By Rajeev Kumar and Bhargava Ravali Koganti.
In our “Engineering Energizers” Q&A series, we shine a spotlight on the innovative engineers at Salesforce. Today, we feature Bhargava Ravali Koganti, a Lead Software Engineer who is part of Data Cloud’s data governance system. Her team developed Data Cloud’s first comprehensive unstructured security system. This system automatically detects and masks sensitive information across vast amounts of enterprise documents.
Explore how the governance team tackled the challenge of processing hundreds of gigabytes of unstructured data using Spark pipelines, addressed accuracy issues in automated PII detection with machine learning models, and created security gatekeeper systems to safeguard enterprise content from unauthorized AI access while ensuring legitimate functionality.
What is Data Cloud’s mission for enterprise unstructured data governance and PII protection in AI agent environments?
The Data Cloud governance team is dedicated to implementing end-to-end security across all objects and process definitions. Our primary goal is to protect customer data by employing robust mechanisms that prevent unauthorized access to sensitive information entrusted to us. This comprehensive approach includes establishing limited access controls for process definitions, ensuring that only authorized personnel can process and handle specific data.
We are actively aligning with industry standards for securing big data at scale, especially as the era of AI agents introduces new challenges. Balancing these challenges is crucial, as AI agents need broad data access to make optimal decisions and provide comprehensive customer answers. At the same time, human agents must have controlled access to prevent exposure to sensitive information such as Social Security numbers or personally identifiable information (PII).
The importance of these governance capabilities is evident, as enterprise customers have delayed major data ingestion initiatives pending the availability of these features. Financial services and healthcare organizations, in particular, require robust unstructured governance capabilities before they can share sensitive documents containing customer PII, medical records, or regulatory data with Data Cloud systems. Our commitment to these security measures ensures that our customers can trust us with their most sensitive information.
How do you build enterprise-scale automated PII detection systems using Apache Spark and machine learning that process terabytes of unstructured documents?
The most significant engineering challenge was achieving massive scale for enterprise data processing while maintaining high accuracy. Our solution needed to handle hundreds of gigabytes of data through our Spark pipelines, which required seamless integration with Spark infrastructure.
To find the best fit, the team evaluated several detection frameworks:
- Microsoft Presidio: Chosen for its robust enterprise capabilities.
- Amazon Comprehend: While cloud-native, it offered limited customization.
- Various spaCy models: Open source, but they required extensive custom development.
Integrating Microsoft Presidio posed substantial challenges, particularly in configuration, experimentation, and optimization for tag detection across different data types. We designed comprehensive storage schemas for the detected tags and implemented policy enforcement mechanisms that operate across distributed systems.
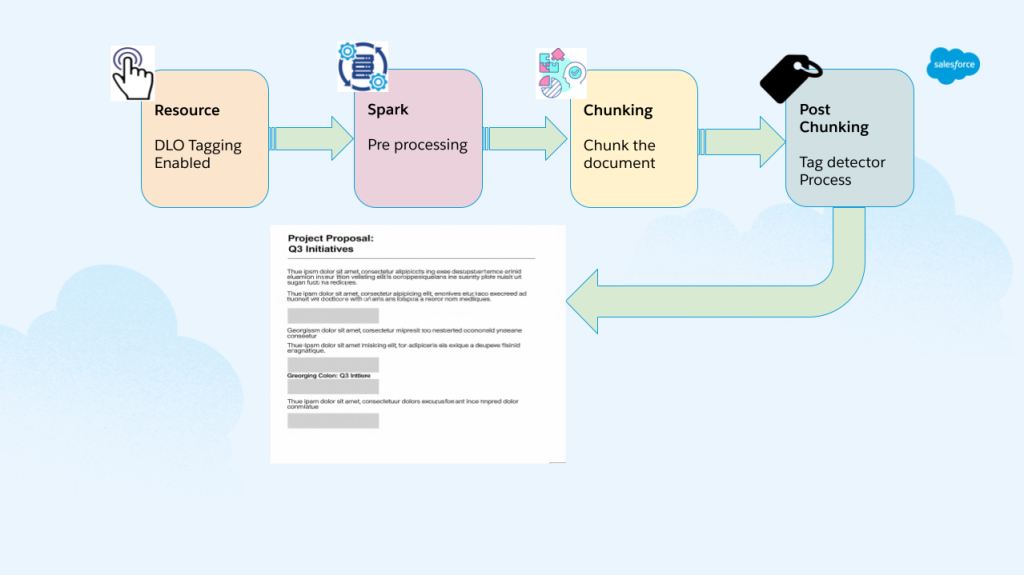
Tag detection architecture.
During performance testing, we encountered significant scale challenges. Our implementation successfully detected 250,000 PII tags across sample enterprise datasets, including 130,000 email addresses and 100,000 phone numbers that would have been exposed without governance protection. To optimize processing, we implemented extensive caching, parallelization, and Spark utilization strategies to ensure enterprise-grade throughput across millions of document chunks.
What machine learning optimization challenges emerge when processing terabytes of unstructured enterprise data for accurate PII detection?
Achieving accurate automated detection was a significant engineering challenge that required extensive work on machine learning model optimization and context-aware tuning. While Microsoft Presidio was our go-to solution, the default version lacked the contextual understanding needed for different organizational environments.
To enhance our detection capabilities, we delved deep into named entity recognition methodologies. This involved breaking down sentences into chunks and identifying contextual tags tailored to specific organizational needs:
- Financial organizations: Account numbers, routing information, transaction data
- Healthcare organizations: Medical license numbers, patient identifiers, HIPAA-protected information
- General enterprise: Email addresses, phone numbers, social security numbers
This contextual tuning required thorough research into the underlying model architectures and the development of custom configurations. We implemented sophisticated caching mechanisms and strategies for model reuse across processing cores.
The real breakthrough came from comprehensive performance optimization. We reduced processing time from potentially years to approximately three hours for gigabyte-scale data. For typical 10MB enterprise files, processing now completes within 15-20 minutes. This was achieved through intelligent parallelization strategies within Spark, model caching across worker nodes, and optimizing detection pipelines to handle the 500,000 chunks typically generated from large enterprise datasets.
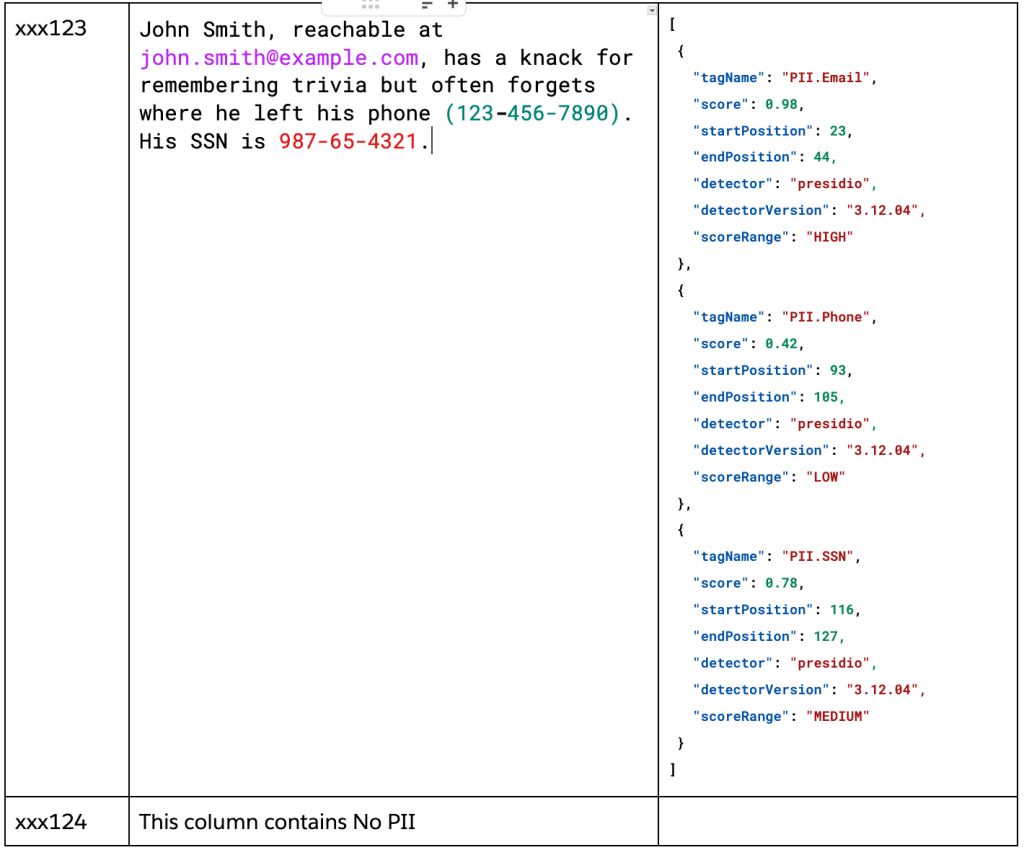
Result tag metadata.
How do you transition from structured database governance to unstructured PDF and document security architecture?
Moving from structured to unstructured governance presented significant architectural challenges, especially when it came to automated detection versus customer-defined schemas. In structured environments, customers clearly define data types and provide specific field content, making governance relatively straightforward with predefined rules. However, unstructured governance demands a different approach:
- Structured approach: Customers define email fields, phone number columns, and SSN databases.
- Unstructured approach: Automated file reading, ML-based detection, and confidence-level processing.
The main challenge in unstructured governance is the absence of customer input, as the system must automatically identify PII across various document formats.
To address this, we developed innovative methods for metadata mapping, storing detected tags alongside the original data. This approach enables more granular enforcement mechanisms but required meticulous design for data storage schemas and retrieval optimization.
The team implemented span-level policy frameworks that operate on specific portions of documents rather than entire files or database fields. This granular approach allows customers to write specific policies for string segments within unstructured content. We also created dedicated computing resources and caching mechanisms that scale independently of traditional governance systems, ensuring high performance even with large datasets.
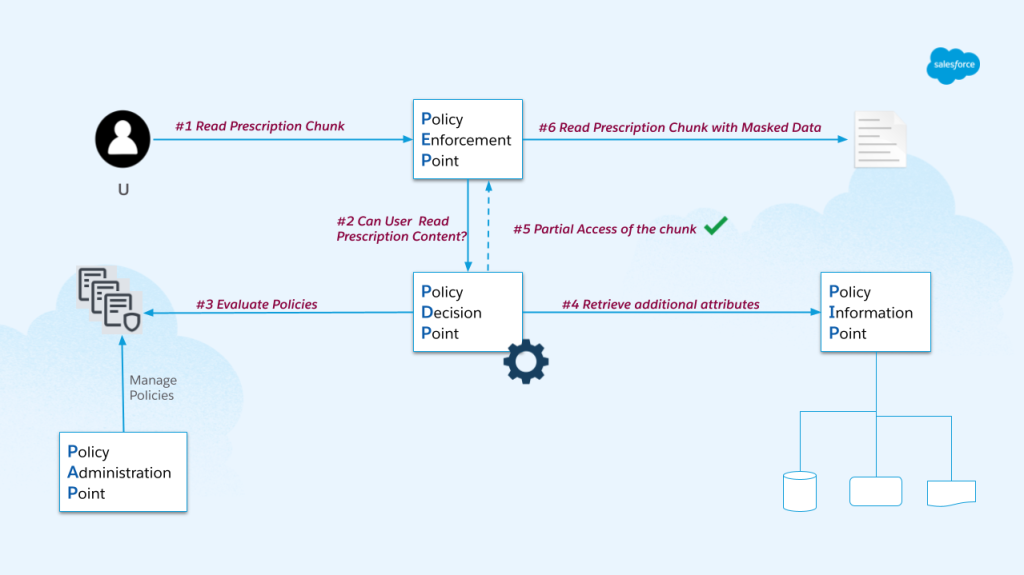
A look at the policy enforcement process.
What engineering challenges arise when building AI agent security gatekeepers for enterprise content management and preventing data leakage?
Building the security gatekeeper functionality involved tackling complex challenges around AI agent data access patterns and preventing information leakage through vector search and hybrid search operations. AI agents perform vector searches on unstructured data to find relevant content, which is then passed to large language models for processing. Without proper governance, AI agents could retrieve all data containing relevant keywords and pass comprehensive information sets to LLMs, leading to several issues:
- Vector search vulnerability: Agents could access all matching content, regardless of user permissions.
- LLM data exposure: Sensitive information could pass through external processing systems.
- User privilege escalation: Support agents might access executive-level confidential documents.
- Cross-organizational leakage: In multi-tenant environments, there’s a risk of data bleeding between customers.
To address these challenges, we developed sophisticated filtering mechanisms that analyze user permissions before data retrieval. This ensures that AI agents only access information appropriate for specific users. We collaborated with the Hyper team to integrate user-defined functions that read detected tags and apply masking based on governance layer responses.
Our implementation includes dynamic masking, where users see different versions of the same content based on their authorization levels. For example, a string containing email addresses is displayed fully for authorized users but shows masked versions with X characters for users without email access permissions. This approach prevents data leakage while maintaining the AI agent’s functionality for legitimate use cases.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.