In our “Engineering Energizers” Q&A series, we explore the inspiring journeys of engineering leaders who have significantly advanced their fields. Today, we meet Soumya KV, who spearheads the development of the Data Cloud’s internal apps layer at Salesforce. Her India-based team specializes in advanced data segmentation and activation, enabling tailored marketing strategies and enhanced decision-making for Salesforce customers.
Join Soumya and her team as they tackle significant scalability challenges to unlock deeper insights for Salesforce customers.
What is your team’s mission?
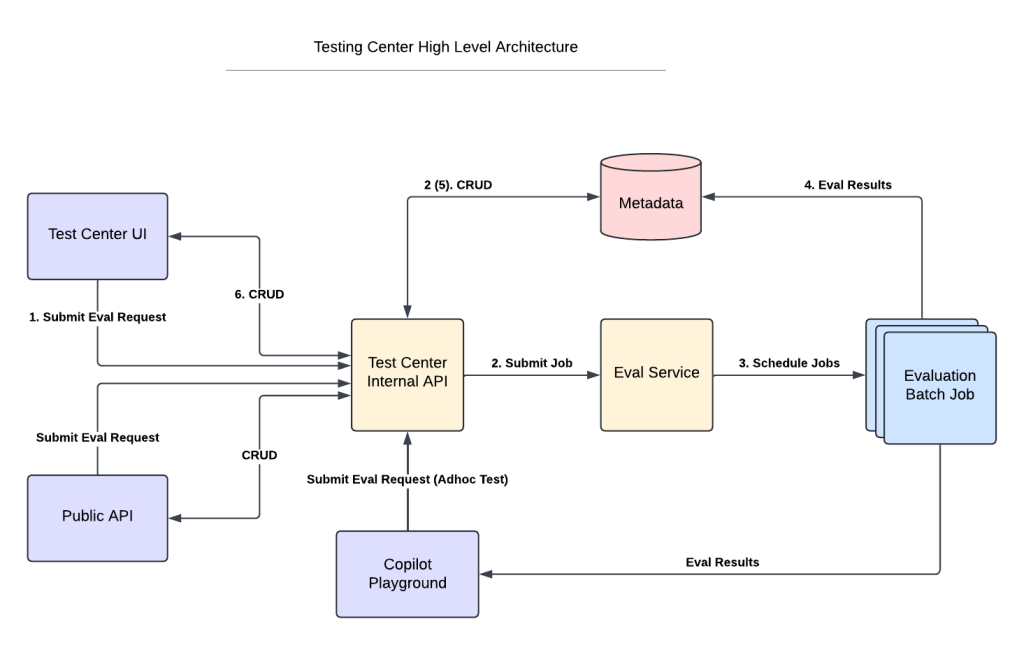
Our mission is to design, develop, test, and continuously improve Data Cloud internal applications that optimize customer targeting and engagement through segmentation and activation.
Segmentation divides customer data into specific groups based on criteria like age, location, and interests. This helps companies target their marketing efforts, increasing conversion rates or generate better business insights. For instance, a sports shoe company might target individuals between the ages of 20 and 35 who have a passion for sports. By utilizing the segmented data, the company can tailor marketing campaigns to resonate with this particular audience, potentially leading to higher engagement and conversion rates.
Activation then enriches the segmented data and sends it to the appropriate destination within and outside of Salesforce. This may include Marketing Cloud for email and SMS campaigns and Commerce Cloud targeting commerce use cases and activating directly to a customer and the ecosystem partner target location.
Our team’s work is crucial because, without segmentation and activation, the data collected in the Data Cloud would remain untapped and unusable for customers. Ultimately, we enable customers to make informed decisions, target specific audiences, and derive business value from their data.
The team is dedicated to developing latest solutions like segmentation on BYOL, real-time segmentation computation while continuously refining segmentation capabilities, scalability, and usability. On the activation front, they are enhancing features for ecosystem activation, facilitating ISV driven integrations with the partners. Additionally, the team prioritizes the development of an egress platform that provides customers with flexibility to configure and utilize egressed data across various destinations such as GCS, Azure, and SFTP. This includes support for diverse file types, sizes, encryption methods, and compression techniques.
We also take ownership of the service, maintaining the production systems and ensuring their health and stability. This involves monitoring, supporting, and meeting the availability, reliability, performance and the data security requirements of the systems.
Soumya describes the culture of her Data Cloud apps engineering team.
What challenges does your team face while working on Data Cloud’s internal apps layer?
Our greatest challenge is managing the scale of our operations. We handle an enormous volume of data, serving thousands of tenants and processing approximately a quadrillion records each month. Daily, we process trillions of records and oversee thousands of segmentation and activation jobs. Compared to last year, we have experienced over 100% growth in scale.

To counter this challenge, we employ many strategies:
- Continuous Monitoring and Analysis: The team continuously monitors the production system, conducting performance assessment, analyzing system behavior, latency, memory utilization, CPU, and cost. They closely monitor scale, usability patterns, and resource usage to assess patterns and optimize for performance.
- Optimization and Fine-tuning: The team focuses on optimizing segmentation and activation jobs, database operations, and platform architecture to fine-tune scalability, performance and handling larger datasets efficiently. They continuously evaluate and refine their processes to improve overall system stability and performance.
- Exploration of Optimization Techniques: Techniques like data batching and optimized scheduling are explored to group related jobs together and reduce processing time.
- Adoption of New Technologies: The team stays updated on the latest trends and use technologies as applicable. This includes leveraging options like AWS EMR on EKS to enhance scalability and Spark DistCp for faster parallel data transfer capabilities.
- Implementation of Guardrails: The team implements guardrails to ensure proper usage of the capabilities and prevent misuse. This includes setting limits, providing guidelines for optimal use, offering self-help tools and educating customers.
Soumya describes a typical day for her as an engineering leader.
Which technology does your team rely on the most to manage the scaling challenge?
Apache Spark is a crucial technology for processing the vast amount of data we handle daily. With trillions of records to process on a daily basis, Spark’s distributed processing capabilities empower us to distribute workloads across a cluster of machines, enabling parallel execution and scalability. This means we can efficiently process large datasets, running complex join and query operations in a efficient and timely manner.
Spark excels at handling complex computations and join operations making it ideal for processing intricate queries to extract specific audiences basis the filter criteria for a given segment. Spark jobs execute these queries on distributed datasets, leveraging parallel processing to ensure fast processing despite massive data volumes.
Use of Spark in segmentation processing.
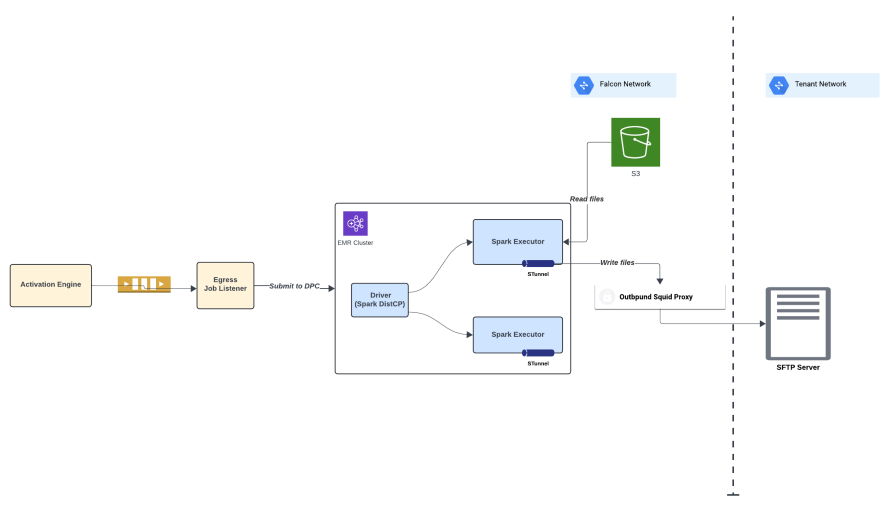
Spark is essential in the activation scenario as it allows us to enrich segmented data by adding necessary attributes through joins with other tables for improved customer engagement. Spark is efficiently applied for consent/opt out filtering requirements. Spark DistCp is used for distributed copy enabling large dataset transfer at low latencies. And also used to encrypt large data payload before egress for data security. This ensures that the activated data is comprehensive and customized to meet our clients’ specific needs.
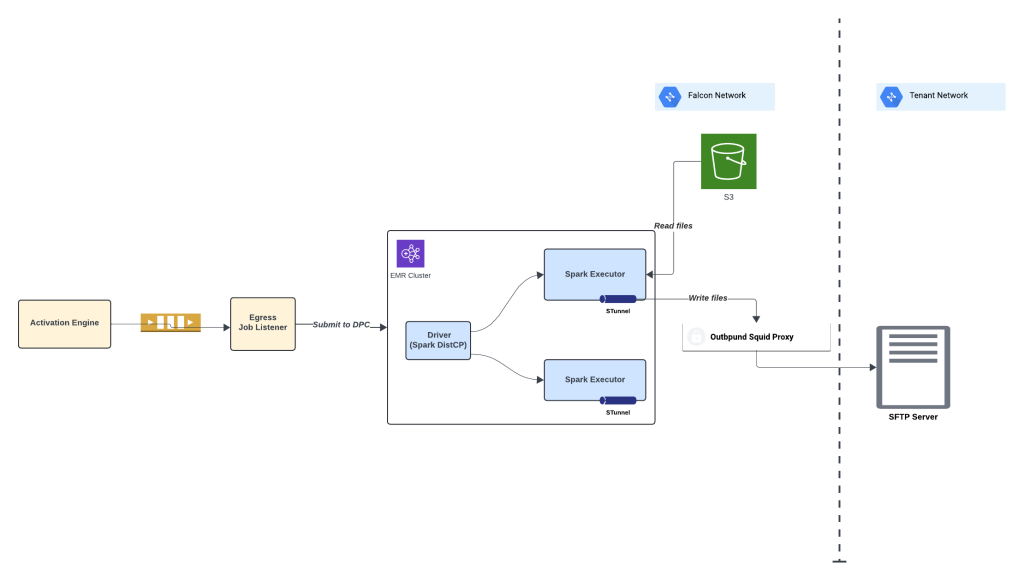
Use of Spark distcp in activation egress step.
Under the hood, Spark’s core computational engine manages various aspects of job execution. It handles job scheduling across the cluster, memory management and fault recovery, ensuring efficient utilization of resources and maintaining the stability of the processing environment. This robust engine allows us to run complex computations on large datasets with enhanced performance.
Can you provide insights into your team’s testing and quality assurance processes for ensuring the reliability and stability of the Data Cloud apps layer?
Our team follows a comprehensive testing and quality assurance process that contains multiple layers:
- Unit Testing: Developers perform thorough unit testing on the code they write, ensuring sufficient coverage and effectiveness.
- Integration Testing: We test the seamless functionality between modules, including UI integration, database actions, and integration with upstream/downstream systems.
- Functionality Testing: We write comprehensive test cases covering all requirements, review them with peers and senior members, and validate functionality through various scenarios, including negative and happy path testing.
- Automation: We automate UI and backend testing, using varied inputs to identify issues or bugs. This includes automating backend functional integration tests to safeguard existing functionality during future enhancements.
- Performance Testing: We conduct performance testing to evaluate scalability and performance. This includes testing with large data sets, running hundreds of parallel segment/activation jobs to evaluate scalability and performance. We benchmark system performance to determine achievable goals and SLAs.
Soumya shares why engineers should join Salesforce.
How does customer feedback shape your work on the Data Cloud apps layer?
As a customer-centric organization, we actively seek feedback from customers and stakeholders to guide the direction of our team’s work. We collect insights through various channels, such as customer interactions and customer support team engagements. These feedback channels allow us to understand customer needs, usability preferences, and opportunities for enhancements/improvement.
One recent example of customer feedback that influenced our work was from a metrics-driven organization. They wanted to measure processing time for each step in our solution, including segmentation, activation, and data delivery, to optimize their processes. In response, we are developing a traceability metrics dashboard that provides insights into our processing stages.
In addition to metrics, we also receive feedback on latency requirements, usability enhancements, support for varied connector frameworks, intelligent and optimal segment creation capabilities, and generating data output payloads that align with their system’s processing capabilities. We also receive inputs on enhanced data security, encryption, and data masking capabilities.
Learn More
- Hungry for more Data Cloud stories? Read this blog to learn how India’s Data Cloud big data processing compute layer team supports millions of Data Cloud-related tasks per month.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.