Up until recently, we, like many companies, built our data pipelines in any one of a handful of technologies using Java or Scala, including Apache Spark, Storm, and Kafka. But Java is a very verbose language, so writing these pipelines in Java involves a lot of boilerplate code. For example, simple bean classes require writing multiple trivial getters and setters and multiple constructors and/or builders. Oftentimes, hash and equals methods have to be overwritten in a trivial but verbose manner. Furthermore, all function parameters need to be checked for “null,” polluting code with multiple branching operators. It’s time-consuming (and not trivial!) to analyze which function parameters can and cannot be “null.”
Processing data from the pipelines written in Java often involves branching based on the types or values of data from the pipeline, but limitations to the Java “switch” operator cause extensive use of sprawling “if-then-elseif-…” constructs. Finally, most data pipelines work with immutable data/collections, but Java has almost no built-in support for separating mutable and immutable constructs, which forces writing additional boilerplate code.
In deciding how to address these shortcomings of Java for data pipelines, we selected Kotlin as an alternative for our backend development.
Why Kotlin?
Our choice of Kotlin was driven mostly by the following factors:
- Rich support in Kotlin for data bean classes enables us to stop writing explicit getters and setters.
- Optional parameters and simplified constructor syntax let us avoid writing multiple constructors and builders.
- The presence of a “data class” construct prevents us from having to write explicit overriding hash/equals functions with trivial boilerplate code .
- The baked-in type system null pointer safety guarantees that no necessary null pointer checks are skipped, and we get warnings about unnecessary checks, thus greatly reducing boilerplate code. In our experience since switching to Kotlin we have pretty much forgotten about dreaded runtime NPE exceptions.
- A robust mechanism for separating mutable and immutable data allows much simpler reasoning about parallel data processing.
- A versatile “when” operator allows for writing flexible and concise branching expressions based on data types and values.
- Seamless integration with Java allows us to use any and all Java APIs without any mental overhead. The use of Kotlin interfaces from Java is also almost frictionless, and seen our APIs implemented in Kotlin be consumed by other teams using Java.
Here is a trivial example of Kotlin code that demonstrate some of the points that were enumerated above:
enum class RequestType {CREATE, DELETE}
data class RuleChange(val organizationId: String, val userIds: List<String>, val request: RequestType)
The same implementation in Java would look like this:
enum RequestType {CREATE, DELETE}
public final class RuleChange {
final private String orgraniztionId;
final private List<String> userIds;
final private RuleChange ruleChange; RuleChange(String organizationId, List<String> userIds, RuleChange ruleChange) {
this.orgraniztionId = organizationId;
this.userIds = userIds;
this.ruleChange = ruleChange;
} final public String getOrgraniztionId() {
return orgraniztionId;
} final public List<String> getUserIds() {
return Collections.unmodifiableList(userIds);
} final public RuleChange getRuleChange() {
return ruleChange;
} @Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
RuleChange that = (RuleChange) o;
return Objects.equals(getOrgraniztionId(), that.getOrgraniztionId()) && Objects.equals(getUserIds(), that.getUserIds()) && Objects.equals(getRuleChange(), that.getRuleChange());
} @Override
public int hashCode() {
return Objects.hash(getOrgraniztionId(), getUserIds(), getRuleChange());
}
}
These two pieces of code do almost exactly the same thing. We left out some Kotlin goodies that would require additional boilerplate code to implement in Java, but the gist of this example is probably obvious by now — Kotlin code is much more concise and packs a lot of freebies for developers.
A Clear Code Example in Kotlin
One good example of Kotlin’s succinct and understandable code is our rule change processor Kafka streams job that does validations on input data for null safety, deserializes the data using extension function, and then uses exhaustive pattern matching to perform operations on the data.
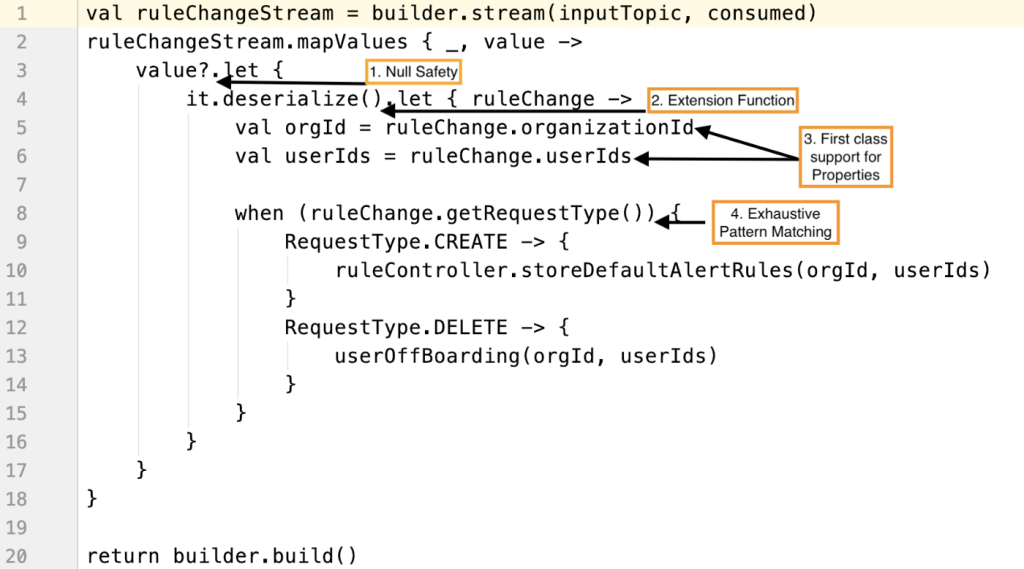
Here you can clearly see several of the benefits Kotlin offers us.
- Null Safety:No more ugly if/else null check. We used Kotlin’s built-in null safety check, which prevents NPE and makes code more readable.
- Extension Function: Kotlin provides the ability to add new functions to the existing class without having to inherit that class. Doesn’t
it.deserialize()on line 4 look more readable than using some helper class to deserialize the data? - First Class Support for Properties: We don’t need to write get/set methods because Kotlin offers first-class support for properties, as seen on lines 5 and 6.
- Exhaustive Pattern Matching Using
whenConstruct: Kotlin’swhenexpression starting on line 8 does exhaustive pattern matching with enum values and case classes. No more no-op default case like we have to write when using Java’s switch construct.
Kotlin for Activity Platform in Salesforce
Activity Platform is a big data event processing engine that ingests and analyzes 100+ million customer interactions every day to automatically capture data, generate insights and recommendations.
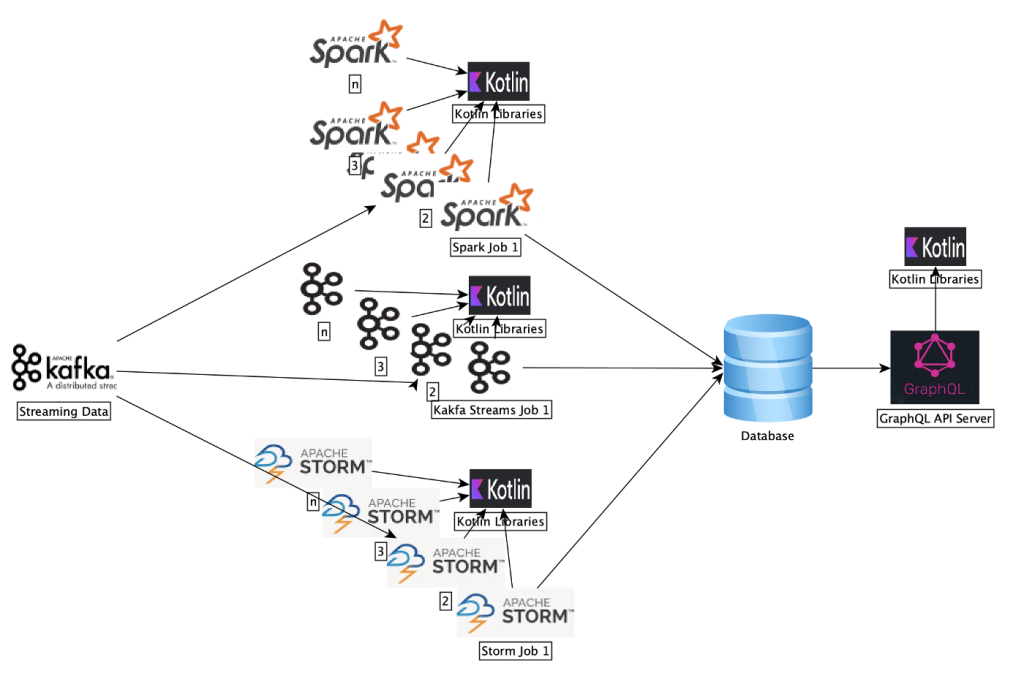
We’ve widely adopted Kotlin in place of Java for backend development across Activity Platform as you can see in the diagram above. Here’s what the flow looks like:
- We process activity data in streaming fashion and generate intelligent insights using AI and machine learning that power multiple products across Salesforce.
- To process this data and generate insights, we run big data systems (like Kafka-Streams, Spark, and Storm) and expose an HTTPS GraphQL API for other teams to consume data.
- We write all our business logic libraries in Kotlin.
- Kafka Streams jobs are written in Kotlin. We use Kafka Streams jobs for simple map, filter, and write operations.
- Apache Storm topologies are written in Kotlin. Storm topologies perform General Data Protection Regulation (GDPR) operations on our data.
- Spark Jobs are written in Scala, but they consume libraries written in Kotlin. We run complex SparkML models using these Spark jobs.
- GraphQL APIs are also written in Kotlin while being powered by a Jetty server.
So, essentially, we have used Kotlin in all the places we could have used Java or another JVM language.
Benefits We’ve Seen from Moving to Kotlin
Kotlin’s data classes and immutability have ensured consistency (preventing accidental data corruption) when other teams use our libraries. Its functional syntax and immutability have provided an elegant way for us to write the processing streams we need for our data pipelines. Having multiple classes in one file and being able to use top level functions has made it simple for us to organize code, greatly reducing the number of files we need to navigate. And there’s even more we love in Kotlin that we could cover in this blog post, like extension functions, type aliasing, string templating, concurrent code execution using coroutines and async-await.
There is lot to gain by using Kotlin for building data pipelines, not least of which is developer productivity. It has been extremely easy to onboard engineers from different programming backgrounds like Java, Scala, Python, and they have all liked the programming constructs Kotlin has to offer. This is why it’s one of the most loved programming languagesof 2020. We will continue to expand its usage while building new pipelines and switching over old pipelines to use Kotlin. We are also interested in using Kotlin for building Spark jobs as and when more stable support for Spark becomes available. For all those folks who are interested in building data pipelines, we recommend giving Kotlin a try to see its advantages over other programming languages.