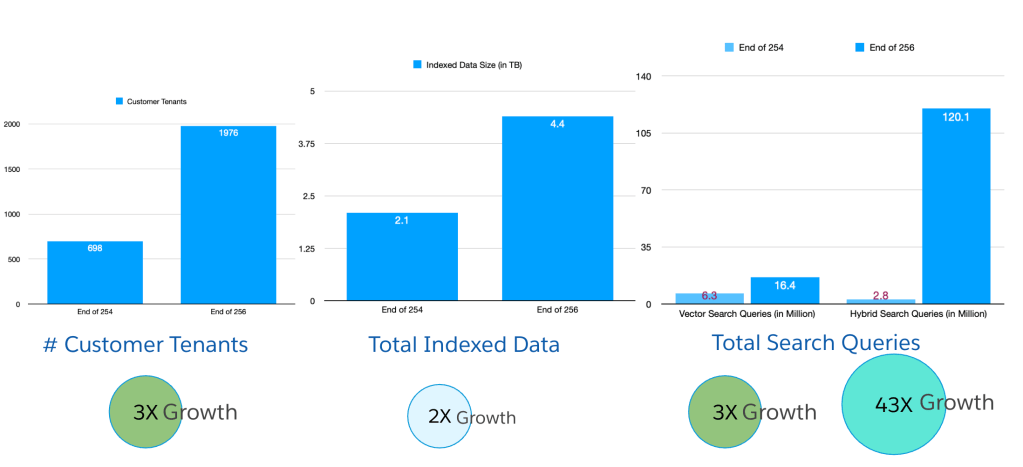
In our “Engineering Energizers” Q&A series, we shine a spotlight on the brilliant engineers fueling innovation at Salesforce. Today, we feature Sreeram Garlapati, a Software Engineering Architect who spearheaded the architectural transformation of Data Cloud’s Lakehouse. This platform powers everything from Customer 360 profiles to cutting-edge AI systems.
Learn how Sreeram’s team tackled legacy architectural constraints, massive metadata scaling issues, and the demands of real-time AI, ultimately reengineering the Lakehouse to support 4 million Iceberg tables, 50 petabytes of data, and advanced use cases like Agentforce.
What is the Salesforce Data Cloud Lakehouse, and why is an open data architecture essential for scalable enterprise AI?
The Lakehouse is Salesforce’s foundational data platform, seamlessly blending the scalability of a data lake with the structured capabilities of a data warehouse. This innovative platform supports diverse analytical workloads across the Data Cloud, driving everything from marketing insights to advanced AI agents.
One of the key advantages of the Lakehouse is its open, multi-engine architecture. This design allows Salesforce to leverage different processing engines, such as Spark, Hyper and Trino, while storing data in a common format, Apache Iceberg. This decoupling provides the flexibility to scale and innovate, using the right engine for the right workload. Ultimately, its openness protects Salesforce customers from vendor lock-in.
The Lakehouse unifies vast volumes of customer data, resolves identities, and makes data queryable in real-time. This real-time capability is crucial for enabling agentic AI systems like Agentforce to deliver contextually relevant responses. With over 4 million Iceberg tables and counting, the Lakehouse stands at the core of how Salesforce operationalizes data at scale, ensuring that businesses can harness the full potential of their data.
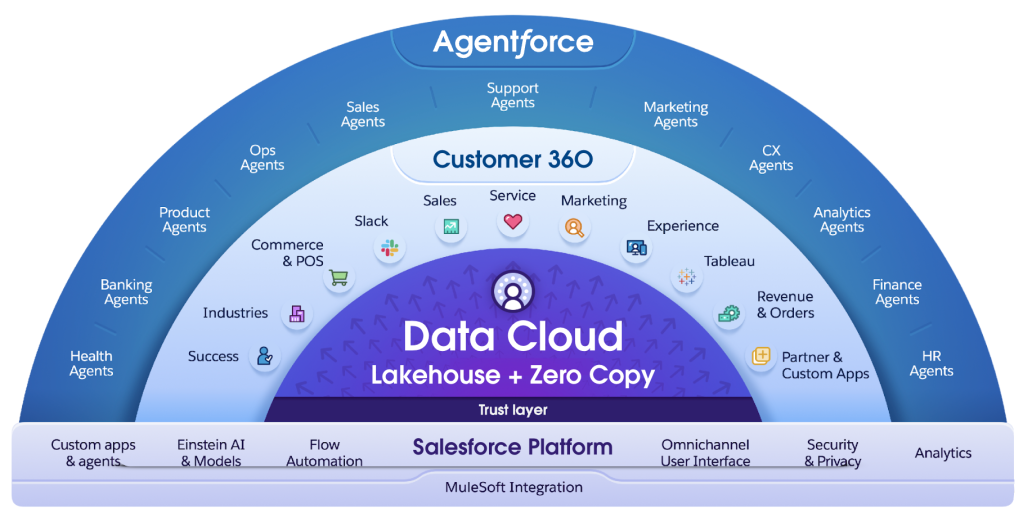
Open Lakehouse powers real-time, AI-ready, multi-engine Data Cloud.
What architectural limitations led to reengineering the Salesforce Lakehouse — and how did they influence the platform’s evolution?
Early versions of Data Cloud relied on a Hive/Metastore-based Data Lake and lacked several critical functions like schema enforcement, partition evolution, ACID semantics, and ability to revert changes, which created significant challenges for consistency, scalability, and governance. As the volume of customer data and the number of tables grew exponentially, the existing architecture struggled to keep pace. The tipping point arrived when operational issues, such as broken schema assumptions and high-cost scans, began to affect downstream services.
At 10X scale: redesign. At 100X scale: rearchitect! This critical juncture necessitated a complete rearchitecture centered around Apache Iceberg. Iceberg brought several key features to the table, including schema evolution, hidden partitioning, ACID guarantees, and time travel — essential elements for enterprise-grade reliability. The migration to Iceberg was more than just a format change; it was a fundamental rethinking of the platform. This shift enabled massive horizontal scalability and paved the way for innovations such as incremental pipelines, real-time processing, zero-copy data architectures, and enhanced observability. This moment of architectural transformation clarified the path forward, ensuring the platform could support emerging AI workloads.
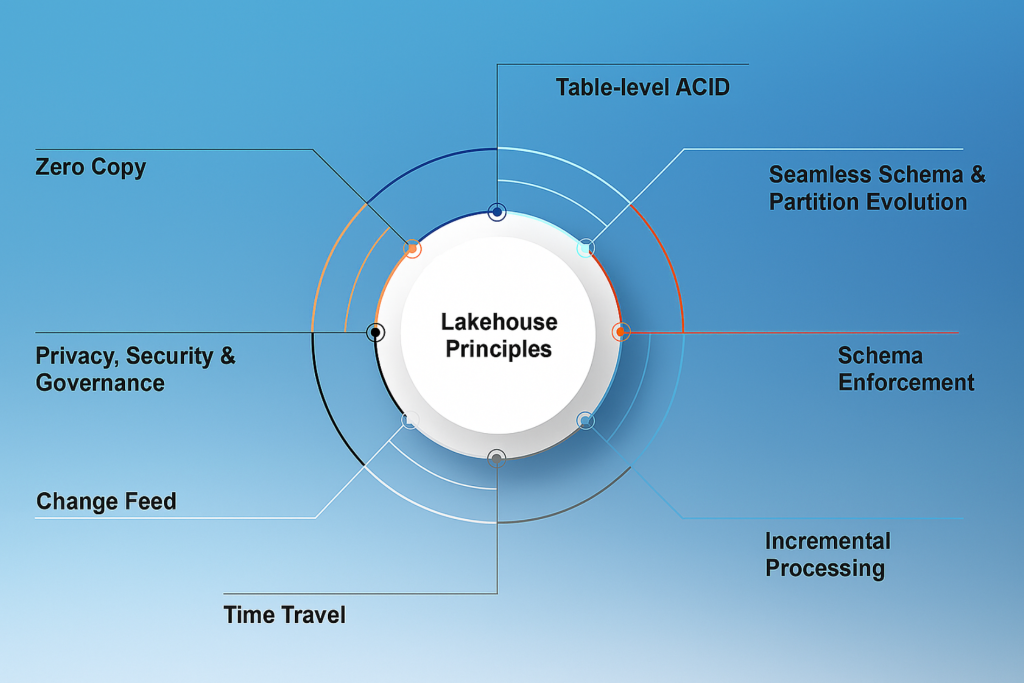
Data Cloud lakehouse – first principles.
How did Salesforce scale the Lakehouse to 4 million tables and 50PB of data—and what engineering challenges did that involve?
Scaling the Lakehouse to support 4 million Iceberg tables and 50 petabytes of data involved significant challenges, across the stack. Here’s how we addressed them:
- Object Storage Layer: We analyzed Iceberg table write patterns and controlled the object placement to ensure scalability and tenant isolation. We adopted a “Scatter at the Top, Gather at the Bottom” file path prefixing strategy with AWS S3, using Iceberg’s
LocationProviderabstraction. - Metadata Caching: Direct metadata queries became unsustainable with millions of objects. We developed a performant Lakehouse catalog and a shared Iceberg metadata cache accessible to all microservices, tapping into “follow the user activity” caching strategy to achieve a ~90% cache hit rate.
- Compute Architecture: We shifted away from a schedule-based and full data reprocessing to an event-driven and change based processing architecture across Data Cloud to reduce unnecessary processing and improve responsiveness.
- Storage Optimization Primitives: Growing data volumes led to complex query patterns that overwhelmed our engines. We continuously innovated, adding intelligent data-layer optimizations like NDV (Number of Distinct Values) sketches to accelerate query planning and execution.
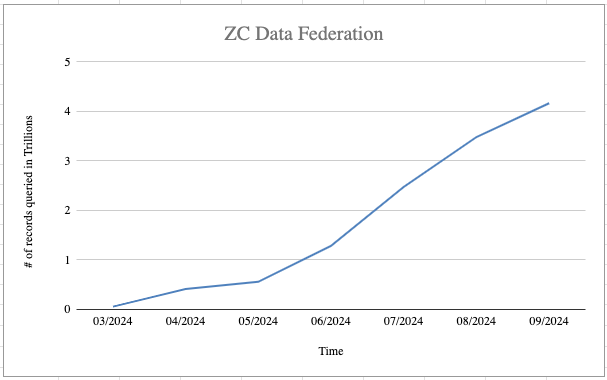
Every layer — storage, metadata, compute, and access — had to be rethought and reengineered to meet the demands of this massive scale. Fast forward to now — our customers ingested 22 Trillion records into this Active Lakehouse in the last quarter.
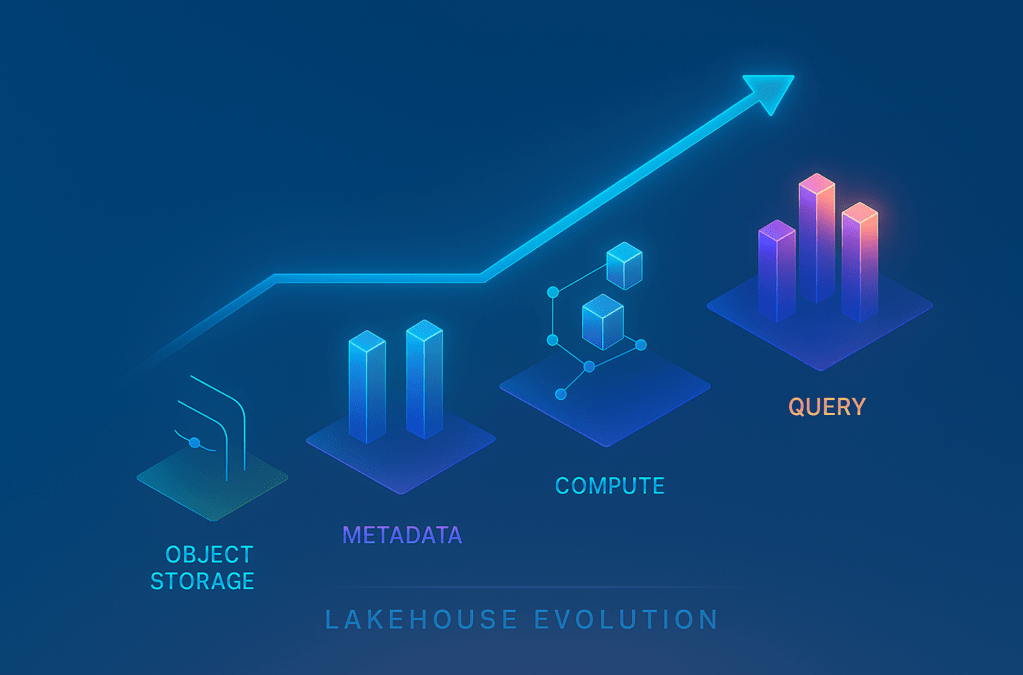
Evolving Lakehouse for massive scale.
How did Salesforce replace scheduled optimization with event-driven architecture in the Lakehouse?
At smaller scales, scheduled jobs were used to optimize Iceberg tables that suffered from write fragmentation, particularly in streaming use cases. However, this approach did not scale well. As the number of tables grew to millions, scanning each one on a fixed cadence to detect changes became prohibitively expensive. Most tables did not require frequent updates, and those that did often needed different optimization frequencies.
The breakthrough came with the development of a reactive system called the Storage Optimizer. This storage native change event (SNCE) system listens to Iceberg table changes and triggers optimization only when necessary.
This pattern proved so successful that it was generalized across all of Data Cloud’s pipelines. SNCE allowed downstream data pipelines like calculated insights, identity resolution and segmentation to subscribe and act only when data changed.
Eventually, SNCE in combination with Change Data Capture (CDC) evolved Data Cloud into a truly incremental data platform. This capability enables customers to ingest and process only the data that has changed, which is crucial when working with terabyte-sized tables. It also gave rise to incremental workflows, such as Streaming Transforms and Incremental Identity Resolution, further enhancing the platform’s efficiency and responsiveness.
How did Salesforce architect real-time change data capture and incremental AI workflows in the Lakehouse?
The Lakehouse now supports native change data capture, which means downstream services no longer need to poll or reprocess entire datasets. Instead, SNCE events notify subscribers when specific tables have been updated. This allows systems like Identity Resolution to recompute only on new or modified data. Ultimately, the ability to react and operate only on changed data, as opposed to scheduled data processing pipelines operating on the entire data, is significant in terms of cost savings and end to end data latency for Salesforce customers.
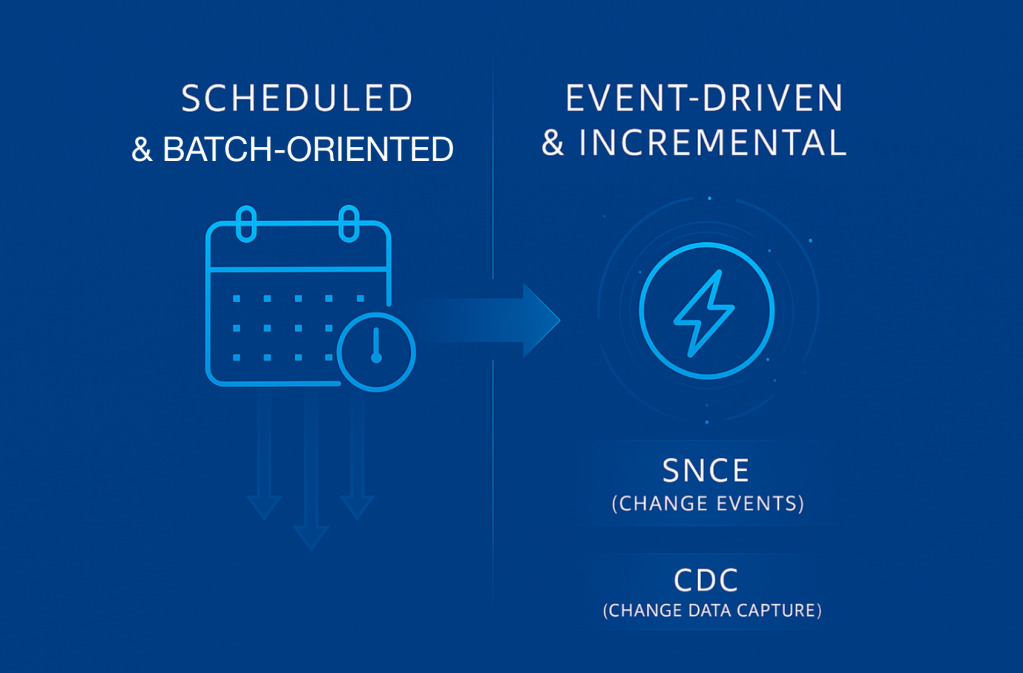
Evolution from schedule-based to active Lakehouse.
From an architectural standpoint, this required standardizing on the change event format, building a high-throughput message delivery system, and adding observability layers to track data lineage and job status. These architectural investments that we made years ago kept us looped into the advent of new AI workflows, such as real-time predictions, prompt grounding, and agentic decisioning, without straining the infrastructure. As a result, customers now enjoy faster insights, and internal systems handle load more predictably. By natively supporting incrementalism, the Lakehouse has not only improved performance but also saved costs.
How is Salesforce adapting the Lakehouse for agentic AI and AI-ready data at enterprise scale?
The emergence of agentic AI brought about a significant shift: AI systems require trusted, unified, and context-rich data. However, in most enterprises, data is scattered across data lakes, warehouses, SaaS applications, and operational systems. The initial challenge was to harmonize this data into a single, reliable model. This helps govern the access by understanding who/what the data concerns. Data Cloud addresses this by creating unified profiles and a comprehensive 360° view of the customer.
Diving deeper, governance really was a challenge as AI agents cannot have unrestricted access to sensitive data. This led to substantial investments in attribute-based access control and dynamic data masking. These governance controls added many constraints to query execution, introducing new performance bottlenecks in terms of throughput and latency. Although governance operates at a higher layer (the policy enforcement layer), it introduces complex filters and joins to the underlying query — especially when enforcing fine-grained entitlements. These push query optimizers harder, making accurate cardinality estimation essential. To handle this, we developed a method to incrementally compute and store NDVs (number of distinct values) during table writes. These NDVs directly improve query performance by enabling smarter join ordering, cardinality estimation, and aggregation planning, ensuring performance doesn’t degrade even under strict governance.
All of these advancements make the Data Cloud platform AI-ready at a massive scale and position it as the trusted backbone for Salesforce’s next-generation AI systems.
What new architecture demands has generative AI placed on Salesforce’s Lakehouse—and how is it evolving to meet them?
Generative AI significantly increases the variety, volume and velocity of data that needs to be processed. Every AI event, from prompts and responses to interactions and summaries, generates metadata that must be captured, stored, and queried. To handle this, the Lakehouse had to evolve in several key ways.
One major architectural change was supporting all the primitives required to store, process, and query unstructured data. We used Apache Iceberg table to catalog all of the unstructured data. Additionally, we stored our vector embeddings computed from that unstructured data back in to the Lakehouse. This allowed us to seamlessly issue semantic queries involving both structured and unstructured data. Another improvement was reducing latency for query workloads to support real-time feedback loops. The architecture also incorporated AI observability, which involves tracking model inputs, outputs, and performance against datasets.
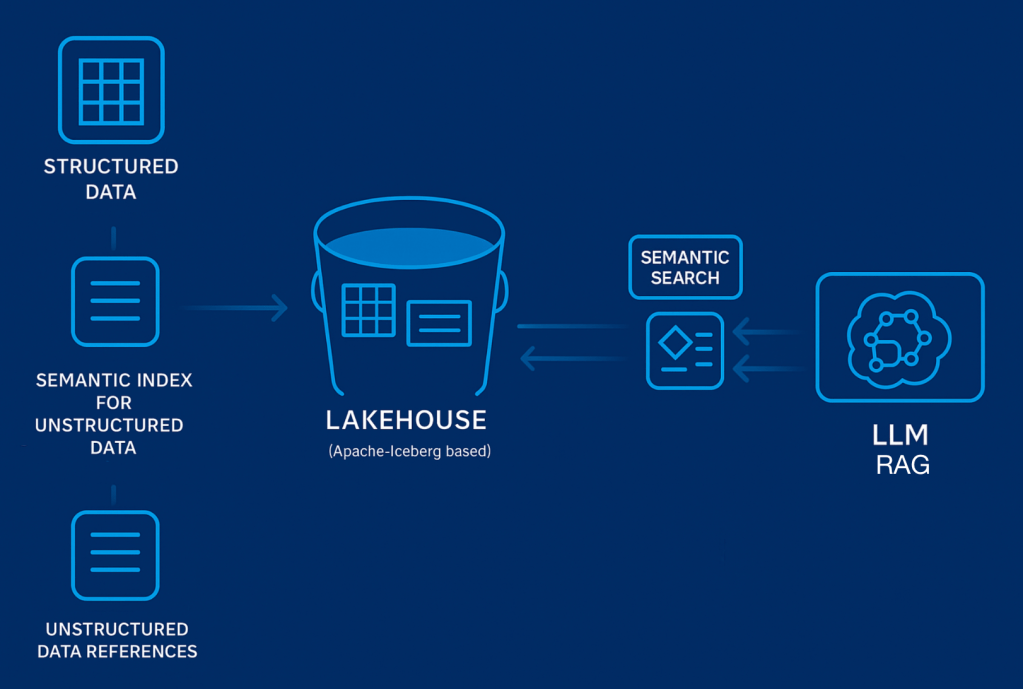
Lakehouse evolution for Generative AI.
Perhaps most importantly, Salesforce adopted the open Lakehouse architecture. As a result, we seamlessly added new data sources, sped up our query engines, added richer statistics, and enhanced catalog integrations to support the rapidly evolving needs of AI. In a world where AI systems are only as good as the data they rely on. Consequently, the Lakehouse has become the anchor point for responsible and high-performing generative AI.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.