

Imagine a Data Scientist on a life raft adrift in the middle of the ocean, lips chapped, sunburned, wearing a tattered shirt from some startup that doesn’t exist anymore. The Data Scientist manages to hoarsely say, “Water! Please Water!” and stares deliriously at the ocean and starts to weep. Alas, you know the saying, “Water, water everywhere / nor any a drop to drink.” While we gather giga- and terabytes of data every hour of every day, until it gets labeled, that data is as useful as the horizon-to-horizon saltwater is to our poor, stranded nerd.
Labeling data is not easy. It requires judgment. It’s slow. Labelers disagree with each other. There are many tools and solutions for these problems. This article is not about those problems; it is about another set of problems for labeling data: privacy, trust, and the General Data Protection Regulation (GDPR). In order to label data, you need to be legally and ethically permitted to look at it. In this post I’m going to show you how to respect the trust, privacy, and dignity of your customers by modifying open source datasets to mimic key features of their data.
This problem reared its head when developing the Contact Information Parser (CIP). Contact information is, by definition and on purpose, personally identifiable information (PII). We needed PII to make the CIP, but our Master Service Agreement (MSA) requires that we have to scrub PII from customer’s data in order to label it. So here we are, sitting on a sea (ok, “lake” ) of data, none of which we can drink. There are three solutions to this problem: get permission to use customers’ PII data, mask all of the PII before using their data to make the CIP, or find an open source datasource.
The first option would require that we renegotiate the MSA with customers coming up for renewal. It would take a long time, it would cost us lawyer fees and contract concessions, and some customers (think healthcare and finance industries) could not agree to it even if they wanted to. Building the CIP without PII data guarantees that we both don’t know how good our models are (you can’t calculate recall without a labeled dataset), and that they would probably be quite bad because of a lack of data. So the only real solution was to find an open source dataset.
As it turns out, there are a lot of open source email datasets. The most famous is the Enron corpus. There are other datasets of emails available — typically from government. Some states, like Florida, have “Sunshine Laws” that mandate emails be published within a certain number of years after a governor leaves office. Jeb Bush’s emails are publicly available (although when first released he forgot to remove social security numbers from donors). John Podesta’s emails from when he was the chair of the Democratic National Committee are publicly available.
The problem with using these corpora is that they are dissimilar to a corpus constructed out of my customers’ data. Many of the emails are not business emails. Twitter and Facebook and Instagram and YouTube did not exist in 2002 and cannot be found in the Enron dataset. The datasets include extremely idiosyncratic phenomena unknown in your customer’s data. Enron, for example, had this weird internal phone network system where everybody used a stupid 5 digit extension code and put that in their signatures.
By going with open source emails, we have replaced the legal problem of labeling PII data with a technical problem: how do we make an open source corpus look like our customers’ data? Let’s explore the simple example of how we did this for the address parser component of our Contact Information Parser (CIP). Addresses are a very common part of contact information, so not only did we need to be able to identify them, we needed to parse the individual parts of the address. The process generalizes to four components:
- Corpus profiling method:
Corpus => Profile - Profile comparison metric:
(Profile, Profile) => Double - Corpus change method:
(Corpus, Profile) => Corpus - Non-convex minimization of the profile comparison metric across the parameter space for the corpus change method
Start by making profiles for your open source corpus and your customer corpus. Then run the profile change metric in all its variations on the open source corpus. Then select the modified corpus with the shortest distance metric. The visualization below illustrates this in 2D space.
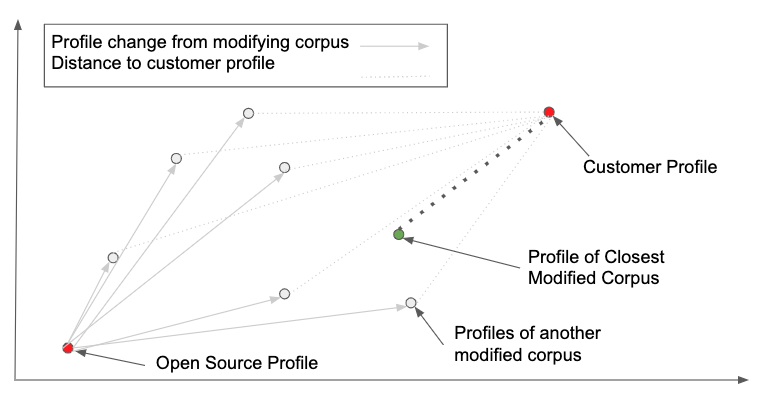
Suppose that you want a lion, but you have a Maine Coon. If you’re careful, you can adjust the Maine Coon until it has a profile that looks a lot like a lion. It won’t be a lion, but it also won’t cause you any of the problems that a lion causes you.

Let’s get started!
val input: List[String] = List("1600", "Pennsylvania", "Ave", "NW", "Washington", "DC", "20500")
val rawTags: List[Tag] = List(HouseNo, Street, Street, Street, City, State, ZipCode)
val collapsedTags: List[Tag] = List(HouseNo, Street, City, State, ZipCode)
rawAndCollapsed.scala hosted with ❤ by GitHub
ReduceByKey and for any address corpus we can produce a profile like the following:
35% HOUSE_NO — STREET
19% HOUSE_NO — STREET — CITY — STATE — ZIP_CODE — COUNTRY
5% COUNTRY
5% HOUSE_NO — CITY — STREET
3% HOUSE_NO — STREET — SUITE — CITY — STATE — ZIP_CODE — COUNTRY
2% HOUSE_NO — STREET — CITY — STREET
2% HOUSE_NO — STATE — STREET
1% SUITE — HOUSE_NO — STREET — CITY — STATE — ZIP_CODE — COUNTRY
The Profile Comparison Method: (Profile, Profile) => Double
If we’re going to modify the open source addresses to look more like our customers’ addresses, we need to measure how far apart the two are. In a certain sense, it doesn’t matter too much how you go about this. We’re going to end up using it as an objective function for the optimization that comes up later, so as long as more different is a bigger number, you’re good. I decided to opt with an asymmetrical score. In the following equation, you have the top n patterns, and you sum one less the probability weighted absolute value of the difference between that pattern’s frequency in the customer profile and in the modified open source profile.
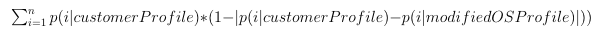
I chose this for two reasons. First, it is weighed by the target set. Second, we deal with cases where some pattern is totally missing from the target dataset.
Corpus Change Method: (Corpus, Profile) => Corpus
We can’t use our customers’ data to change the open source corpora, but we can use the profile of our customers’ data. This method is the most complex and interesting part of the shaving-a-Maine-Coon-to-look-like-a-lion process. It is likely that your method will involve a couple of parameters, so prepare to run some kind of search after you write this method to find the parameters that deliver the lowest minimum.
I tried three strategies in writing this method. First: filter out addresses from the public dataset that did not match any of the top state transition patterns in the customers’ address profile. This was a great idea, but it took our original corpus of roughly 200,000 addresses and left us with fewer than five hundred. The second idea was to create an address generator. Take the distribution of sequences from the customers’ data, and then generate examples of that sequence with tokens from the open source data. The problem is that none of these addresses would be real, with combinations of streets, cities, and states that do not even kind of exist, e.g. San Francisco, Utah and New York City, New Mexico. It also would take a kind of ouroboros logic — the heuristic parser would be used to create data for the machine learned model, somehow with an expectation of with higher accuracy. It was unlikely that the parser would learn more about the real logic of addresses than it would about the logic of my quick-n-dirty heuristic parser.
I then thought of a third way (which we ultimately ended up using): mildly destructive filtering. If an address fits one of the most common patterns [this is parameterized] in the customer data, keep it (so that those [354] perfect addresses don’t go to waste). Otherwise, try dropping all combinations of one or two tokens, and then randomly sample from those valid sequences according to their distribution in our customer’s dataset. Let’s consider the example of the White House address: List(“1600”, “Pennsylvania”, “Ave”, “NW”, “Washington”, “DC”, “20500”) which has the collapsed tag pattern: List(HouseNo, Street, City, State, ZipCode). If the pattern List(HouseNo, Street, City, State, ZipCode) is one of the top n patterns in your customer’s profile, then keep it in. It probably is. Now consider another address: List(“1600” ,”Pennsylvania”, “Ave”, “NW”, “Suite”, “2A”, “Washington”, “DC”, “20500”, “USA”) with the collapsed tag pattern: List(HouseNo, Street, Suite, City, State, ZipCode, Country). People rarely include the country code in their business address, so this is not one of the top n patterns. So we expand out all of the variations that drop one and two elements. I show the first the elements of this list to illustrate:
List(“Pennsylvania”, “Ave”, “NW”, “Suite”, “2A”, “Washington”, “DC”, “20500”)
List(“1600”, “Ave”, “NW”, “Suite”, “2A”, “Washington”, “DC”, “20500”,)
List(“1600”, “Pennsylvania”, “NW”, “Suite”, “2A”, “Washington”, “DC”, “20500”)
Each of those variations gets represented as its collapsed tag sequence. Invalid state transitions are removed, and then we randomly select a pattern based on its frequency from the customers’ profile. This produces an imbalance toward shorter sequences, so we also up- and downsample to help smooth this out.
Minimization
My corpus change method had three parameters: whether to collapse sequences, how many of the top sequences to allow to pass through untouched, and how many of the top sequences to use to characterize a corpus. An exhaustive search of all reasonable values of this space is at most a couple thousand. I wrote a Spark job to spread out all of the parameters, and process them, and collect every parameter with its profile comparison metric. We then used the best one.
I hope that this post helps illustrate how to build the products our customers want while still treating them and their data with respect. Part of what makes for a great data scientist is a genuine excitement about data, about what it tells you about the world, about how it was made, how it was gathered, and what biases it carries within it. This subjective and qualitative experience is typically subsumed under some boring corporate heading like “domain expertise,” but there’s so much more to it. What I hope this approach gives you is a way to keep feelings around, a way to keep around that subjectivity and idiosyncrasy of each dataset, without bearing the ethical and legal costs that come with using private, customer data.
Please feel free to reach out to me, either through email (nburbank [at] salesforce [dot] com) or on my Instagram page (@nburbank) where you can see portraits of the excellent colleagues I get the privilege of working with everyday.



