In our “Engineering Energizers” Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Hari Priyanka Nunna, Director of Software Engineering for Data Cloud. Hari led her team in developing Data Cloud One, a distributed systems solution that allows enterprise customers to connect multiple Salesforce orgs to a single Data Cloud instance, significantly reducing redundant implementation work by centralizing metadata synchronization.
Discover how the team achieved strong transactional consistency using the outbox pattern architecture, prevented performance issues when connecting 50+ orgs through connection-level isolation, and managed the operational complexity of scaling from zero to over 150 enterprise orgs within just three months of general availability.
What is your team’s mission building Data Cloud One for enterprise multi-org Salesforce deployments?
Our mission is to provide a single, decentralized unified data layer that reduces management overhead and implementation costs for enterprise customers with multiple Salesforce deployments. Data Cloud One is designed for customers who have orgs across different regions and business units but don’t want to implement Data Cloud multiple times.
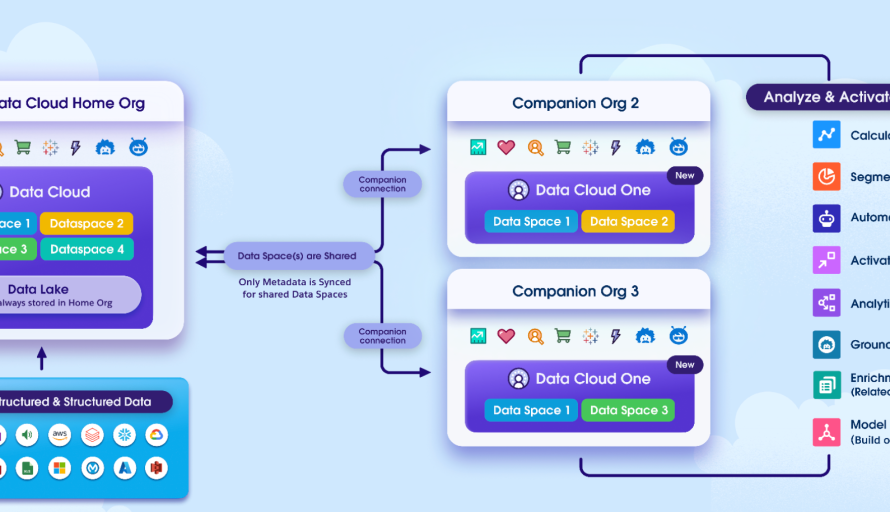
We built Data Cloud One as a hub-and-spoke distributed system. The Data Cloud home org acts as the unified data layer for an entire cluster of orgs, allowing multiple Salesforce CRM instances to connect as companion orgs. These companion orgs leverage the same unification layer built on top of Data Cloud, while still accessing insights built locally or brought in from the home org. This architecture ensures that data is seamlessly integrated and accessible across all connected orgs.
Since going general availability (GA) in October 2024, the team has seen significant adoption from enterprise customers with multi-region, multi-org architectures that require centralized implementation approaches. Within just nine months, the total number of companion connections has grown from zero to over 850 across our enterprise customer base.
Data Cloud One breaks traditional Salesforce org boundaries by moving metadata from Data Cloud to all connected instances. This fundamentally simplifies how customers solve their use cases across business units, streamlining their operations and enhancing their ability to leverage data-driven insights.
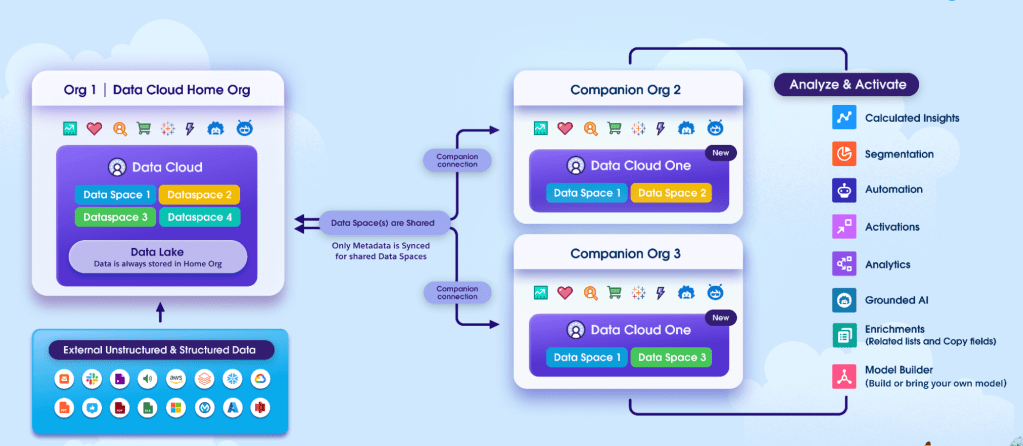
Figure: How Data Cloud One works
What distributed systems challenges did your team face synchronizing metadata across multiple Salesforce orgs — and how did outbox pattern architecture solve strong transactional consistency?
The primary challenge we faced was achieving strong transactional consistency, rather than just eventual consistency. While many distributed systems focus on eventual consistency, our requirement was more critical: any transaction that occurred on the primary org had to be exactly the same transaction replayed on the companion org, using all-or-none semantics. This level of transactional consistency is essential, even when replication can be eventual.
To solve this, we implemented the outbox pattern, which captures every transaction in its entirety. Each transaction is recorded as an atomic unit in a staging table before it is transmitted to the connected instance. When conflicts arise, such as metadata dependencies or schema mismatches, the replication pipeline halts at the transaction boundary. Customers can see details conflicts that clearly show which metadata is in conflict and why. Only after these conflicts are manually resolved does the pipeline resume, ensuring that companion orgs receive complete and validated transactions, rather than corrupted partial states. This metadata-driven approach allows the companion org to be in a working state at any point of time.
Scalability challenges, which are common in distributed systems, were not an issue for us because we operate within org boundaries where connections function independently. Regardless of the number of connections, scalability remains manageable since each org operates independently at the org level within the replication process. This design ensures that the system can handle a large number of connections without performance degradation.
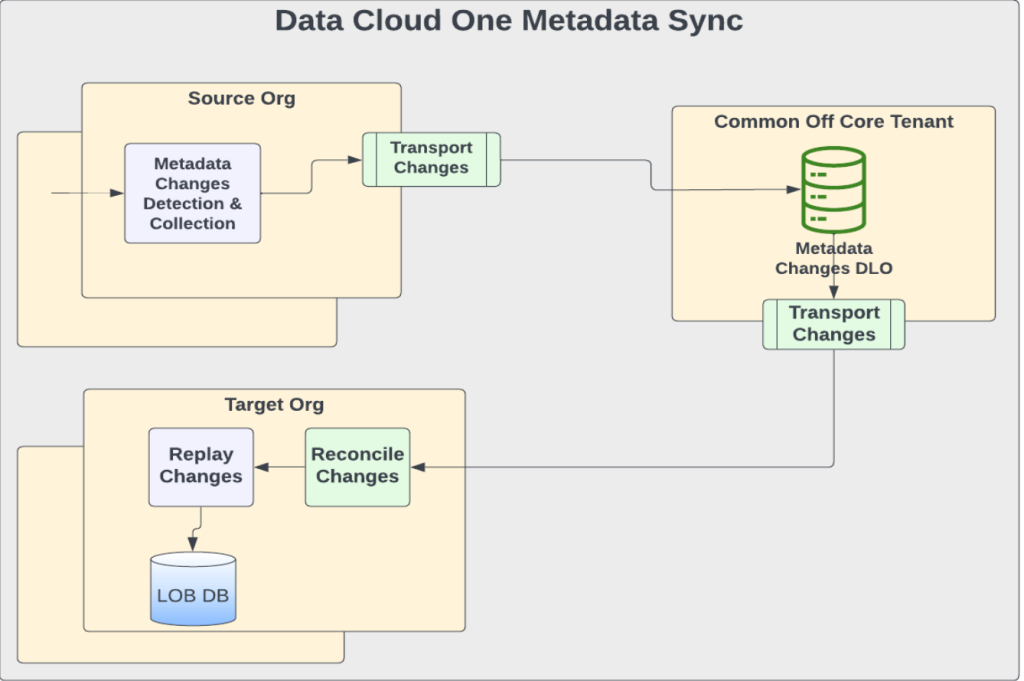
Metadata Sync and Replay Pipeline from Home (Source) to Companion (Target) Org
How does Data Cloud One handle performance and latency at scale when enterprise customers connect 50+ multi-region Salesforce orgs?
Performance and latency challenges can be significant, especially in distributed systems. However, in Data Cloud One, these challenges operate at the individual connection level rather than the aggregate cluster level. This means that even if a primary org connects to dozens of companions, latency issues remain isolated to single connections only. For example, if a Data Cloud home org in APAC has one companion in the US and another in APAC, cross-region latency affects only the US connection and does not impact the APAC connection.
We designed Data Cloud One to ensure that all instances work independently. The hub, connected to multiple satellites, does not affect the performance or latency of any companion org. Each replication process occurs on its own org instance, ensuring that any cross-regional connections or busy instances face their own challenges without impacting other connections.
Before launching Data Cloud One, our team conducted extensive performance testing. We connected companions across different regions and core versions to ensure that replication worked seamlessly. Today, we have customers with home orgs connected to up to 35 companion orgs, all operating smoothly without any performance degradation.
However, the solution does have some architectural constraints. Customers with strict data residency requirements may have to use multiple regional clusters of Data Cloud One, as the unified data layer is centralized in a single region. Governance remains at the org level through data space sharing and local policy configuration. This approach enables multi-org governance strategies while still leveraging the benefits of centralized data storage.
What operational and monitoring challenges emerged scaling Data Cloud One from zero to 150+ enterprise orgs within three months of GA?
Within three months of the GA launch, over 150 enterprise orgs requested the feature, creating immediate operational pressure for our team. Managing customers with up to 35 companion connections on single home org was a significant challenge. The complexity arose from understanding the diverse org structures and cluster configurations when issues emerged. Each customer implements very different org configurations, making it essential to grasp their unique cluster architecture and sandbox setups.
We faced significant monitoring and observability challenges right after the GA launch. The team had to develop custom dashboards to provide clear views of the home-to-companion relationships and the correct approaches for examining Splunk logs. Understanding the right monitoring state to quickly resolve issues required substantial tooling development.
Connection and disconnection workflows also created operational friction. While achieving the initial replication state was relatively straightforward, the cleanup process after disconnection proved difficult. Once the metadata is referenced locally, detangling it and disconnecting the org to it’s original state as if it was never connected is the hard part. The team spent nearly three to four months resolving root causes and hardening the feature to handle these challenges, which provided the necessary breathing room to focus on enhancements.
Additionally, the team built an extensive functional test framework for multi-org context switching, a unique automation approach within Data Cloud. This framework requires specific tests whenever new entities or tables are onboarded to the sync layer, ensuring the pipeline remains robust and doesn’t break without manual verification. This automated testing capability became essential because traditional Data Cloud testing frameworks operate within single org boundaries, but we needed to switch between two different org contexts during integration tests. This hardening period transformed the solution from one with significant initial issues to one that operates seamlessly.
How does Data Cloud One reduce enterprise Salesforce implementation time for multi-org deployments?
Before Data Cloud One, enterprise customers faced a significant time investment, often spending weeks to months setting up customized solutions for each connected org. Each customer had to develop their own methods, such as using named credentials and writing custom Apex-driven queries and code to build insights from unified data in Data Cloud. These custom solutions often led to inconsistencies, as certain Data Cloud features might not function properly on companion orgs due to varying customization capabilities.
With the launch of Data Cloud One, the process has been streamlined dramatically. The point-and-click nature of the platform makes it easy for customers to complete setup steps and connect their orgs immediately. All the features and insights built on the home org are automatically available on companion orgs, ready for immediate use. For more complex model setups, deployment now takes just a few days, a stark contrast to the weeks or months required previously. Most importantly, the setup is a one-time process, no matter how many orgs are connected, eliminating the need for reimplementation for each additional org.
The efficiency gains are reflected in the adoption metrics. Paid connections surged from 45 in May to 75 in September, representing an 80% increase in just one quarter. Every connection beyond the third for enterprise customers is now a paid connection, underscoring the value customers find in the streamlined, redundant-free multi-org implementation process.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.