The first part of this two part blog provided an introduction to concepts in Kubernetes and Public Cloud that are relevant to stateful application management. We also covered how Kubernetes and Hadoop features were leveraged to provide a highly available service. In this second part of the blog we will cover some of the shortcomings we ran into while using these technologies and how those were overcome.
Rolling Upgrades with StatefulSets
StatefulSets, much like other workload resources, are managed by a controller in Kubernetes. This controller is responsible for creating the Pods and PVCs requested by the StatefulSet. When that StatefulSet is updated by the user, the controller deletes and recreates the Pods one by one with the new binaries and config while retaining the name and PVC bindings. The controller updates Pods in a strict order defined by the ordinal number of the Pod. The Pods can have a readiness test which needs to pass before the controller moves on to update the next Pod. We had readiness tests for all of our components, and these typically probed the JMX interfaces of the component. The nature of the checks varied based on the component; for example, with HMaster, it was a check to see if the server has initialized. For DataNodes, we actually confirmed whether it registered with the NameNode. A similar registration check is done for RegionServers. The tests are crucial as they prevent a bad upgrade from running through an entire cluster and applying a potentially bad update.
While many of the features of StatefulSet controller were nice, there were some drawbacks:
- It only updates one Pod at a time. In a large cluster with many RegionServers or DataNodes, it could take a very long time to upgrade all the Pods.
- Components like Zookeeper, HMaster, NameNode etc. have a leader. During rolling upgrades, this leader Pod should be upgraded last. Otherwise, a new leader would be elected and that leader would then potentially get disrupted again by the rolling upgrade process.
- We place a limit on the number of unavailable Pods in a cluster (using a feature in Kubernetes called Pod Disruption Budget). When this limit is hit due to some existing Pod or cluster issues, upgrades are not able to proceed. This is because the strict ordering of StatefulSet upgrades could make healthy Pods unavailable and Kubernetes would prevent that from happening. The situation typically required manual intervention. This is especially unfortunate if you are running upgrades to address some bad code or config that was causing the unhealthy state.
To overcome these issues we came up with a custom rolling upgrade controller for StatefulSets. Fortunately, there was a flag in StatefulSets called OnDelete which allows the default controller to carry out all of its regular tasks, while delegating the sequencing of rolling upgrades to some other controller. The custom controller we built (sometimes called an operator in Kubernetes) took over the sequencing aspect of StatefulSet upgrades. It provided the following functionality:
- Introduced batched updates so a StatefulSet can specify (in an annotation) as to how many Pods need to be updated in a batch. This greatly accelerated the upgrade process.
- Looked for a special label in Pods to see if the Pod is a leader or a standby. If the leader label is found, then it schedules the Pod for updating last. Each StatefulSet Pod that has a concept of leader/standby ran a container whose only role was to detect whether the Pod was a master or standby and then update its own Pod label accordingly. The container invokes Kubernetes APIs to set the label value. The polling approach taken by the controller obviously has corner cases where the label is outdated, but by and large it minimized repeated leader elections during upgrades.
- Targeted unhealthy Pods first and not in some strict ordinal number order. This ensured that the limit on unhealthy Pods is not breached as upgrades happen. This reduced manual intervention in our upgrade process significantly.
DNS and Kubernetes
DNS is obviously important for functioning communication in HBase, but consistent DNS records is even more important when you run secure HBase using Kerberos. We used Kerberos both for authentication and encryption. Kerberos in Java requires that both forward (A records) and reverse (PTR records) DNS lookups result in correct responses that take you from a given hostname to an IP address and then back to the same hostname via forward and reverse DNS resolutions. If not, the authentication fails with cryptic errors. In Kubernetes, Pods usually change their IP addresses as they are deleted and recreated. For StatefulSets, the DNS hostnames are Pod names with an additional DNS suffix attached (like zookeeper-0.zookeeper.default.cluster.local for zookeeper-0). Kubernetes has a cluster local DNS server called CoreDNS which is updated almost immediately after any Pod is deleted or added. All of this happens automatically within a single Kubernetes cluster. While this arrangement works seamlessly, we ran into a couple of issues in our environment (described below).
Hadoop IP Address Caching
Hadoop/ZooKeeper/HBase software has been largely used in data centers with a static set of hosts where IP addresses rarely change. This resulted in ZooKeeper and Hadoop code that cached IP address resolution in various scenarios for the lifetime of the process. As you can imagine, in an environment where a DNS name changes its mapping to IP addresses, this code creates a number of bugs. While some of these bugs have been fixed over the years, we still ran into issues right away. To resolve such failures, one had to restart the Java process. We found that the issue was particularly difficult with DataNodes caching NameNode IP addresses, NameNodes caching JournalNode IP addresses, and Yarn NMs caching Yarn RM addresses. Many of these are examples of a large number of worker Pods caching the IP address of a central metadata Pod. These scenarios were particularly bad as a huge number of worker Pods become unavailable due to the caching issue, until they are restarted. This could bring a cluster down.
The solution was to find each of these issues and start fixing them in the open source code. Since this effort could take a while and the HBase service would have continuous availability issues until we did, we decided to come up with a solution that avoided the problem in the interim, specially for our production clusters. We used a Kubernetes construct called a Service. A Service can be configured to act as a virtual load balancer that introduces no additional hops or overhead. A Service gets a hostname and (unlike Pods) a permanent IP address when it is created.
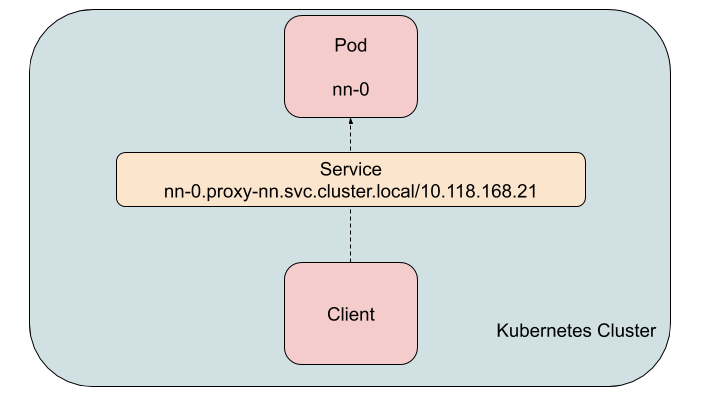
The traffic to such a Service has to be limited to sources within the Kubernetes cluster as the type of Service we used, uses network proxying rules within the cluster. This was fine as all the clients of JournalNode, NameNode, and Yarn RM were within the Kubernetes cluster and we ran HDFS only to serve the storage tier for HBase and not for any other external client. An instance of a Service was created for each Pod of the JournalNode (and similarly for NameNode and Yarn RM), thus effectively creating a virtual proxy for each of the Pods. The hdfs-site.xml, hbase-site.xml, and yarn-site.xml files all had config options which allowed the specification of a proxy hostname that is not actually the hostname of the Pod. These settings were introduced by the Hadoop community to deal with multi-homed hosts, but it worked just as well for a proxy based approach. Without these config options, the server process would have failed to start. With stable hostname/IP address for these central metadata Pods, many of the more severe caching problems disappeared. One can use this pattern even in situations where you are dealing with proprietary code that cannot be modified.
DNS outside Kubernetes Cluster
CoreDNS, the local DNS server in Kubernetes, is meant for clients within the Kubernetes cluster. The DNS server cannot be used by clients outside of the Kubernetes cluster. For DNS resolution outside of the Kubernetes cluster, the same DNS records must be populated into the Cloud DNS server; in our case, it was Route 53 of AWS. The records are created in Route 53 with a different (unique) DNS suffix so that the DNS zones don’t overlap from different Kubernetes clusters. We have many such clusters. The DNS records in this cloud DNS server are available to all VMs and Pods in our cloud infra (called a virtual private cloud).
We used an open source tool called externalDNS to propagate the DNS records to Route 53. Not all of our components needed their hostnames in Route 53. The HDFS/Yarn layer as mentioned earlier, was primarily there to serve the HBase layer and some housekeeping processes, so the clients for HDFS/Yarn were all local to the Kubernetes cluster. We only needed to propagate the DNS records of ZooKeeper, HMaster and RegionServers as those were needed by any HBase client connecting to the HBase cluster. The diagram below shows this flow of DNS records.
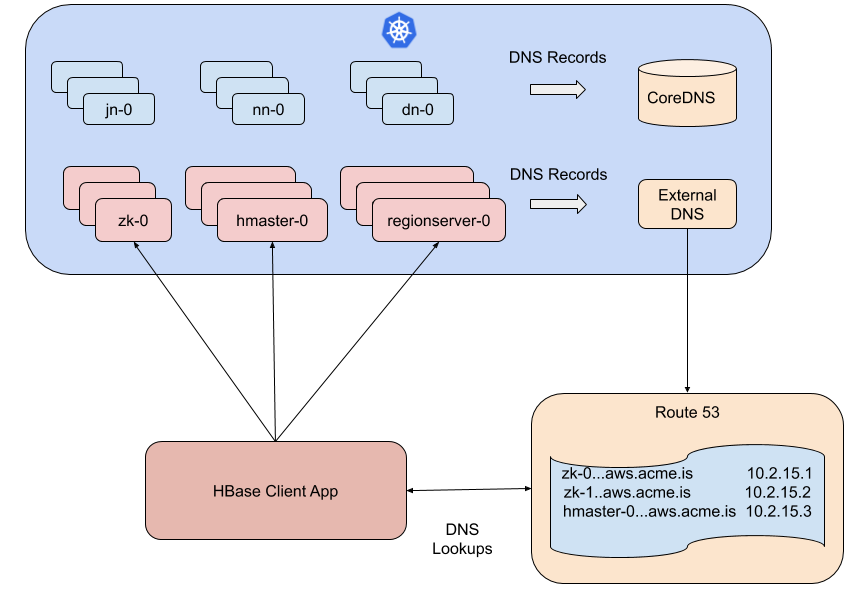
ExternalDNS uses a polling approach to find and propagate DNS records. Trying to run the polling too aggressively causes Route 53 to throttle requests, so the polling period could not be made too short. In addition, even after Route 53 accepted the DNS records, we noticed that the AWS DNS servers could take five minutes or more to propagate the records. Setting caching (and negative caching) on DNS servers to a low value did not fix the issue. All this meant that DNS records propagated slowly through the system and stayed a few minutes behind how the cluster was evolving. Also, within the Kubernetes cluster, there are multiple CoreDNS Pods load balanced by a single VIP. We found that the CoreDNS Pods refreshed their cache at different times, causing the responses to be sometimes up to date and sometimes not. To deal with many of these issues, we implemented validation processes that ran within each container as it was booting up. The process would poll its own Pod’s hostname in all the CoreDNS instances and make sure they give a consistent/correct IP address resolution (forward and reverse). If any error was found, the container startup would fail and hence retry later. This ensured that components only came up when their own DNS record had settled down in the Route 53 DNS system. This of course did not guarantee that clients running outside of the cluster got the same view from their DNS server, but by and large (from empirical data) it appears that when DNS records appeared settled down within the server cluster, the client also sees similar settled information in their DNS servers. We anticipate that this will be an area of continuing work and enhancement for us.
Conclusion
One would expect that a story about moving a database service into a very different infrastructure environment would be a story about compute/memory choices, disk related choices, and application configurations. While there were certainly choices to be made on that front, the more interesting chapters in the story turned out to be the ones related to networks and, in particular, DNS. Adapting a distributed system that for decades evolved in a static environment to a more dynamic one posed challenges that required serious efforts to overcome. In our efforts, we found Kubernetes to be both feature rich and extensible enough to meet our needs and also capable of providing a consistent management interface for our multi-cloud approach. The DNS issues did, however, come back to trouble us as the client/server communication crossed Kubernetes boundaries. We are looking at Istio and other options to help make this experience better.
By overcoming the challenges, we were able to run an HBase service right sized to our current business needs, with the confidence that it can be scaled as needed. We were able to leverage the resilience of multi-AZ infrastructure to deliver a highly available service. Public Cloud, with all its interesting challenges, did deliver strong benefits of availability and scalability without the costs of over-provisioning.
We are continuously working on innovative approaches to improve the availability, scalability and cost of running our HBase service and we are embracing exciting new cloud native features in achieving these goals. We are also actively contributing to open source projects to fix bugs and add new features. If solving problems like these interests you, check out all of our open positions at https://salesforce.com/tech.