
The Problem
Any multitenant service with public REST APIs needs to be able to protect itself from excessive usage by one or more tenants. Additionally, as the number of instances that support these services is dynamic and varies based on load, the need arrises to perform coordinated rate limiting on a per tenant, per endpoint basis.
Take the following scenario where a multitenant service has two endpoints:
- GET /v1/organizations/{orgId}/product/{id}
- PUT /v1/organizations/{orgId}/product/{id}
Since a read operation is cheaper than a write operation, you may want limit them differently, say 100 calls per second vs. 10 calls per second. There is also a need to publish a service level agreement (SLA) about how often the service can be called to let integrating developers know what to expect when building out their applications. Finally, you don’t want these numbers to change based on the number of instances running of the service.
For multitenant services, there is a need to make sure no organization can consume too much of the resources. For example, let’s say both Org A and Org B are calling the service. While we promise horizontal scale to solve some of this problem, it isn’t instantaneous. Excessive calls from Org A cannot be allowed to block calls from Org B from executing, even while the service is scaling up.
The Solution
To solve this problem in a highly performant manner, we use a simple implementation of a Servlet Filter. This class makes use of defined per endpoint rate limits, a two layer cache, and a distributed counter.
Note: this solution does not perform strict rate limit checking. Due to running multiple independent instances, each org may go slightly over their limit during the last synchronization interval. We deemed this to be acceptable, as the goal is to be highly performant and protect the service, not to be completely strict.
The Rate Limit Definition
The first step in this process is defining the rate limit definitions; how often can a given endpoint be called per organization? To do this, the limits are defined in YAML, which can easily be read by any application.
slas:
- id: get-product
enabled: true
match:
methods: [ 'GET' ]
pathPattern: /product/*
tiers:
- period: 10
threshold: 1000
- id: put-product
enabled: true
match:
methods: [ 'PUT' ]
pathPattern: /product/*
tiers:
- period: 10
threshold: 100
The above definition defines limits for both getting and creating/updating products.
- For get product, a limit of 1000 calls enforced on a 10 second boundary is defined.
- For put product, a limit of 100 calls enforced on a 10 second boundary is defined.
You might ask, “Why don’t we just define them per second?” The answer is that we want to handle bursts, but still protect ourselves. By increasing the window size, the bursty nature of the traffic can be supported.
It is also possible to define multiple tiers. In that case, all tiers must pass evaluation. For example, 10 calls in 1 second but no more than 50 in 10 seconds. Again, this allows supporting the bursty nature of API calls while still managing the overall throughput allowed.
Distributed Counter
In order to solve the coordination problem between multiple instances of the service, a distributed counter is used (See “A Deeper Look” below for details of the key). The counter is then synchronized out to a distributed cache so that an accurate count across all instances of the service can be maintained.
This information is then matched up with the rate limit definitions that determine how often an API can be invoked over what period of time. This period of time is used as a window that maintains the count until the limit resets.
The Response
Now that per tenant, per endpoint limits are enforced, the caller of the API needs to be informed of what they are allowed to do. To do this, the following headers are returned with each API call.
- x-ratelimit-limit: number of calls allowed in the time window
- x-ratelimit-remaining: number of remaining calls that can be made in time window
- x-ratelimit-reset: number of seconds remaining in the time window
If the caller has exceeded the limit, a 429 “Too Many Requests” error is returned, and the caller needs to back off for the remaining time in the window.
Note: The format of x-ratelimit-XXX, while not an RFC, is commonly used by SaaS services such as Github and Twitter.
A Deeper Look
The Counter’s Key
To ensure uniqueness, the counter needs to include the tenant (or org) ID, the endpoint (minus any variables within the path), the HTTP method being invoked, and the start and end time in its name.
So then, how do we compute the start and end time?
As shown above, each rate limit definition has a “period” or window over which it is enforced. In the example, this is 10 seconds.
To compute the window start time and end time, the following algorithm is used. This will always truncate the current system time to the nearest bucket as long as it is within the window.
long windowTime = 10000; // 10 seconds in milliseconds
long startTime = System.currentTimeMillis();
long windowStart = (startTime / windowTime) * windowTime;
long windowEnd = windowStart + windowTime;String counterKey = orgId + "_" + endpoint + "_" + httpMethod +
"_" + windowStart + "_" + windowEnd;
Once a new window begins, the key automatically changes to the new start time.
Let’s take the example of a system time of 162731878077 (which is 2021–07–26 12:59:40.077).
- Window Start = 162731878077 / 10000 = 16273187.8077 (truncated to 16273187 due to integer math) * 10000 = 162731870000
- Window End = 162731870000 + 10000 = 162731880000
100 ms later
- Window Start = 162731878177 / 10000 = 16273187.8177 (truncated to 16273187) * 10000 = 162731870000
- Window End = 162731870000 + 10000 = 162731880000
Note: This algorithm favors simplicity in order to avoid having all instances synchronize the start time. What this means is that the first window may end up being short (roll over early), but all subsequent windows will match the desired size.
A Two Layer Caching System with Automated Clean Up
As with any SaaS offering, minimizing the latency induced within an API call is crucial to success. For this implementation, a two layer caching system is used, one local to the service instance, that utilizes the library Caffeine, and a second externalized via Redis. (These were chosen as they are lightweight, highly efficient, and support setting a time to live on an entry. Additionally, Redis supports atomic increment operations which allows for easily maintaining the distributed count).
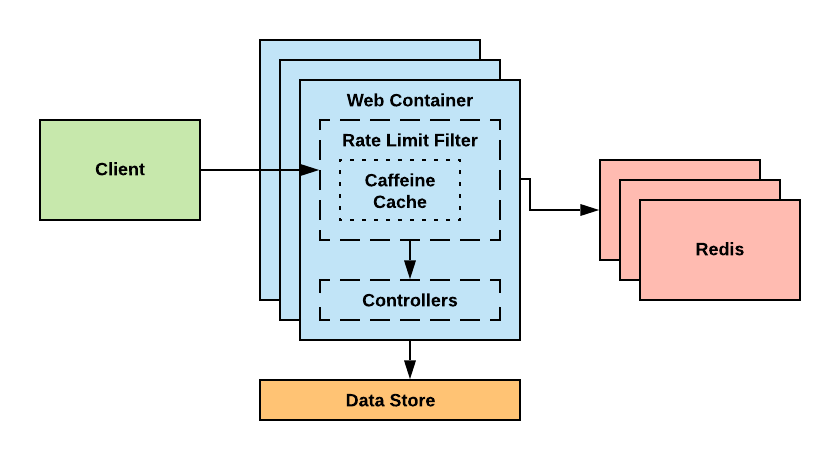
This approach allows for choosing what interval to synchronize with Redis instead of forcing each API call to reach out to the external cache. The way this is implemented is as follows.
// The rate limit window in milliseconds
long windowTime = 10000;// The local cache
Cache<String, Counter> callsPerCounterCache = Caffeine.newBuilder().maximumSize(1000)
.expireAfterWrite(windowTime + 2000, TimeUnit.MILLISECONDS).build();// The counter class
class Counter {
long callsSinceLastSync = 0;
long totalCalls = 0;
long lastSyncTimeMs = 0;
boolean firstTime = true;
}// Get Counter and Increment
Counter counter = callsPerCounterCache.get(counterKey, k -> new Counter());
counter.callsSinceLastSync++;
counter.totalCalls++;// If we have reached a sync interval, sync with Redis
// This is always true on the first pass
if (System.currentTimeMillis() - counter.lastSyncTimeMs > syncThresholdMs) {
syncWithRedis(counterName, windowTime, counter);
}return counter.totalCalls;/////// syncWithRedis method ///////
long currentTime = System.currentTimeMillis();
RedisCommands<String, String> sync = redisConnection.sync();
counter.totalCalls = sync.incrby(counterName, counter.callsSinceLastSync);
// If the counter expire time has not been set, set it
if (counter.firstTime) {
sync.expire(counterName, TimeUnit.SECONDS.convert(windowTime + 2000, TimeUnit.MILLISECONDS));
counter.firstTime = false;
}// Reset the local count and last sync time
counter.lastSyncTimeMs = currentTime;
counter.callsSinceLastSync = 0;
Performance Testing
In order to validate the performance of the rate limiter, the following test was run on the following environment.
Test
- 1000 calls per second to a single API endpoint
- 25 tenants
- 3 instances of the service
- Synchronize with Redis once per second, per tenant/endpoint
Environment
- Kubernetes Environment deployed in AWS US-East-1
- 3 instances each running on their own m5.xlarge instance (4 vCPU, 16 GB RAM)
- Test Clients running in AWS US-East-1.



The above charts show that the expected 75 (25 tenants across three instances) calls are made to Redis per second, that the Redis atomic increment latency is a p95 of 15.7ms, and that, by only syncing once per second, the rate limiter induces a p95 of 1 millisecond of latency under load.
Conclusion
As companies move more towards API-first, multitenant, horizontally scalable, distributed offerings, it is paramount that they build in the service protection to maintain stability under load. The above article demonstrates a simple implementation with a two layer cache approach that can be employed to protect the system without hindering performance.



