By Vaibhav Raizada and Ashish Gite.
In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we meet Vaibhav Raizada, a Senior Software Engineer building Salesforce Prompt Builder. Vaibhav led his team in developing multimodal AI capabilities that unlock file-based data previously invisible to Prompt Builder.
Discover how the team tackled real-time file processing challenges without relying on pre-indexing, addressed architectural complexities to unify Data Cloud and non-Data Cloud systems, and implemented intelligent partial grounding based on initial customer feedback.
What is your team’s mission building enterprise multimodal AI capabilities for Salesforce Prompt Builder, and how does this unlock file-based data that was previously invisible to AI agents?
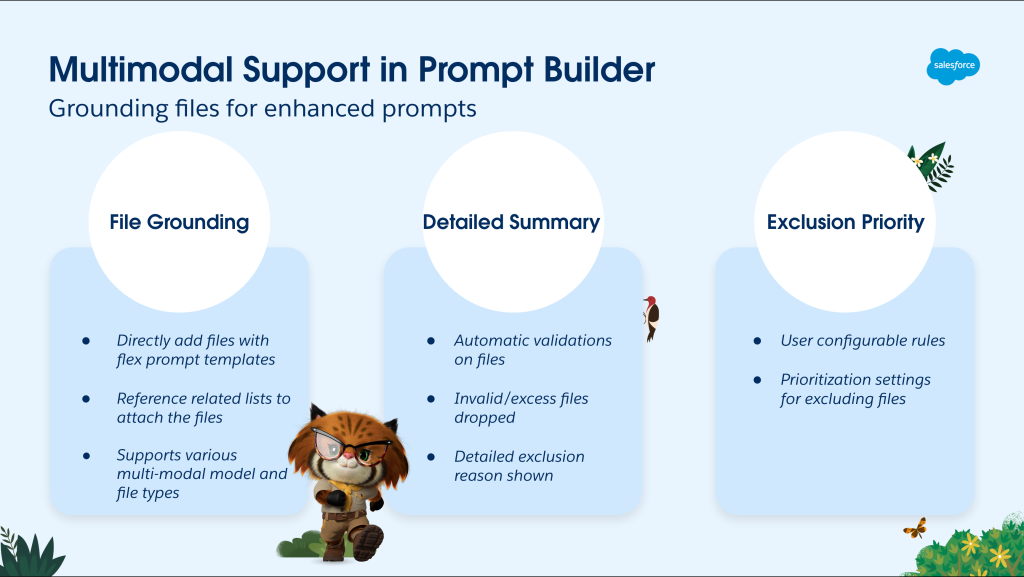
Prompt Builder is a powerful native tool within the Agentforce suite, designed to bridge the gap between large language models (LLMs) and unique business contexts. By leveraging reusable prompt templates with dynamic placeholder values, it ensures that AI can seamlessly integrate with your specific business needs. Our team’s mission while building multimodal AI capabilities was to enhance this framework by incorporating rich file content, such as PDFs, screenshots, annotated documents, and images, which were previously invisible to Prompt Builder elements.
Salesforce organizations are rich in structured data, but a significant amount of critical business information is often stored in files and documents. By making this file-based content accessible to AI agents and prompt templates, we are unlocking new, transformative use cases. For instance, document field extraction can now automatically pull addresses, names, gender, and age from PDFs, significantly reducing the need for manual processing. Insurance companies are leveraging our technology to read claim photos and policy documents, generating detailed claim assessment summaries. This not only speeds up the claims process but also enhances accuracy and customer satisfaction.
For example, in the travel industry, this capability can streamline application processes and improve the overall customer experience. Support teams are also reaping the benefits through case attachment summarization. AI agents can now process all attached files in the case related list and provide concise summaries, enabling human agents to quickly understand issues without the need to manually review each file. This not only saves time but also ensures that support teams can provide more efficient and accurate assistance — resulting in decreased AHT (Average Handle time) and increased FCR (First Call Resolution).
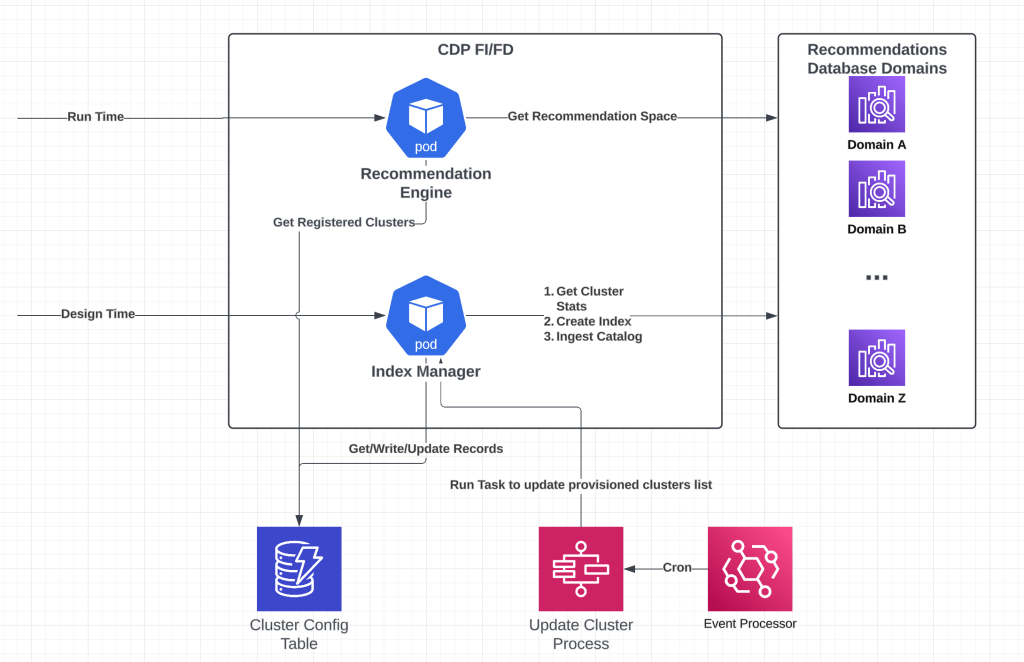
Multimodal support in Prompt Builder.
What technical infrastructure challenges did your team face building real-time AI file processing pipelines that handle PDFs and images without pre-indexing or caching dependencies?
The challenge for enterprise teams lies in integrating file-based content with prompt templates across complex workflows, which goes beyond simply sending files to large language models (LLMs). We needed a solution that could handle real-time processing, validate files, convert formats, and seamlessly integrate with existing Salesforce workflows without causing performance bottlenecks or requiring pre-indexing and storage layer caching.
In response, we developed a real-time file processing pipeline that securely fetches content from our File store on each prompt execution. This pipeline validates files across various types, sizes, and MIME types, then converts them to base64 before sending to LLMs for grounding. To extend these capabilities to external sources like Flows and Apex, we introduced a new object type called “Prompt Template Attachment”. This object is exposed externally, allowing teams to upload files within Prompt Builder without needing to use the prompt template tool directly.
We also upgraded our input adapters to resolve files from external sources and expose both metadata and content during the hydration layer. To ensure compatibility with multiple LLM providers, including OpenAI, Gemini, and Anthropic models, we built a compatibility abstraction layer. Each model has unique capabilities and limits, so we created a compatibility engine that preprocesses these model limits and capabilities. This ensures that each model integrates seamlessly without the need for complete pipeline rewrites, making the process smooth and efficient for all users.

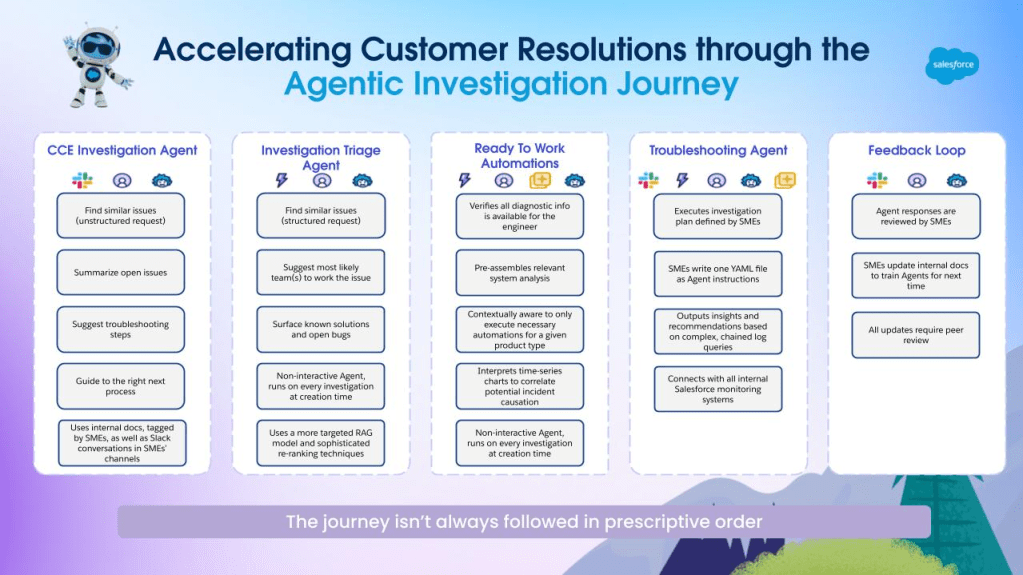
High level overview of multi-modal integration within Prompt Builder.
What architectural complexities emerged when building unified multimodal AI systems that work for customers both with and without Data Cloud licenses?
The architectural challenge was to support diverse customer configurations without fragmenting our codebase. We aimed to build multimodal capabilities that could serve both Data Cloud and non-Data Cloud customers through a single execution pipeline.
For Data Cloud customers, we provide access to unified profiles and file connectors, allowing them to use their existing pipelines and content version services. However, non-Data Cloud customers don’t have access to Salesforce Drive or file connectors, which could lead to separate implementations and feature disparities, as well as increased maintenance complexity.
To address this, we implemented an input attachment adapter layer that integrates both paths to provide file content. Data Cloud customers can continue using their established pipelines, while non-Data Cloud customers leverage the File store. The File store doesn’t require Data Cloud licensing, making it an out-of-the-box solution for those who prefer not to build external pipeline infrastructure.
Security was a significant concern, as Data Cloud manages access controls through internal APIs. For non-Data Cloud customers, we had to build explicit access control checks to prevent users without file access from receiving files in responses. This dual-path architecture ensures unified functionality while respecting different licensing models and security requirements. Ultimately, we achieved our goal of avoiding code forking and supporting a wide range of customer configurations.
What AI engineering lessons did you learn from your initial approach that influenced how you rebuilt validation capabilities in the next version?
A core takeaway was developing the agility muscle to adapt our validation design to real-world usage patterns. In practice, multimodal inputs are highly diverse: users upload files of different formats, sizes, and quality, often in the same request. A rigid validation strategy would have limited system utility and created friction.
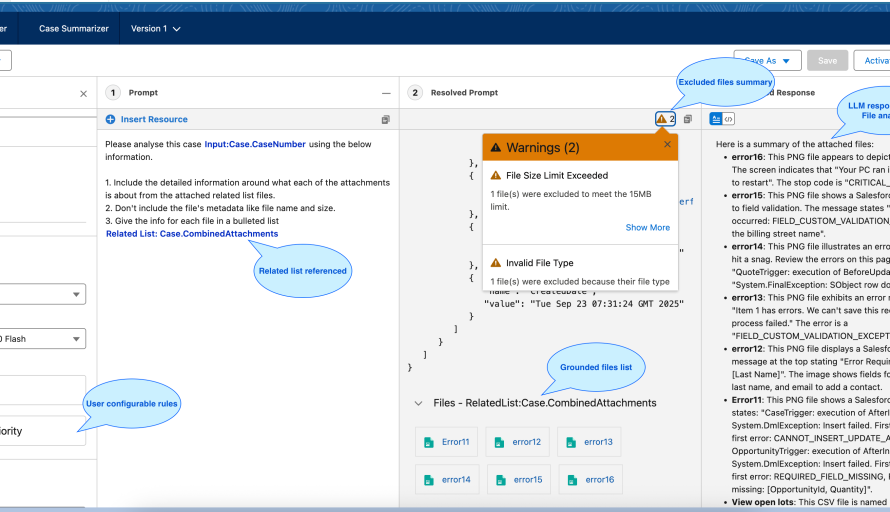
By treating adaptability as a design requirement, we rebuilt validation around partial grounding. Each file is validated and processed independently, by automatically excluding invalid files and throwing warnings, rather than halting the entire workflow. This shift required us to introduce:
- Independent validation units to isolate errors at the file level.
- Fault-tolerant orchestration that ensures partial success without compromising integrity.
- Transparent error pipelines that provide users with detailed feedback.
The result was not just a stronger validation framework but also a repeatable engineering practice: rapid iteration based on feedback, with adaptability embedded into the architecture.

Enhanced multi-modal integration highlighting exclusion rules and a summary of omitted files.
What scaling challenges are you solving as multimodal AI capabilities expand across Salesforce’s platform processing 50 million daily file uploads?
Our scaling challenges centered on deeply integrating with Data Cloud infrastructure without incurring additional costs for customers or requiring new server onboarding. To achieve this, we developed an orchestration layer on top of Data Cloud using content services APIs, which can handle up to 50 million daily file uploads.
Currently, LLM gateway team has built caching strategies around model artifacts. This will reduce latency by preventing the need to repeatedly fetch the model capabilities when prompt templates with identical models are executed by different customers.
Looking ahead, our roadmap includes implementing parallel file processing to replace the current sequential method used by the content version service, which will significantly speed up the handling of multiple files. Additionally we will experiment with file compression techniques to intelligently restructure files that exceed the 15 MB model limits. This will enable us to ground the prompt template with more attachments without compromising file quality.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.