By Matt Saunders and Scott Nyberg
In our “Engineering Energizers” Q&A series, we examine the professional life experiences that have shaped Salesforce Engineering leaders. Meet Matt Saunders, a Principal Member of the Technical Staff at Salesforce, supporting the Detection and Response Machine Learning team. In his role, Matt focuses on safeguarding Salesforce’s network by detecting dangerous threats at their source.
Read on to learn how Matt and his team leverage data enrichment to enhance threat detection at Salesforce, using a cutting-edge approach that tracks billions of events each day.
What is your background?
With over 7 years in cybersecurity and extensive experience in data analytics, my journey has encompassed security incident detection and response, machine learning, threat detection, and security orchestration and automation.
At Salesforce, I closely collaborate with a diverse team of data scientists, threat researchers, and security specialists on numerous projects ranging from building data pipelines to efficiently processing the data from those pipelines to detecting anomalies and risks within the data.
What was the greatest challenge your team faced?
Our team manages the monumental task of tracking billions of daily events originating from the Salesforce CRM platform, as well as Salesforce products such as Heroku, Slack, and Commerce Cloud. Within this sea of data, identifying sources of malicious activity proves extremely challenging as just one in a million events requires our team to raise an alert or take immediate corrective action.
The data we receive includes traditional identifiers like user IDs and IP addresses, which do not deliver sufficient insights. Diving deeper, IP addresses alone are not good indicators of good or bad activity, since they change often and may be shared by multiple people simultaneously. Operating in this dynamic landscape enables bad actors to constantly switch IP addresses, sharing them unbeknownst to their legitimate owners.

It remains highly impractical for humans to review even a fraction of this traffic volume. Consequently, the team relies on data enrichment, correlation, and automation to distinguish high-risk events from normal, everyday traffic.
How does data enrichment, correlation, and automation help address that challenge?
To provide useful analysis of raw log data, the team cross-references IP addresses with other key internal databases to enrich the data with context and correlate it with other identifiers.
Enriching the log data with contextual information offers additional analysis and detection options—including the ability to query and group log lines by the geographic location the user resided in.
For example, instead of merely comparing a user’s IP address to previous history or to a list of addresses that have been reported for bad activity, the team compares the user’s current geographic location or browser features with their previous activities.
The team then automates thousands of comparisons per second—detecting anomalies in the log stream around the clock without requiring operator intervention. Anomalies are scored according to their risk level. The most serious incidents receive swift attention, either escalated to an administrator, or handled through automated rules.
Browser fields, such as user agent, can also be used to distinguish between normal and unusual activity and are correlated with the user ID.
Ultimately, customers benefit because their accounts and data are kept safer, while incident response teams can correlate multiple detections across different customers to identify a pattern of activity, providing much more information about the actors behind it.
What are your steps for identifying malicious actors?
My team’s methodological process unveils and reports malicious actors in a six steps:
- Ingest raw log data. The process begins with a volume of log data flowing in from diverse sources. Various formats and identifiers—including widely prevalent IP addresses—are key components of this data collection.
- Smartly organize the logs. The team automatically categorizes logs by type, time, date, and other overarching categories—enabling streamlined queries.
- Infuse context. To add layers of insight, the team infuses raw log data with enriched context. In the case of IP addresses, the team adds information like the probable geographic location and the source IP’s network owner at the time of an event.
- Perform context-driven analysis. Having additional context in-hand allows more analysis opportunities. For instance, comparing a user’s current and historical locations helps formulate a picture on the normalcy or abnormality of their current whereabouts. This comparison would be impossible with an IP address alone.
- Determine anomaly score. Small deviations from established norms collectively define an overall anomaly score. Once the score exceeds a predetermined threshold, a detection event is triggered.
- Inform and engage the consumer. The team closes the loop by informing the affected consumer about the detection event. For example, an unusual login attempt may result in the user receiving a warning message saying, “Your account was accessed from a location near Denver, Colorado—was this you?” This is data the consumer can understand and respond to.
When is the best time to enrich the data?
The team may enrich as early as possible—during ingestion—or may delay until the final step, when internal users or customers read a notification concerning their account. Both have advantages, supporting different types of enrichments.
In the first case, logs are enriched with context as early as possible to the time the log was generated. This remains appropriate for managing dynamic identifiers like IP addresses, enabling the team to capture the context of the IP addresses at the event’s inception.
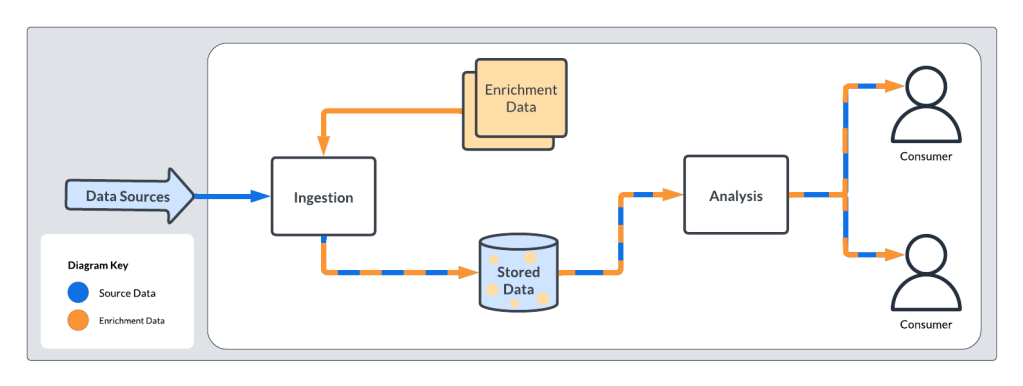
Early enrichment at ingestion time.
Conversely, waiting to enrich until users read their warning message suits scenarios where the team must include the affected users in a report. This requires the user’s updated contact information, even if the report cites data from months ago. Another advantage of delayed enrichment is that data remains independent of the reporting pipeline and data store, empowering the team to add enrichments to their reports on short notice.

Late enrichment at reporting time.
Learn more
- Interested in more security stories? Read this blog to learn how India’s threat detection team specializes in protecting Salesforce’s network by thwarting malicious threats.
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.
- Discover the latest best practices for cybersecurity. Check out the Salesforce Security Blog.