In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we spotlight Ishween Kaur, Senior Software Engineer on the Agentforce Agentic Reasoning team. As Agentforce expanded globally, Ishween’s team faced the challenge of delivering consistent multilingual AI experiences across 34 fully supported and 26 (Beta) supported languages.
Explore how the team scaled more than 600,000 daily language detections and engineered deterministic AI localization controls after discovering that even approved language lists weren’t enough to stop LLMs from choosing the wrong language.
What is your team’s mission in delivering multilingual AI experiences across Agentforce?
The mission is to make AI localization a first-class capability of the Agentforce reasoning platform, so customers can deliver AI experiences in their users’ native languages without sacrificing quality, consistency, or trust. Because the team owns the reasoning layer that enables agents to think, plan, and act, localization has to be embedded directly into orchestration, knowledge retrieval, action execution, and response generation.
At first glance, multilingual AI seems straightforward since modern LLMs already support dozens of languages. The reality is much harder. Even when approved language options were supplied, models could still generate responses in the wrong language. Enterprise customers weren’t asking the team to teach models new languages. They were asking for guaranteed, consistent language behavior across planners, retrieval systems, actions, and responses assembled dynamically at runtime.
Enterprise customers don’t simply need responses in different languages. They need planner decisions, retrieval results, action outputs, loading messages, and error responses to stay aligned with the same language policy throughout an entire interaction. A single component falling back to English can break trust even when the model itself performs correctly.
The challenge is not generating multilingual responses, rather, it is enforcing deterministic language behavior across distributed systems built on probabilistic models.
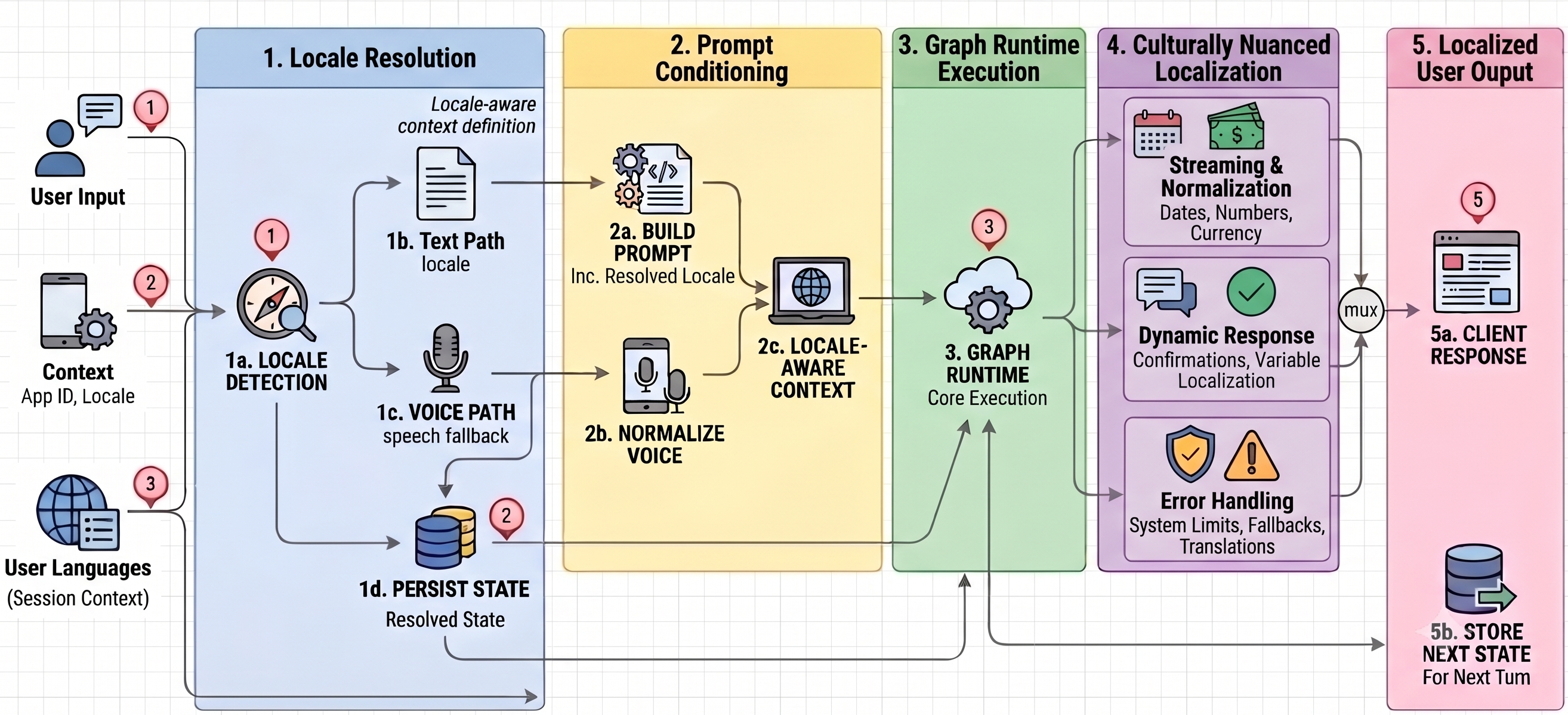
End-to-end architecture of a culturally nuanced localization pipeline.
When customers began requesting multilingual Agentforce experiences, why wasn’t translating responses enough?
Traditional localization assumes content exists before users see it. AI systems break that model entirely. Every Agentforce response is assembled dynamically from user input, conversation history, retrieved knowledge, planner decisions, and action outputs, with multiple systems contributing to a single response. Each one has to behave consistently in the user’s language, which creates a fundamentally different problem than translating static content.
The team also discovered that linguistic correctness doesn’t automatically create trust. A response can be grammatically correct and still feel unnatural because local expectations around tone, structure, and communication style vary significantly across regions.
The challenge became orchestration rather than translation. The team wasn’t localizing content. They were localizing systems.
What latency and reliability constraints shaped the architecture of your language-detection system?
Language detection had to become effectively invisible. In conversational systems, latency is experienced as hesitation, and hesitation erodes trust. After evaluating multiple approaches, including LLM-based inference, the team landed on Lingua, a language-detection library optimized for short conversational text and built on Rust bindings. This made it possible to identify languages at approximately 3–4 milliseconds of p95 latency without the overhead of an additional model invocation.
Detection alone was not enough. The team introduced Localization Context, established once and then shared across planners, actions, retrieval systems, and downstream services. Rather than having each component independently infer language, every participating system consumes the same source of truth, ensuring consistent language state throughout the entire workflow.
The goal wasn’t optimizing for detection accuracy alone. It was producing a language signal reliable enough to coordinate an entire distributed workflow.
Why did Salesforce decide it couldn’t trust the LLM to decide what language it should speak?
Early experiments exposed a critical failure mode. Even when prompts explicitly specified a target language and provided approved language options, the model could still generate output in a different language. In some cases, it selected a language outside the approved set entirely. The problem wasn’t translation quality. The problem was control.
When language selection is delegated entirely to a probabilistic system, it becomes difficult to guarantee consistent behavior, explain decisions, or enforce customer policies. Responses can drift between languages, and enterprise customers lose the ability to audit why a particular language was chosen. Language selection also affects far more than the final response. For example, it influences retrieval, action execution, loading messages, and downstream workflows. A mistake at the start of the pipeline propagates through every system that follows.
Rather than allowing the model to determine language autonomously, the team introduced a deterministic detection layer that establishes Localization Context before reasoning begins. The deterministic layer defines the language. The model generates within it.
What architectural challenges emerged when localization had to remain consistent across distributed agent workflows?
While our initial design delegated localization to individual actions and services, rapid prototyping and early iterations quickly revealed that this approach would not scale. At Salesforce’s massive platform scale, a decentralized model would introduce severe fragmentation, where different teams would inevitably implement conflicting fallback strategies, localization logic, and language assumptions. This siloed architecture would ultimately break consistency and deliver a disjointed user experience.
This became especially visible in responses. A single Agentforce response often combines outputs from multiple actions running in parallel. If one action localized correctly while another fell back to English, users could receive a mixed-language response assembled from otherwise functioning components.
The problem got harder when users switched languages mid-conversation. Detecting the change was relatively straightforward. Maintaining consistency across planners, retrieval systems, action pipelines, and localized outputs was not. Localization Context could no longer function as static configuration, rather, it had to become live shared state capable of evolving as users changed languages and workflows continued executing.
To solve this, the team centralized localization within the reasoning platform. The Planner now establishes and updates Localization Context, and downstream systems consume it through a shared contract.
What challenges remain as Agentforce expands beyond its current language support?
The most difficult challenges ahead are increasingly tied to evaluation rather than implementation. Every new foundation model has to demonstrate acceptable behavior across all supported languages while maintaining consistency, cultural appropriateness, and policy compliance.
Complexity continues to surface in places that seem straightforward at first. Chinese, for example, appears as a single language in many benchmarks, but supporting Simplified and Traditional Chinese requires separate evaluation because differences in vocabulary and convention matter significantly to native speakers.
One of the most promising opportunities ahead is localizing the reasoning context itself. There is a meaningful difference between instructing a model to respond in French and providing a reasoning environment that already operates in French. That distinction represents one of the next major opportunities for improving multilingual AI quality at enterprise scale.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.