Acknowledge the amazing team: Chi Wang, Linwei Zhu, Hsiang-Yun Lee, Gopi Krishnan Nambiar, Alvin Ting
Machine learning is data-driven. Most artificial intelligence (AI) practitioners would agree that dataset ingestion, data processing, data cleansing, and data management take more than 90% of the development effort of a total machine learning project. Even though many tested data collection tools (such as Spark, Kafka, and Hadoop) are very well discussed, the topic of dataset management, surprisingly, doesn’t come up very often within the machine learning community.
At Salesforce, we knew this was a crucial part of our internal AI development process, so we designed a unique system for organizing datasets that aims to protect data integrity for updates, improve data retrieval efficiency, and facilitate lifelong learning.
Dataset Management Challenges
Before talking about our system design, let’s first take a look at the major challenges of a typical dataset management system.
Lifelong Learning
As we said from the beginning of this post, machine learning training is data-driven. A model is typically trained with stationary batches of data, but our world is changing everyday; users of the model demand that it perform well in a dynamic environment, meaning that the dataset management system needs to absorb incrementally available data from non-stationary data sources and keep the training data updated.
Dataset Versioning
Machine learning is an iterative process. When we observe model performance regression after a retrain, comparing the datasets in the two training runs could reveal a lot of details that are critical for troubleshooting. Unlike a single file, a training dataset is usually a large group of binary files. How to version different groups of files and efficiently retrieve these files with the version requires deliberate thinking.
Training data with strict access control policy
There are some highly sensitive datasets that require strict access, such as customer sales records and payment records. But training systems usually operate with normal security standards, making it impossible to train with these valuable but highly sensitive datasets.
Multi Tenant Dataset Management
There could be different users and organizations sharing one training system. This requires the data management system to restrict data access only to the authenticated data owner and not to share data or grant access outside of its tenant.
Data Accessibility
The Internet is full of data. The list of data collectors and tools seems to keep growing forever. We are building new data ingestion pipelines almost everyday, bringing in fresh and valuable data, but this also introduces lots of complexity to downstream model training components. A well-thought-out dataset management system should encapsulate all the details (such as data source, tools etc) and only expose some simple APIs for retrieving training data.
Scalability
Scalability is a basic requirement for any data system nowadays. From a machine learning training perspective, dataset fetching performance shouldn’t degrade as data volume increases. Distributed training and hyper parameter training will put lots of load on performance and needs to be accounted for in the system’s design.
Our Approach
In a nutshell, our dataset management system has three components: dataset ingestion API, dataset fetching API and dataset storage API. The generic data ingestion API allows any data collectors or clients to upload and update a dataset. The Dataset storage API organizes datasets in a special format (Dataset Storage Layout section) which is designed for protecting data integrity and fast data retrieval. The unified dataset fetching API offers users a simple and unified experience to retrieve data regardless of data type and source.
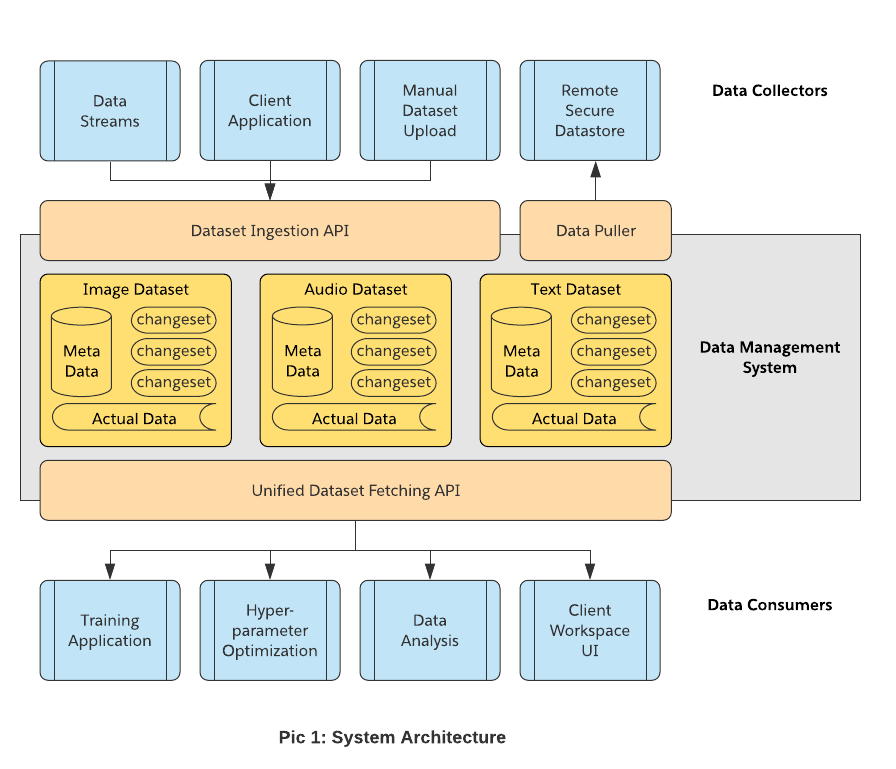
Let’s dive into the details of the major components pictured in the above system architecture diagram.
Dataset Storage Layout
As we can see from the above architecture diagram, data is organized into several boxes — different types of datasets. So how is the data stored in a given dataset?

Above is the concept graph for a dataset storage layout. The layout is designed to support continuous data updates. Every update operation to the dataset will result in creating a new changeset, and each changeset contains an index file representing the current training data view (include examples to be trained upon and labels for these examples). No actual file is stored in the changeset folder. The newly received example file will be placed with all previous examples together. The index file in each changeset only keeps a reference to these actual example files, avoiding data duplication and saving storage space.
For consuming training data from a restricted access datastore (such as billing details or user payment records), our researcher could choose to upload a query instead of real files to the dataset. During training, the query will be executed at the defined remote secure datastore, and the returned data will be sent to the training program in real time.
Our storage system acts like a broker in this case. The changeset only contains the document for the data pulling query and pulling instructions. With this design, the actual sensitive data won’t persist in our dataset store. Our system consumer, which could be researchers or other model developers, could have data analysis reports and build models from the data it doesn’t have access to. This is a huge win for production model training since data security is always a blocker for data scientists to be able to experiment on such valuable data.
Unified Dataset Fetching API
In order to make it easier to consume data from our dataset management system, we decided to provide only two APIs: prepareDatasetTarball and getDatasetTarball. These two APIs work for all types of training scenarios: image, text, and audio.
The schema of returned training data (image, text, and audio) is also in the same format, so the downstream trainer just needs to follow one standard pattern to read. Here is the sample code for how to use the API.
// Build training data selectors, all filters are optional.DatasetTarballParams params = new DatasetTarballParams()
.setLabelFilters(labelFilters) // Filter labels.
.setTimeRange(timeRange) // Filter data by modification time.
// Long number, 0.8 means return 80% dataset from latest, 1 means all..setDataPercentage(percentage)
.setChangesets(changesetList); // List of changesets.// Send dataset retrieval request to datastore.
DatasetPrepareResponse datasetPrepareResponse = dataFetcherApi.prepareDatasetTarball(orgIdStr, datasetId, params);// Get training data version.String datasetVersion = datasetPrepareResponse.getVersion();// Retrieve training data by providing its version.
DatasetTarballStatus datasetTarballStatus = dataFetcherApi.getDatasetTarball(orgIdStr, datasetId, datasetVersion);// Get actual training data url.String datasetUrl = datasetTarballStatus.getUrl();
You may have noticed that a string named dataset version is employed here for representing a training dataset from a given query. We will discuss it further in the dataset version section.
“Virtual” Dataset
Now we want to walk you through a sample scenario to elaborate what exactly “virtual” dataset means.
Normally, when we talk about a dataset in machine learning training, it means a compressed group of training examples. It works perfectly fine if we just want to explore an idea or make some ad-hoc experimentations, but it will struggle once we move to a serious development cycle. To demonstrate that, let’s look at an example.
Bob is assigned an object detection training task. The task is to train a model to recognize the trademark of an insurance company “LifeA.” At the beginning, Bob collected some trademark (tm1) images from LifeA to build a dataset named “lifeA_trademark_tm1.zip.” Bob then trained the model from it; it works perfectly and everyone is happy. After a while, “LifeA” launched two new trademarks — tm2 and tm3. To adapt to that change, Bob built a new dataset, “lifeA_trademark_tm1_tm2_tm3.zip,” which contains all three kinds of trademark images. Then suddenly company LifeA lost a lawsuit, so it gave its trademark tm2 away to its opponent. In order to reflect this in the model, Bob had to exclude tm2 images and built another dataset “lifeA_trademark_tm1_tm3.zip.” To make things worse, when LifeA is about to release a new trademark tm4, its trademark design department refused Bob’s access request to their datastore due to security concerns. How could Bob update his trademark recognition model to recognize trademark tm4 without having access to tm4 images?
From the above example, we can see where the problems are. In order to make the trademark recognition model meet the business’s needs, Bob has to produce three different datasets: “lifeA_trademark_tm1.zip,” “lifeA_trademark_tm1_tm2_tm3.zip,” and “lifeA_trademark_tm1_tm3.zip.” It’s clear that these training files are correlated and have many duplicate contents. As time goes on, the data preparation work would become super cumbersome; for example, think about what Bob would have to do to make a dataset zip that only contains trademark tm2 and the new trademark tm4. He would have to do file to file comparison among all the zip files he has to create a “tm2.zip.”
We also noticed that the correlation between these different datasets is based on file naming convention. The association among dataset files could be easily broken when the project is shared among multiple people or teams that follow different conventions.
Our thinking is to consider a dataset to be a virtual (logic) group. We separate the data collected and the data provided for training in the dataset and build a virtual dataset on top of them. One virtual dataset will be created for one machine learning task. Using the LifeA trademark recognition model training task as an example, one dataset (LifeA_trademark) would accompany the training task for its entire development cycle.
From Bob’s example, we can see that machine learning task development is a continuous process. Even though the training data we collected is persisted statically in the datastore, the actual training files used in the model training are dynamic. Instead of creating duplicate data snapshots like Bob did, we persist data once by only storing the delta to avoid data duplication but to produce different training data to satisfy business needs.

The above diagram visualizes Bob’s example. We can see that data within a dataset could keep changing and training data retrieved from it could be different based on query parameters, but the dataset as a logic group remains stationary, which gives us a handle in this dynamic environment.
One last thing to mention is that the data group (changeset) within the dataset could be just a query. The actual data will be pulled and compressed into training data during the model training at the runtime. This fits the need of training sensitive data.
Dataset Versioning
Some readers may be wondering why we need versioning in dataset management.
First, we need versions to track training data used in each training trial. If we were to find the new produced model’s performance to be degraded, then we would need to analyze and compare the training data which was used for producing the current and previous models to figure out the root cause. Without a version, it would be hard to find all the actual files used; using a filename to do so is not a reliable way.
Second, we need versions to track data updates inside a datastore. For example, we need to be able to revert certain data updates on a dataset if they are made by mistake. Versioning every data operation will make things a lot easier when it comes to data failure recovery and data deletions.
Many teams use existing version control tools like Git, which works well with code, but, due to a combination of file size constraints and the fact that git is not ideal for binaries, doesn’t work as well for datasets and trained models.
In our proposal, we assign versions based on user requests, not on actual files. For data change versioning (dataset updates), each data update request is mapped with one changeset, incrementing the next changeset version up by 1: changeset 1, 2, … N. For training data versioning, we generate a version string by hashing the data query in the submitted dataset preparation request (DatasetTarballParams — see detail in “Unified Dataset Fetching API” section). This runs much faster and requires much less computation than hashing on large groups of files.
In Summary
In short, what we’ve done with our dataset management system is to break the convention that a dataset necessarily equals a static group of files. We’ve separated the concepts of data in a datastore training data used by a given training experiment, the former being stationary but the latter being dynamic. Then, we defined the dataset as a virtual group to bring the two types of data together.
Another advantage of using this virtual dataset is it makes training with highly restricted data possible by storing only queries instead of real files, which allows us to satisfy customer requirements while also respecting their data.
To optimize for performance and to allow for versioning, we make a dataset version number from the user’s request context instead of using file hash, and we approach dataset fetching with an API-led approach.
In designing the system in this manner, we satisfied the major challenges of dataset management at scale.