By Yuliya Feldman and Scott Nyberg
In our “Engineering Energizers” Q&A series, we examine the professional life experiences that have shaped Salesforce Engineering leaders. Meet Yuliya Feldman, a Software Engineering Architect at Salesforce. Yuliya works on Salesforce Einstein’s Machine Learning Services team, responsible for operationalizing AI models, which serve as the engine behind Salesforce’s generative AI products.
Read on to learn how Yuliya’s team overcomes critical engineering challenges to help create the future of generative AI.
What is your team’s AI mission?
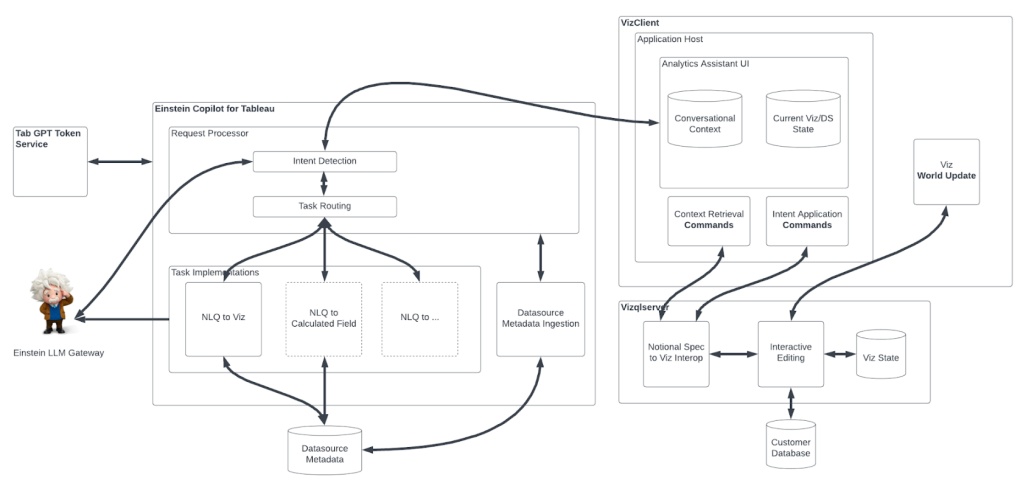
The team’s mission is to make AI models operational — enabling them to support real-world scenarios. After research scientists create their generative AI models, our team provides a feature-rich infrastructure framework for ensuring customers have a clear path to the right model that helps them rapidly receive answers to their queries.
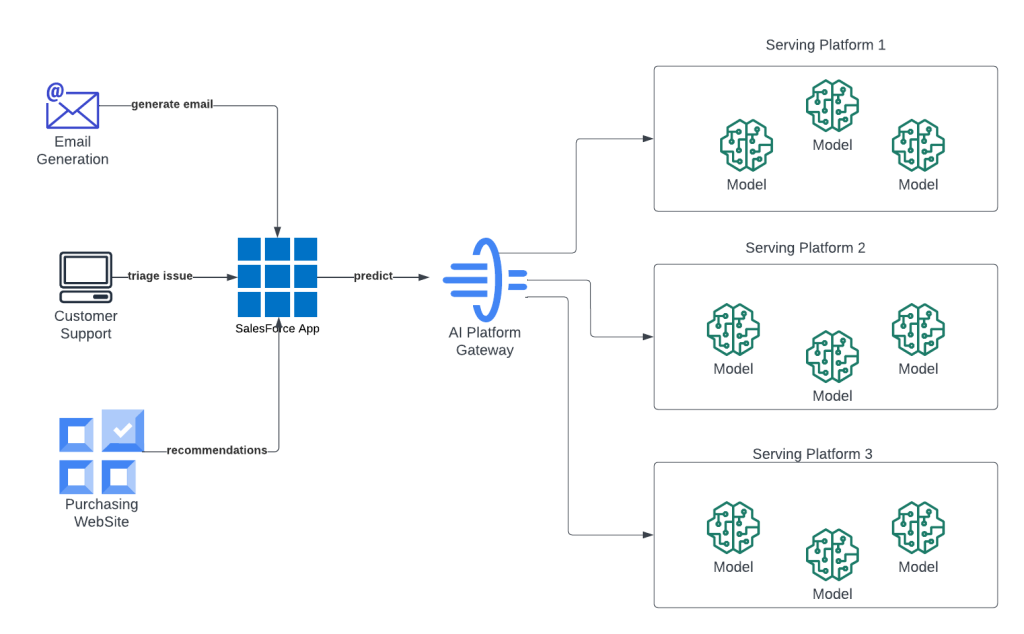
A look at the team’s AI platform in action.
How do you define AI model operationalization?
Model operationalization focuses on transforming trained machine learning models into useful tools for our customers. This transformation involves several phases:
Model storage: The trained model’s data archive — comprised of weights and metadata needed during inferencing time that constitute the knowledge gained during training — is stored for accessibility.
Code integration: The model’s data archive is conjoined with additional code, which translates the model’s data, deciphers required actions to take based on input, and delivers results to customers.
Access and registration: The model and its related code must be registered — a process that specifies the attributes and locations for model access. This enables customers to use the model’s services.
Model execution and scaling: Running the model requires the right hardware and software. Tools such as AWS SageMaker, Triton, and custom containers play a key role in loading, executing, and efficiently scaling multiple models or large models. Optimizing memory usage and incorporating intelligent routing also help drive the scaling process.
How does your team contribute to the AI model operationalization process?
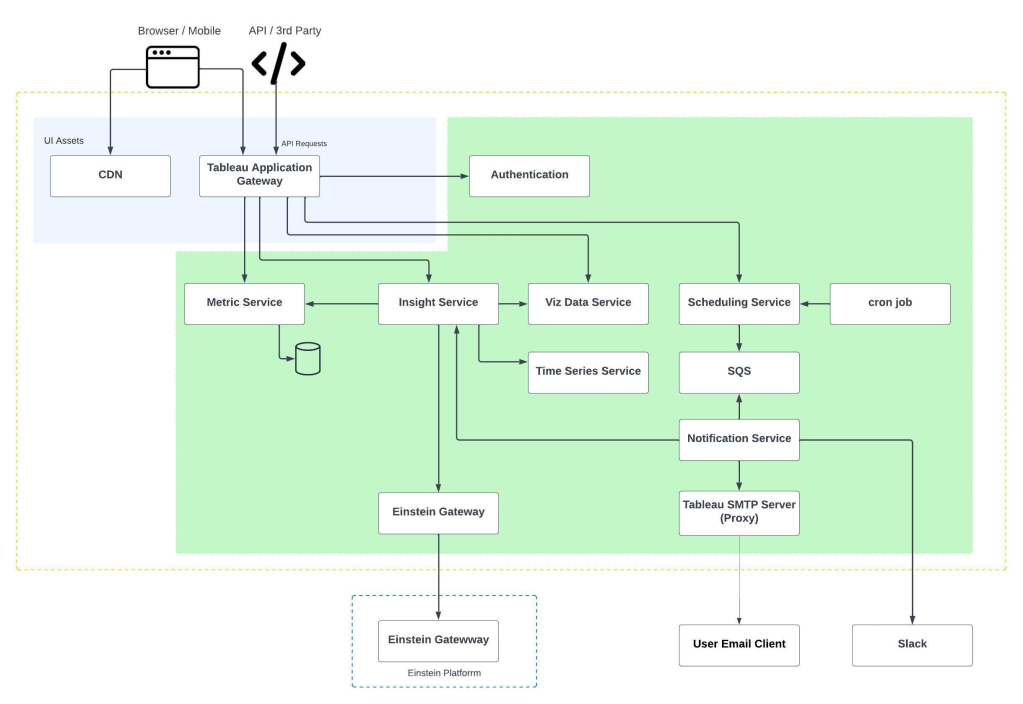
Our talented team streamlines the complex operationalization process, ensuring that models are accessible, scalable, and feature-rich — meeting the specific needs of various customer use cases. Here’s a look at what we do:
- Model upload: We provide pipelines and guidelines for ensuring that models are smoothly uploaded into our serving infrastructure and are ready for future use.
- Operationalization customization: After models are uploaded, our team’s problem-solving skills kick into high gear, where we can optimize latency, throughput, and scalability, customizing each operationalization to satisfy our customers’ specific use case requirements.
- Feature enhancement. Typically, different use cases require distinct features. Consequently, the team may enhance platform capabilities to support new set of features.
- Intelligent routing. To support instances of multiple models or complicated use cases that require data fetching and processing prior to performing predictions, our team develops intelligent routing strategies — ensuring seamless routing and complex inferencing pipelines execution.
- Production: Once operationalized, the model moves into production, where our team leverages alerts and monitoring systems to detect any issues and provides quick triage for any issues, collaborating with other teams if needed.
What are a couple big AI modeling challenges your team has recently tackled?
One key challenge we faced was running various versions of the same AI model for different Salesforce tenant organizations. This required us to run the versions concurrently while ensuring that each tenant’s requests were routed to the right model version. To address the challenge, we created additional logic and closely collaborated with other AI teams to manage routing based on tenant information and model metadata.
Another challenge was managing thousands of AI models. Providing each model with its own container endpoint is unfeasible due to the tremendous amount of hardware that would be required. Nor could we load thousands of models in one container due to memory limitations. Consequently, our team pivoted, distributing models across multiple shared containers. This ultimately supported the efficient routing of customer data queries to the correct container.
What risks does your team face in implementing your solution for customers?
The team needed to design our framework to be horizontally scalable, supporting throughput and latency. Throughput equates to how many requests the framework processes per time unit. Maintaining this balance is challenging when the framework’s capacity becomes strained. Ultimately, with each use case, we must support a variety of SLA requirements.
Additionally, to mitigate performance risks, we regularly conduct performance testing, asking questions such as:
- Is our solution working as intended?
- How can we improve performance, especially when incorporating new features?
By focusing on these concerns, our team constantly analyzes and adapts our framework to ensure we meet our customers’ ever-evolving needs.
How does your framework help improve the generative AI experience for customers?
We’re focused on delivering a smoother and more satisfying customer experience in the generative AI space, where low latency is now a key requirement.
For example, in the field of generative AI code generation, the customer query process can be quite lengthy. Some requests take more than 20 seconds to deliver a response, leading to a less satisfying user experience. This challenge sparked a new feature request: the ability to stream real-time responses. This would enable customers to watch their response be delivered line by line while it’s being generated.
This led us to enhance our framework to include model-serving services’ (e.g. Triton Server, SageMaker) response streaming capabilities, which will enable us to offer a highly fluid, real-time experience for Salesforce’s generative AI customers.
The ability to stream lies in stark contrast with our other APIs, which used a synchronous request-response model that provided responses after the request was processed.
Learn more
- Hungry for more AI stories? Read this blog post to explore how Salesforce accelerates AI development while keeping customer data secure.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.