics around the proof-of-concept application and our system, and the needs that we have on the team, which are more about quick response times and low memory usage, the direction we adopted was not to use the CrudRepository but to use the RedisTemplate to interact with the Redis server. It presents a solution that includes far less unknown behavior, due to the code being more transparent and the functionality more straight forward.
Our code ended up looking like this:
public class RateRedisEntry implements Serializable {
private String tenantEndpointByBlock;
private Integer expirationSeconds;
...
}
@Bean
public RedisTemplate<String, RateRedisEntry> redisTemplate() {
RedisTemplate<String, RateRedisEntry> template = new RedisTemplate<>();
template.setConnectionFactory(getLettuceConnectionFactory());
return template;
}
public class RedisCachedRateRepositoryImpl implements RedisCachedRateRepository {
private final RedisTemplate<String, RateRedisEntry> redisTemplate;
public RedisCachedRateRepositoryImpl(RedisTemplate<String, RateRedisEntry> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public Optional<RateRedisEntry> find(String key, Tags tags) {
return Optional.ofNullable(this.redisTemplate.opsForValue()
.get(composeHeader(key)));
}
public void put(final @NonNull RateRedisEntry rateEntry, Tags tags) {
this.redisTemplate.opsForValue().set(composeHeader(rateEntry.getTenantEndpointByBlock()),
rateEntry, Duration.ofSeconds(rateEntry.getRedisTTLInSeconds()));
}
private String composeHeader(String key) {
return String.format("rate:%s", key);
}
}
By using it this way, we worked directly with the entries, so there are no risks of unwanted indexes or structures being stored.
Once our solution got deployed, our memory usage totally dropped and remained stable, with any peaks going down after the TTL of the entries reached 0.
Another benefit that we saw of using the RedisTemplate direct approach was an improvement in our response times of the operations we were performing, as shown on the comparison metrics above from running the GET operation for some time on our proof-of-concept and our system. Before the change, we saw values that averaged in the milliseconds; after deploying the change, we started seeing that most operations were being completed in nanoseconds.
Conclusion
The magic of Spring Data Redis Crud Operations is achieved by the creation of additional data structures like the SET for Indexes. These additional data structures are not cleaned up when items expire without enabling Spring Data Redis to listen for KEY space events. For caching patterns where entries are very long-lived or where the set of entries is tractable and finite, Spring Data Redis with CrudRepositories provides a low-code solution for CRUD operations for Redis.
However, for caching patterns where the data is cached and shared by multiple processes and where the entries have a smaller window where they can be cached, avoiding listening for KEY events and using the RedisTemplate to perform Redis operations for the CRUD operations needed seems optimal.
Share your thoughts in the comments below; we’d love to hear of your experiences with Spring Data Redis or Redis in general.
Appreciation Note: Thanks to Sanjay Acharya and Balachandar Mariappan for all the help given with the reviewing and refining. You guys are awesome… 🙂