Introduction
We’ve written before about how we built an engagement activity platform to automatically capture and store user engagement activities and about the steps we took to greatly improve our pipeline stability by eliminating Conflicting Commits errors and maintaining data integrity. The type of activities we store are customer activities such as viewing a presentation or webinar or clicking on an email. The important thing for us to note is that an engagement is mutable. For example, a lead L could become a contact C with a new ID, and all engagements that belong L should be updated with the new ID of C. Therefore, our data lake of engagements is a mutable one.
Pipeline Design
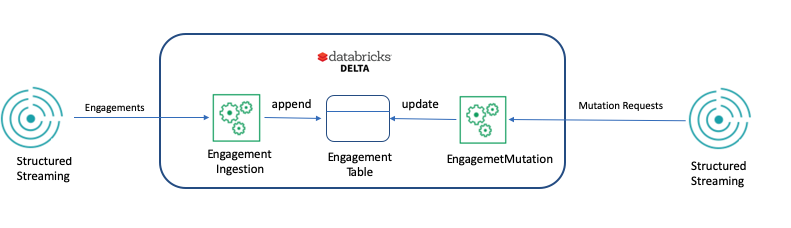
The discussion in this blog post will focus on two pipelines: one is engagement ingestion, and the other is engagement mutation. Engagement Ingestion is a batch job to ingest Engagement records from Kafka and store them to Engagement Table. Engagement Mutation is the other batch job to handle mutation requests. One mutation request could lead to changes to multiple engagements.
Engagement Table Schema
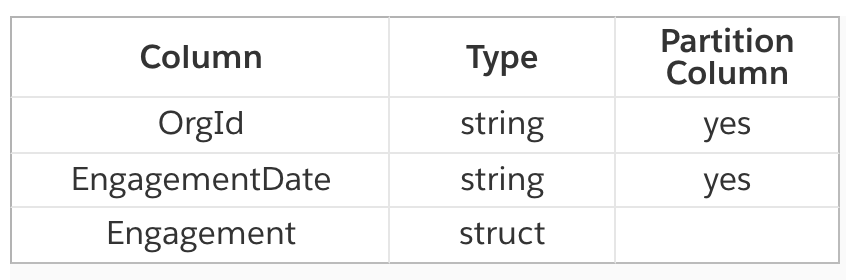
All engagements belong to an organization, which is indicated in the column “OrgId” in the table below. Each engagement has a time and is rounded into a date indicated in the column “EngaementDate”. “Engagement” column is a struct type containing the detailed fields. The table is partitioned by OrgId and EngagementDate, which means data files are in an S3 key of {orgId}/{EngagementDate}/{file_name}.parquet
Mutation Request Schema
OrgId and EngagementDate indicate what partitions to change. MutationOperation could be DELETE (delete engagement) or CONVERT (e.g. change all engagements of a contact to a lead ). A mutation request could be translated to a delete, update, or insert operation to multiple engagements in the Engagement table.

Goal
Our goal is to handle 10 million mutation requests on the Engagement table within an hour.
First Iteration: Partition Pruning
In the first iteration, the design of Engagement table inherits the thinking of building a data lake on a file system (S3). The design relies on file-based partitioning by having one subdirectory for every distinct value of the partition column. In our case, Engagement table is partitioned by OrgId and EngagementDate. Queries on the table operate on relevant partitions by the partitioning columns, namely partitioning pruning.
With this design, our mutation Spark job took more than 8 hours to handle 200k mutations in a batch, which is far from our expectation. We determined that the poor performance was due to too many small files. Thanks to DeltaLog DataFrame, we were able to examine the details of the data file layout of Engagement table.
First, we queried the number of files and their sizes within each partition and found out that up to 200 files could be written within one partition. For example, this partition has 175 files:

and the size of those files is small: around 7KB
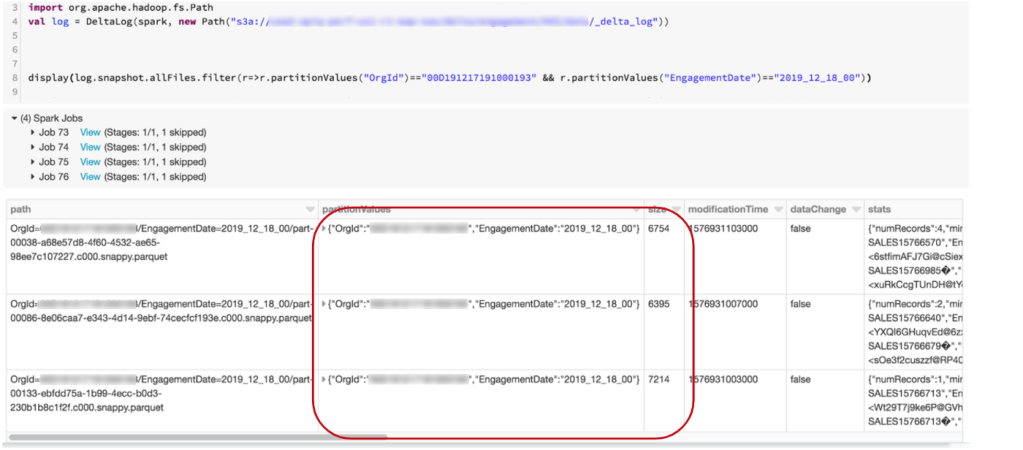
In addition, the Engagement table contains more than 4 millions files:

We observed that the mutation job took a long time listing files and writing them back. The driver node also failed with the error of “total size of serialized results is bigger than spark.driver.maxResultSize.” This is because the total size of the listed file metadata sent from executors to driver exceeds the value of spark.driver.maxResultSize.
We took the following actions to resolve the too-many-files issue.
Run OPTIMIZE command on EngagementTable
The OPTIMIZE command compacts small files in the same partition into one file. The compacted file size is decided by the Spark config of maxFileSize (1G by default). After we ran the OPTIMIZE command on Engagement table, the number of files is reduced greatly, from about 4 million to 135K.

Apply Optimize Write and Auto Compaction to Engagement Ingestion and EngagementMutation Job
These two options help to reduce the number of files to be written during write operations. We enable the two in both ingestion and mutation jobs by setting the two configs to true:
spark.databricks.delta.autoOptimize.optimizeWrite true
spark.databricks.delta.optimizeWrite.enabled true
We observe that Optimize Write effectively reduces the number of files written per partition and that Auto Compaction further compacts files if there are multiples by performing a light-weight OPTIMIZE command with maxFileSize of 128MB.
Second Iteration: I/O Pruning : Data Skipping and Z-Order
OPTIMIZE, OptimizeWrite and AutoCompaction alleviated mutation job performance issues. However, as we ingest more data into Engagement table, the small files issue reappeared and the job failed again. We performed a bucket query on the file size distribution with DeltaLog DataFrame:

As you may see, the file number bumps back to 3M+ and the size of most is under 500K. To understand the skewed partition file size behavior, we retrospected our traffic model.
According to the EAP Perf Traffic Model, the number of engagements per org per day ranges from 2,814 (org size S) to 1,968,764 (org size XXL). The size of each engagement is 150 bytes. The total file size of the engagements per org per day will be 422KB to 295MB. The model also indicates that 90% of the orgs are small, which means 90% of the partitions will be less than 500kb.
The characteristics of our traffic model determines that the partition file size is skewed in nature even in the most optimal condition in which one partition has one file. We had to come up with a sustainable model to have the data of Engagement table evenly distributed across reasonably-sized files in order to achieve our performance goal. Sticking to the directory-based partitioning strategy would not help us make this goal. We had to rethink our partition strategy. We decided to remove EngagementDate from the partitioning column list and use it as the Z-Order column to leverage the Data Skipping feature of I/O pruning provided by Delta Lake. The new partition strategy for Engagement table is to partition by OrgId and Z-Order by EngagementDate.
Data Skipping and Z-Order
Delta Lake automatically maintains the min and max value for up to 32 fields in delta table and stores those values as part of the metadata. By leveraging min-max ranges, Delta Lake is able to skip the files that are out of the range of the querying field values (Data Skipping). In order to make it effective, data can be clustered by Z-Order columns so that min-max ranges are narrow and, ideally, non-overlapping. To cluster data, run OPTIMIZE command with Z-Order columns.
OPTIMIZE ENGAGEMENT_DATA ZORDER BY (EngagementDate)})
We can see a few differences in the metadata of Engagement table with the new partition strategy: first, the partitionValues column contains OrgId only; second, the tags column indicates that the z-order column is EngagementDate; third, each file maintains an non-overlapped range of engagement dates. Here is what will happen to a query: Delta Lake first filters by orgId to locate the target directory (partition pruning), and then skips files by EngagementDate range (I/O pruning).
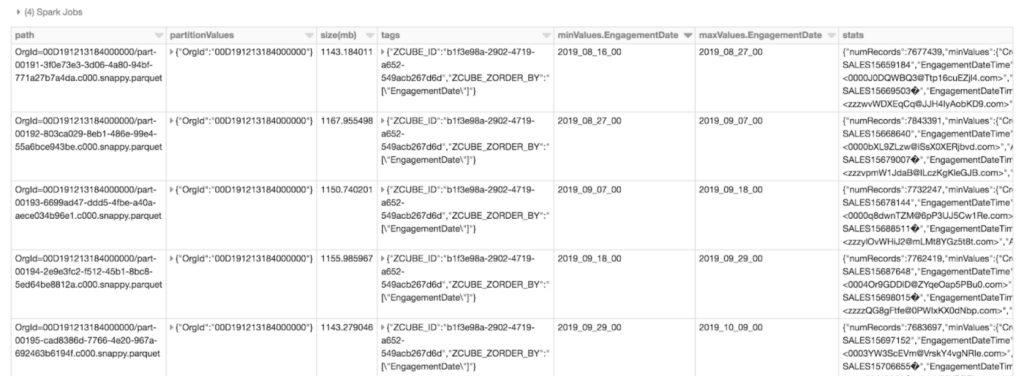
The Comparison between Two Partition Schemes
Partition by Org and Date
With this partition scheme, files are written to a partition directory of org/date, which could lead to the following issues:
- Data file size distribution could be skewed. Small orgs with less engagement per day would have small files. And many small files could be created if small orgs are the majority.
- Once the partition columns are decided, it it impossible to change file sizes for optimizations.
Partition by Org and Z-Order by Date
With this partition scheme, files are written to a partition directory of org, which is a larger granularity. Delta Lake divides files by the configuration of maxFileSize. This partition scheme has the following benefits:
- With a larger granularity, small files per org/date are merged into a bigger one which helps reduce the number of small files.
- We can tune file size by setting the configuration “maxFileSize.”
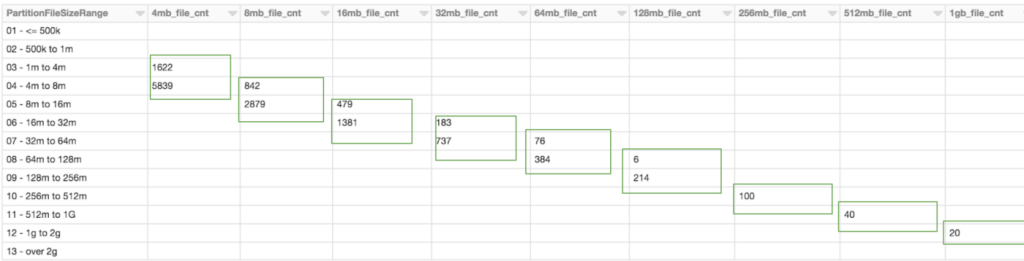
The query below indicates how well the file size could be aligned to the configuration. The first column is file size bucket. The head is the configuration value for the delta table. Each table holds the same set of data, to which the OPTIMIZE command has been applied. The numbers in the green boxes are the file count in the bucket of that table.
Performance Benchmarking
With the new partition schema, the next question is what the appropriate value for file size (controlled by maxFileSize) will be. (The default is 1GB). In order to find the answer, we conducted a performance benchmarking.
Baseline Dataset
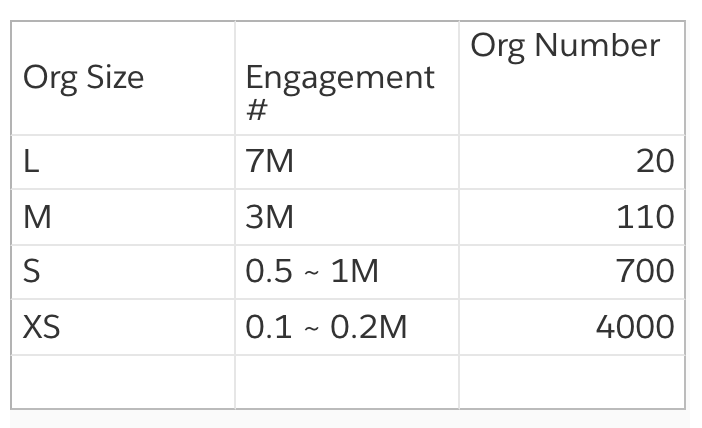
We created the baseline dataset: 4830 orgs are created, 1.5 billion engagements, 5.4 million mutation requests applied, resulting in 1.3 billion engagements being mutated. The Org/Engagement distribution is aligned with the traffic model in the table below:
Benchmarking Design
We ran 14 rounds of EngagementMutation job for each file size: 4MB, 8MB, 16MB, 32MB, 64MB, 128MB, 256MB, 512MB, 1GB. On each run, we measured the mutation time (update/delete) and put it the matrix below. The number is in minute.

For each run, we ensured the table data file layout was in the same initial state by running the OPTIMIZE command

Result Analysis
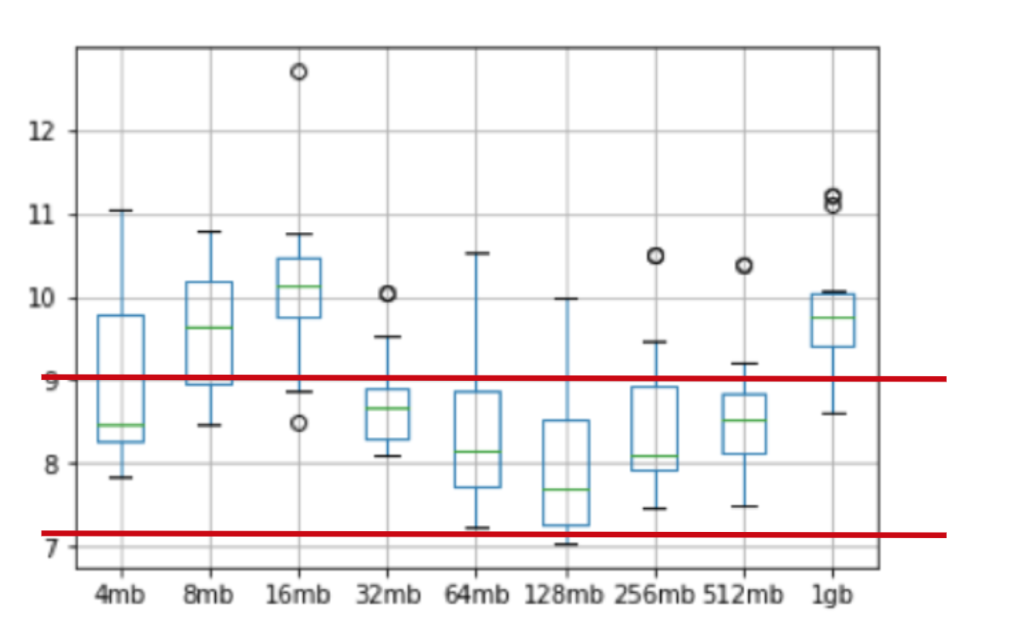
Based on the box-plot below derived from the matrix, we can see the optimal value for delta.optimize.maxFileSize is 64,128 or 256mb.
Final Result
In addition to the partition schema change, we built a notebook to monitor the health of the data file layout of Engagement table, and we added another job to perform the OPTIMIZE command on the table every day. The final testing result is that the EngagmentMutation job can handle 25 million update/delete requests within 15 minutes, far outperforming our goal of handling 10 million mutations within an hour.
Read more posts about our Delta Lake implementation: