At Salesforce, we have thousands of customers using a variety of products. Some of our products are enhanced with machine learning (ML) capabilities. With just a few clicks, customers can get insights about their data. Behind the scenes, it’s the Einstein Platform that builds hundreds of thousands of models, unique for each customer and product, and serves those predictions back to the customer.
Each customer comes with their unique data structure and distribution. The sheer scale of the number of customers and their unique data configurations sets new requirements for our processes. For example, it’s simply not practical to have a data scientist look at every model that gets trained and verify the model quality. The established process in the ML industry is to first start by manually “constructing” a model, tweaking the parameters by hand, and then training and deploying the model. In contrast, we needed a process to automate the “construction” phase in addition to model training, validation, and deployment. We wanted to automate the end-to-end process of creating a model. To solve this particular problem, we use our own (Auto)ML library on top of the open source TransmogrifAI library.
While many ML solutions deal with processing a handful of very large datasets (a big data problem), our main use case is a small data problem. Namely, to process many thousands of small-to medium sized datasets and generate models for each one of them.
The various steps involved in producing a model need to be codified in a flow. The flow automates the entire process: pulling data from our sources, performing data cleaning and preparation, running data transformations, and finally training and validating the model. There are already well-established orchestration systems to solve authoring ML and big data flows. However, they’re designed with the assumption that there are only a few (up to a few hundred) flow instances that need to run at any point in time. That’s not the case for Salesforce. We have hundreds of thousands of flow instances — several for each of our customers — that must run reliably and in isolation.
So we built, from the ground up, a workflow orchestration system designed to deal with our scale requirements. A key requirement of a scalable orchestration solution is to have a scalable scheduler — namely, the ability to trigger flow executions reliably at a particular configured section in time. In fact, the extensive tests we performed on other existing orchestration solutions revealed key problems on their scheduling approach that wouldn’t work for our use cases. For example, we ran into difficulties running more than 1,000 flows concurrently.
The most straightforward solution is a cron, a reliable method for scheduling processes in Unix-like systems. However, this solution isn’t scalable, and if the node fails, all of our schedules are gone. Similar issues occur when using single-process schedulers.
What about a distributed cron? This solution is fault-tolerant and scalable, and node failures won’t cause the schedules to be lost. This is the scheduling solution that other enterprise companies use. However, this approach puts a significant load on our system. Consider this graph of request counts for 100 flows that need to be executed every minute:
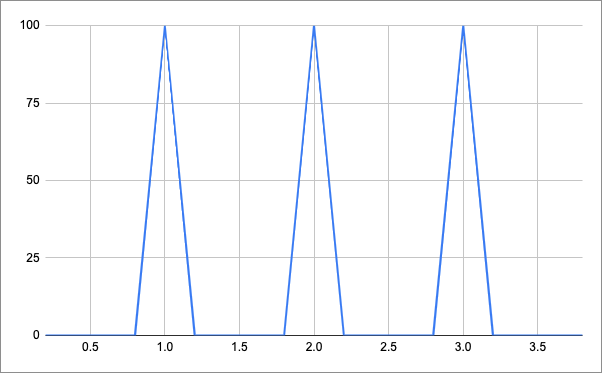
This means that, at scale, our server will be hit with a lot of requests on the minute, but will be idle the rest of the time. We want to smooth out the execution of flows to something like this:
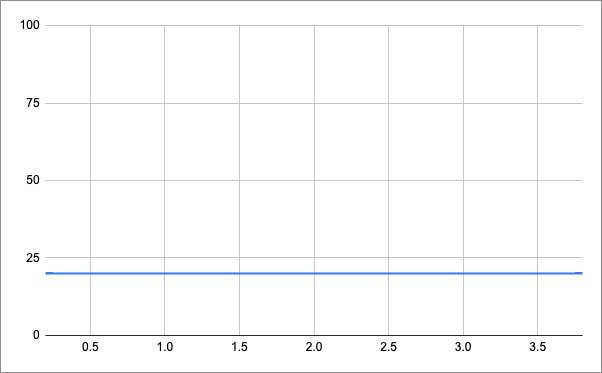
This way we get a smaller but more continuous load on our servers for the same performance!
So back to the drawing board we go.
A Timely Solution
This graphic shows our scheduler solution.
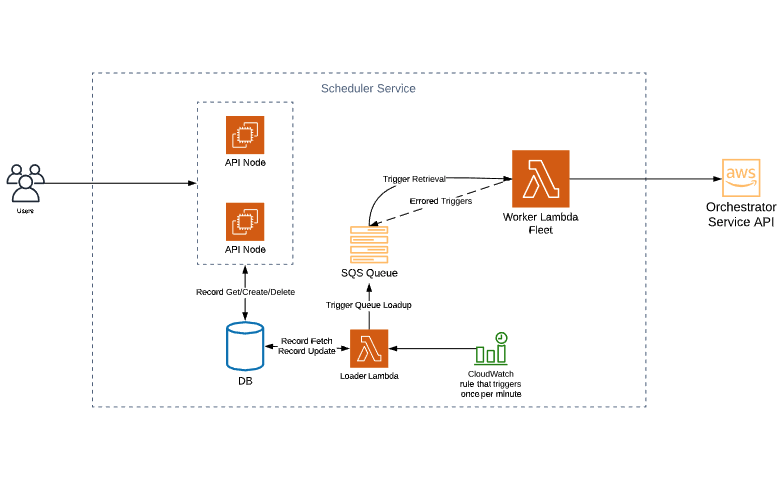
Many of these components are common to most services. We have API nodes that respond to HTTP requests. We have a database cluster that handles persistence and keeps track of schedules. The key components of this scheduler are the two lambdas connected with a queue.
What’s in a Schedule?
Before we can begin building a schedule architecture, we need to first define what a “schedule” is in more detail. In our system, a schedule is an action (HTTP call) that must performed on a period within a margin of error.
Let’s break it down one point at a time:
- Action — A schedule is an instruction to perform some action. For performance reasons, in our use case it’s mostly HTTP calls.
- Must be performed on a period — The action usually doesn’t happen just once. We normally want to do something once an hour, once a day, once a month, or a different time segment. We call the time between the actions a period.
- Within a margin of error — The margin of error on an action specifies how late an action can be executed. Say our service was down for an hour. We would have a backlog of schedules. Some scheduled actions (for example, that run once an hour) are no longer relevant. Other scheduled actions (for example, that run once a month) are critical.
These three parameters combined define a schedule.
We also define a trigger as an instance of a schedule. One of the innovations that we made in the Scheduler Service is that instead of dealing with schedules themselves, our applications operate on triggers. This allows us to keep better track of actions that we execute and easier error recovery.
Queue Up!
Now to answer the big question: how do we smooth out the volume of outbound calls? The mechanism that allows us to to do this is the queue. By queuing up triggers, we get to consume them at any pace we want without losing or blocking on any triggers. We just pick them up as they appear, and process them with our Lambdas. If any trigger fails with a recoverable error, we can just put it back into the queue with a timeout.
The queue is the distinguishing factor between our scheduler and the scheduler for other popular workflow management platforms. The queue gives us incredible scale that enables our scheduler to run over 900,000 triggers per hour (we didn’t count beyond that).
The Lambdas
We decided to use AWS Lambdas for our architecture for a couple of reasons. First, they are easily scalable. You can spin up another 1,000 lambdas with a click of a button. This allows us to easily scale up if we ever need to handle more schedules. Second, the lambdas have built-in connectors with the Amazon SQS queues, which cuts down our development time and puts the responsibility of queue consumption on AWS.
The Loader Lambda is the lambda that’s responsible for loading events into the queue. It’s run once a minute, and every time it sends a request to the database for triggers that should be executed. Then it sends the triggers into the queue. The Worker Lambdas simply consume the triggers from the queue and process them according to the data that comes with the event.
Possible Hiccups
We just described the happy path for the execution of a scheduler. But we can’t rely on our apps to always take the happy path. What can go wrong? Here are a few common scenarios.
Invalid Actions
Our actions are mostly formatted HTTP calls. But what happens if the user puts bad parameters into the schedule? What if the service that we called is down and returns a 500 code?
Whenever an action is executed, the scheduler listens for a response code and responds accordingly. If the response from the downstream service is in the 400s, that suggests that there’s a user error, and the schedule is “eaten up.” If there’s an error in the 500s, that suggests that the downstream service is simply down. In that case, we drive the schedule back into the queue to be picked up by another lambda. You can implement retries with an exponential backoff by redriving the items with a timeout.
The Bottleneck
An attentive reader might ask, “What happens if the Loader Lambda doesn’t finish on time?” This is the bottleneck in the architecture that can be reached if pressured. Sharding is the recommended solution for these types of problems. Add a column that contains a random number that represents the shard. You can even put records for each shard in a separate table. For each shard, create a loader lambda and instruct it to pull records only from a certain shard and load them into the queue. This way, you can parallelize your database loading for almost infinite scalability.
Perf Results
We tested our initial scheduler service for performance. We were able to run about 180,000 schedules per hour, but we couldn’t burst beyond 4,000 schedules per minute. By batching the SQS messages and parallelizing the Worker Lambdas, we brought the total number of schedules per hour to over 900,000 triggers per hour and burst capacity to 20,000 triggers per minute.
Scheduled Delivery
By expanding the definition of traditional schedules and putting the brunt of the scale work on serverless AWS, we created a scalable scheduler for our ML orchestration needs. By enabling scheduled executions of workflows, we serve thousands of customers with our AI models and predictions each day!