By Tuhin Kanti Sharma and Chirag Ramesh Hegde.
If you’ve built an AI agent that works perfectly in demos but becomes unpredictable in production, you’ve probably already discovered that reliability is much harder than capability.
We ran into that problem while trying to build an agent to automate capacity optimization worth millions of dollars in potential cloud savings. Cloud economics data showed that 86% of containers across our fleet were running at less than 20% of their requested CPU, leaving roughly half of our provisioned capacity sitting idle. Recovering those savings should have been straightforward, except for one problem: nobody could reliably determine where many of the CPU settings actually came from.
Hyperforce has evolved over the years, which has led to scattered resource definitions across Terraform, Helm and Structured Configuration systems. These are further complicated by environment and region-specific overrides. The same service could contain multiple CPU values with different precedence rules, and the configuration that appeared to control production behavior was often not the one actually being used in production.
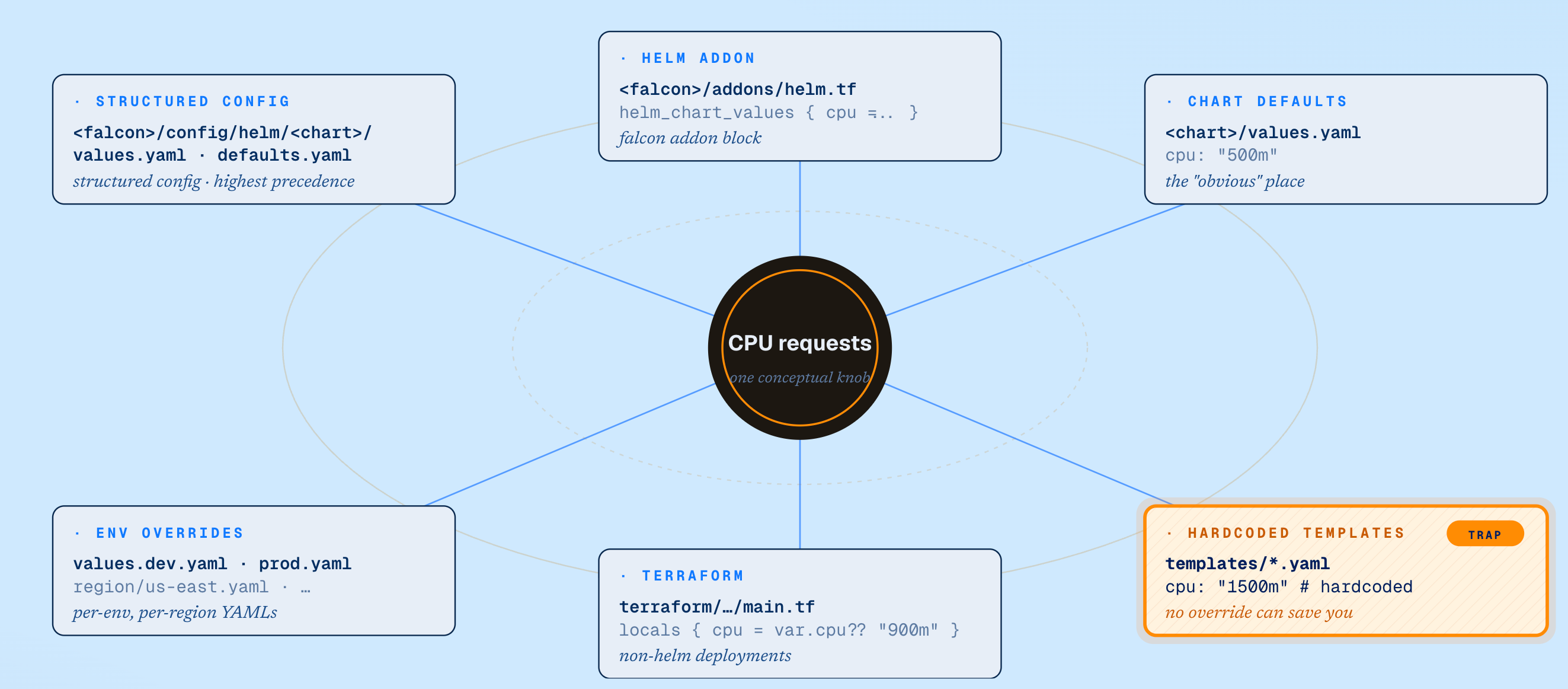
There is not a single source of truth for CPU configuration.
We wanted an AI agent to safely generate infrastructure changes across thousands of production services, but the absence of a single source of truth made it difficult for the agent to reason effectively. CPU settings could be defined in multiple locations, multiple values could disagree, and even experienced engineers often needed significant investigation to figure out which configuration actually controlled production behavior. We weren’t asking the agent to automate a process humans had already mastered. We were asking it to solve a problem humans routinely struggled to solve themselves. And we weren’t just asking it to answer a question. We were asking it to generate production infrastructure changes based on the answer it discovered.
Like many teams building agentic systems, we started with prompts. Then we tried larger prompts. Then we tried multiple agents. None of those approaches solved the reliability problem. The breakthrough came when we stopped focusing on the model and started engineering the systems around it.
Why AI Agents Become Unreliable in Production
Our first implementation gave the model repository access, utilization data, and instructions describing how CPU configurations should be discovered and modified. The approach worked well on simple repositories but struggled as repository complexity increased.
Different deployment frameworks, override mechanisms, and configuration hierarchies required increasingly detailed instructions. In one repository, the CPU value defined in a Helm chart appeared to be the correct setting to modify. Further investigation revealed that an environment-specific override ultimately controlled production behavior. In another repository, the apparent source of truth was superseded by a Structured Configuration layer several levels deeper in the deployment stack. Each new discovery required additional instructions, examples, and exceptions.
The prompt gradually evolved into a collection of repository-specific logic that resembled software written in English. As the agent architecture became more complex, the system became increasingly difficult to reason about and maintain. Although the prompt grew substantially more complex, reliability failed to improve in any meaningful way. The agent still struggled with unfamiliar repository structures, and every new exception made the system harder to maintain.
If you’ve ever responded to agent failures by continuously adding instructions, you’ve probably experienced the same pattern. The prompt grows, but the underlying reliability problem remains.
Why Multi-Agent Architectures Don’t Automatically Improve Reliability
Multi-agent architectures appeared to offer a solution. We divided responsibilities across agents handling repository discovery, optimization planning, pull request generation, and verification.
The architecture looked elegant, but the same repository, utilization data, and optimization objective could still produce different outputs across executions. Sometimes the optimization plan changed. Sometimes the generated pull request changed. We upgraded models, refined prompts, and introduced reviewer agents, yet the inconsistency remained.
Eventually, it became clear that we were trying to make language models behave deterministically. That insight led to a more important question: were we asking the model to solve problems that should never have been assigned to a model in the first place?
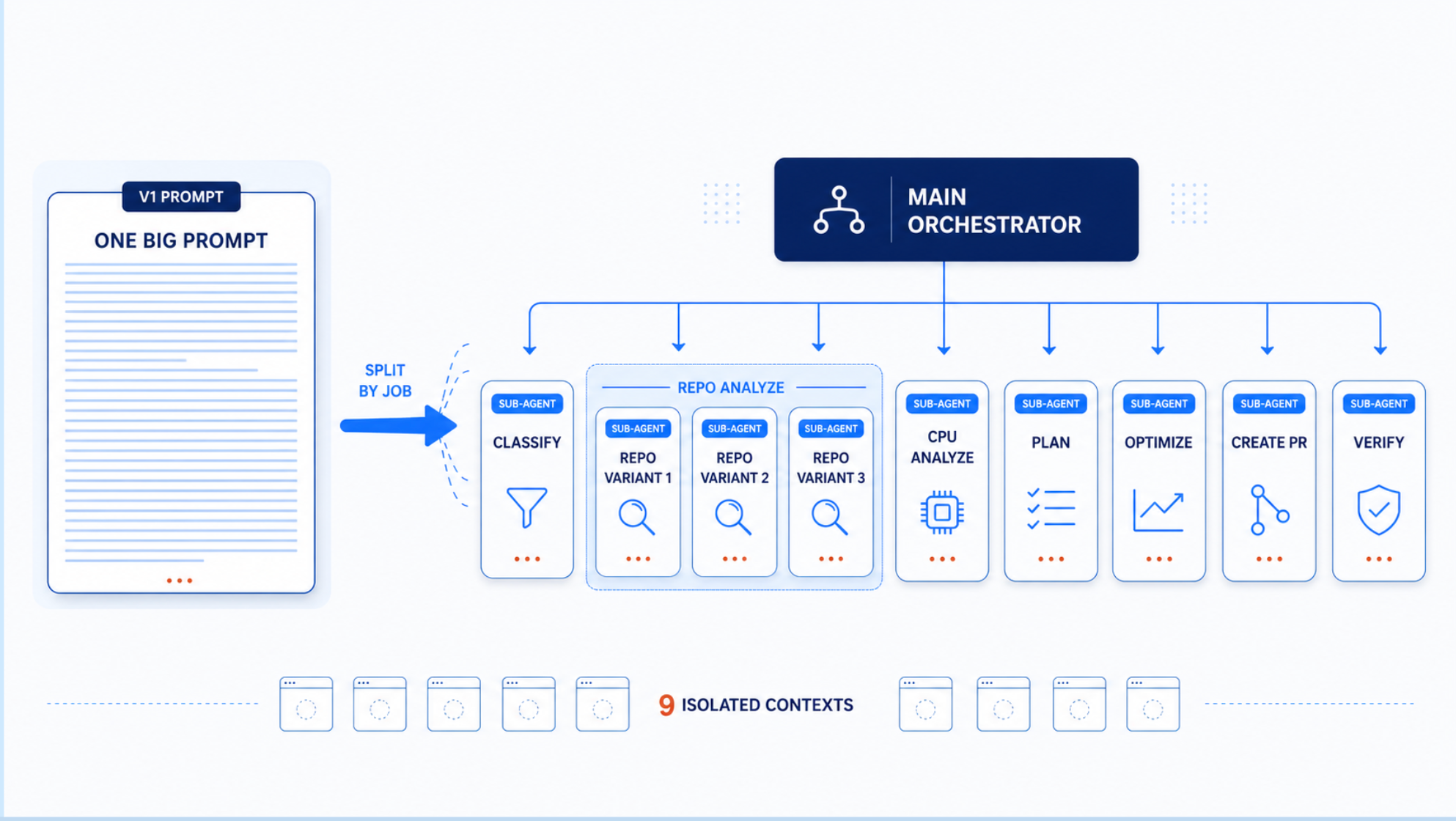
Isolated contexts did not help improve agent reliability.
The Architecture Shift That Made Our AI Agent Reliable
The breakthrough came when we stopped treating the workflow as a single AI problem and started treating it as an architecture problem. Some tasks required reasoning and interpretation. Discovering repository structure, understanding deployment patterns, and identifying configuration precedence all involved ambiguity. Other tasks required optimization, arithmetic, scheduling, and constraint solving, and those activities needed to produce the same answer every time given the same input.
Our architecture had assumed both categories belonged inside the model. Once we separated them, reliability improved dramatically. That insight became the foundation for five engineering patterns that transformed an unreliable agent into a production system.
Pattern #1: Separate Reasoning from Computation
One of the most common mistakes in AI agent architecture is treating every problem as a language model problem. Reasoning tasks involve ambiguity, which makes them a natural fit for LLMs, but computation tasks require deterministic outputs and are better handled by software built for that purpose. Conflating the two is where a lot of agent systems go wrong.
If your workflow contains both reasoning and deterministic computation, separating those responsibilities can dramatically improve reliability. In our case, an agent performed repository discovery and generated structured output describing the configuration landscape. That output was passed to a deterministic optimization engine, and the resulting recommendations were returned to another agent responsible for applying changes and generating pull requests.
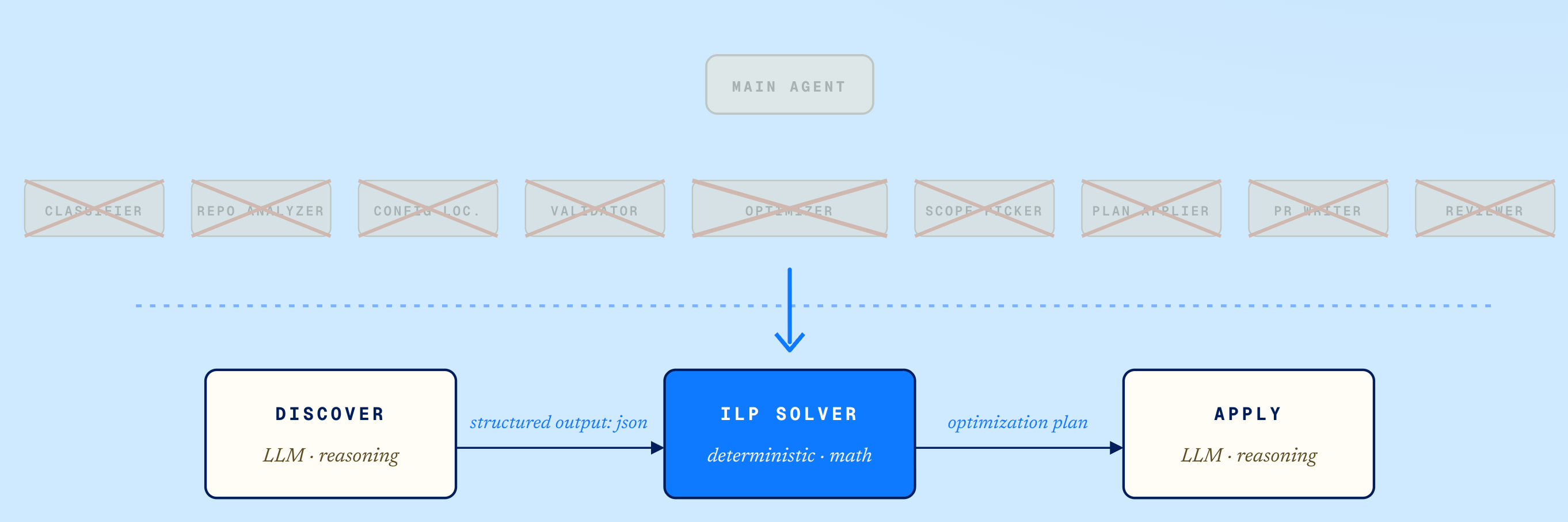
Reasoning → Deterministic Computation → Reasoning.
A useful rule came out of that experience: if the logic can be expressed as a deterministic algorithm and validated with tests, it probably shouldn’t live inside the model.
Pattern #2: Use Deterministic Systems for Deterministic Problems
Once reasoning and computation were separated, another realization became obvious: the optimization problem itself was not an AI problem. If your agent is performing optimization, scheduling, resource allocation, or arithmetic, it’s worth asking whether a deterministic system can handle that work more reliably than an LLM. Our challenge involved balancing competing objectives, reducing wasted CPU capacity while minimizing configuration complexity. Rather than asking an LLM to reason through those tradeoffs repeatedly, we adopted Integer Linear Programming. The solver treated configuration layers as decision variables and optimized for multiple goals simultaneously.
The most valuable characteristic of the solver was consistency. The same input always produced the same answer. When a proven deterministic solution already exists, combining AI with traditional algorithms often produces better results than asking the model to handle the entire workflow on its own.
Pattern #3: Treat Context Management as a Reliability Problem
Many agent failures start with another instruction, another example, or another exception added to the prompt. Over time, the context window becomes a storage location for every lesson the system has ever learned.
The problem is that context is not free. Every instruction, example, tool description, and piece of historical information competes for the model’s attention, and at some point that competition starts working against you.
If your first instinct when something breaks is to add more to the context window, it’s worth asking whether reducing context might actually improve reliability. In our experience, it did. Skills allowed instructions to remain dormant until they were needed. Sub-agents isolated specialized work from the parent agent’s context. Skills improve instruction relevance. Sub-agents improve context isolation.
For reliable agentic systems, context management is not just a prompt design concern. It is a core architectural concern that directly affects consistency and predictability.
Pattern #4: Build AI Agent Verification into the Architecture
Language models can sound convincing even when they are wrong, which makes verification one of the most important components of any production agent system.
If you’re relying primarily on reviewer agents to catch mistakes, it’s worth remembering that explanations are not evidence. Our first instinct was to add reviewer agents, and while that occasionally helped identify mistakes, it didn’t provide the reliability guarantees we needed for production infrastructure changes.
Instead, we built a verification hierarchy around deterministic checks. Builds, compilers, linters, validation scripts, and CI pipelines evaluate actual system behavior rather than model confidence. That distinction matters. An agent that explains its reasoning correctly but produces a broken output has still failed.
The key lesson was simple: an agent should be considered successful only when objective validation confirms that it is correct.
Pattern #5: Improve the Harness, Not Just the Prompt
Most teams respond to agent failures by writing better prompts. If you’re facing recurring reliability issues, it’s worth examining the surrounding system before rewriting the prompt.
We found it more useful to ask a different question: what change would make this mistake harder to repeat? That question shifts attention away from the model and toward the harness around it. Context management, verification, tool execution, sandboxing, observability, state management, and control loops collectively form the system surrounding the model, and that system is often where the real problems live.
Many recurring reliability issues are actually harness problems. Arithmetic mistakes often point to missing deterministic computation. Context confusion frequently points to poor context isolation. Repeated implementation errors may reveal insufficient validation.
Key Takeaways for Building Reliable AI Agents
- Separate reasoning from computation. Language models are built for ambiguity. Deterministic systems are built for precision. Use each accordingly.
- When a task requires a consistent answer, use a deterministic system to produce it.
- Treat context management as an architectural decision, not a prompt design afterthought.
- Validate agent outputs with objective checks, not reviewer agents or model confidence.
- When something breaks, improve the harness before touching the prompt.
Build Agents Like Software Systems
The biggest lesson from this project was that most agent failures are not model failures. They are architecture failures caused by asking language models to perform work that deterministic systems handle better.
The largest improvements in reliability came from engineering decisions surrounding the model rather than changes to the model itself. Separating reasoning from computation, introducing deterministic optimization, managing context carefully, validating with objective evidence, and continuously improving the harness produced far greater gains than any prompt refinement we attempted.
Building reliable AI agents requires the same engineering disciplines used to build reliable distributed systems, infrastructure platforms, and production software. Reliability emerges from architecture, validation, observability, and deterministic execution, not from prompt engineering alone.
The next time your agent fails, resist the urge to add another instruction. Ask instead what change to the system would make that failure harder to repeat. More often than not, the answer lies in the architecture, not the prompt.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.