Written by Matan Rabi and Scott Nyberg.
In our “Engineering Energizers” Q&A series, we examine the professional journeys that have shaped Salesforce Engineering leaders. Meet Matan Rabi, Senior Software Engineer on Salesforce Einstein’s Machine Learning Observability Platform (MLOP) team. Matan and his team strive to optimize the accuracy of Einstein’s AI classification models, empowering customers across industries to enhance efficiency and provide world-class customer support.
Read on to learn how Matan and his team tackle engineering challenges with the latest technologies to advance the state-of-the-art in AI.
What is your team’s mission?
Composed primarily of backend engineers, my team primarily works behind the scenes, harnessing observability features to measure and increase the accuracy of custom AI classification models — significantly improving the end-user experience.
To achieve this goal, we thoroughly analyze the predictions generated by Einstein AI classification models for our external customers and compare that with the ground truth of what happened in the real world. This apples-to-apples comparison enables us to identify areas for improvement and how we can take modeling accuracy to the next level for our customers.

MLOP uses mathematical formulas based on a confusion matrix to determine a model’s overall performance.
MLOP also validates models by subjecting them to tests using historical data provided by our customers. These tests instill high confidence in the models’ value even before deployment.
In addition to accuracy, we analyze the expenses for developing and maintaining the models. This is achieved by tagging different models’ usage data to determine the various cost to serve for each tenant within an application, which helps to reduce the overall cost of the models. These savings are ultimately passed on to our external customers.
Matan explains why he’s proud to be an engineer at Salesforce.
What are Einstein AI classification models?
Einstein AI classification models ingest and analyze customer data to formulate predictions of a particular customer outcome from a known subset of outcomes, enabling Salesforce customers with actionable intelligence to better serve their customers. The models play a vital role across numerous industries.
For example, when a customer connects with their cable service provider to discuss a service issue, Einstein’s AI model case classification feature monitors the discussion between the customer and the customer service representative (CSR) and rapidly determines the severity of the problem. It then ranks the customer’s needs as high, medium, or low, enabling the CSR to effectively provide a recommended solution.
Likewise, in the medical field, when a patient contacts their doctor’s office to schedule an appointment, the receptionist may ask some questions to understand the patient’s symptoms in order to determine the urgency of care. Einstein’s case classification feature monitors the conversation to predict the priority of the patient’s case, informing the receptionist that a patient with a potentially serious health condition should be treated as soon as possible.
At a high level, how does MLOP measure AI classification model accuracy?
First, my team gathers data from the customer and contrasts it against the data on which the models were trained. We then segment the data to examine different model elements. Back to my CSR use case example, this could include analyzing the person’s location, age, and other variables.
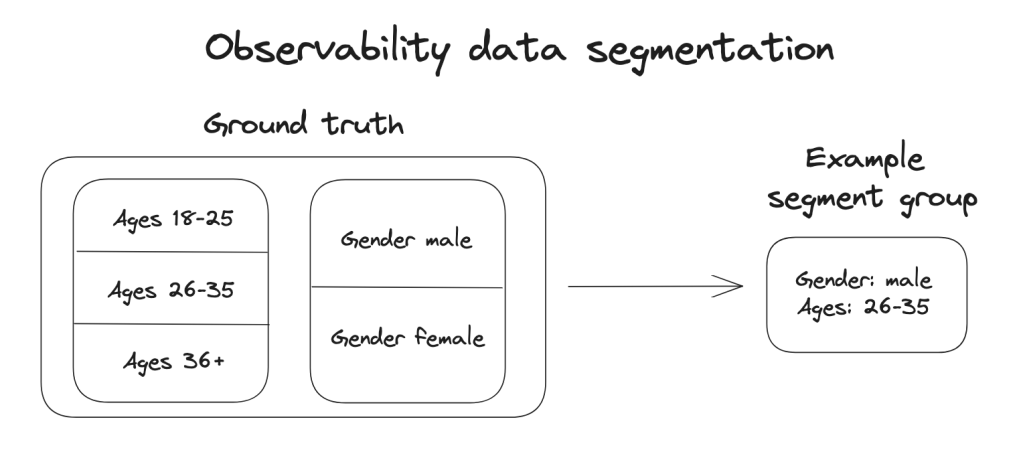
MLOP calculates a model’s performance for each relevant segment group to detect specific issues.
For example, the model may have been trained on people from New York and proved successful there but it was also used by CSRs in Oklahoma, where people’s values and attitudes may be dissimilar. In that instance, the model did not have the same level of success as it did in New York. Thus, we would recommend the model be tuned for Oklahoma CSRs to improve its inclusivity.
What’s a cutting-edge tool that your team uses to analyze AI models?
Reviewing AI modeling often requires MLOP to process terabytes of data to arrive at conclusions, which could take days or weeks to complete without the right resources.
To overcome this challenge, our team leverages Apache Spark’s distributed computation feature, empowering us to perform computations in parallel — examining huge amounts of data at once. Paralleling on one machine is fast — especially when the machine has multiple cores. Seeking to go even faster, our team learned how to spread the computational load across many machines.
What’s the endgame? We created an “infinite” parallelism factor by harnessing a vast network of commodity hardware. This enables the team to analyze tens of millions of data points in the blink of an eye to better predict and understand model accuracy.
How does your team deal with risks when analyzing AI models?
To measure and visualize a model’s performance, we must first obtain approval from internal legal and security departments. This lengthy process remains a risk for us because it could stall our team’s development time.
During the approval process, on a case-by-case basis, we must articulate our plan for handling customer data. If approved, we must encrypt the model’s customer data to keep their personal data private from our team. Ultimately, this process upholds Salesforce’s number one value: Trust.
Matan shares a story on Salesforce hackathons, one of his favorite engineering experiences.
What would someone find surprising about your team?
MLOP’s primary focus is delivering the best product and remaining relevant. To accomplish that, we constantly experiment with new tools to increase our agility, effectiveness, and efficiency — not just on our current project, but also the next one. In fact, we are always thinking one or two years down the line. Consequently, our team always pushes themselves to improve our development processes. We are never complacent with the status quo.
Learn more
- Hungry for more AI stories? Check out this blog to explore the latest AI projects at Salesforce.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.